Downloaded 32 times





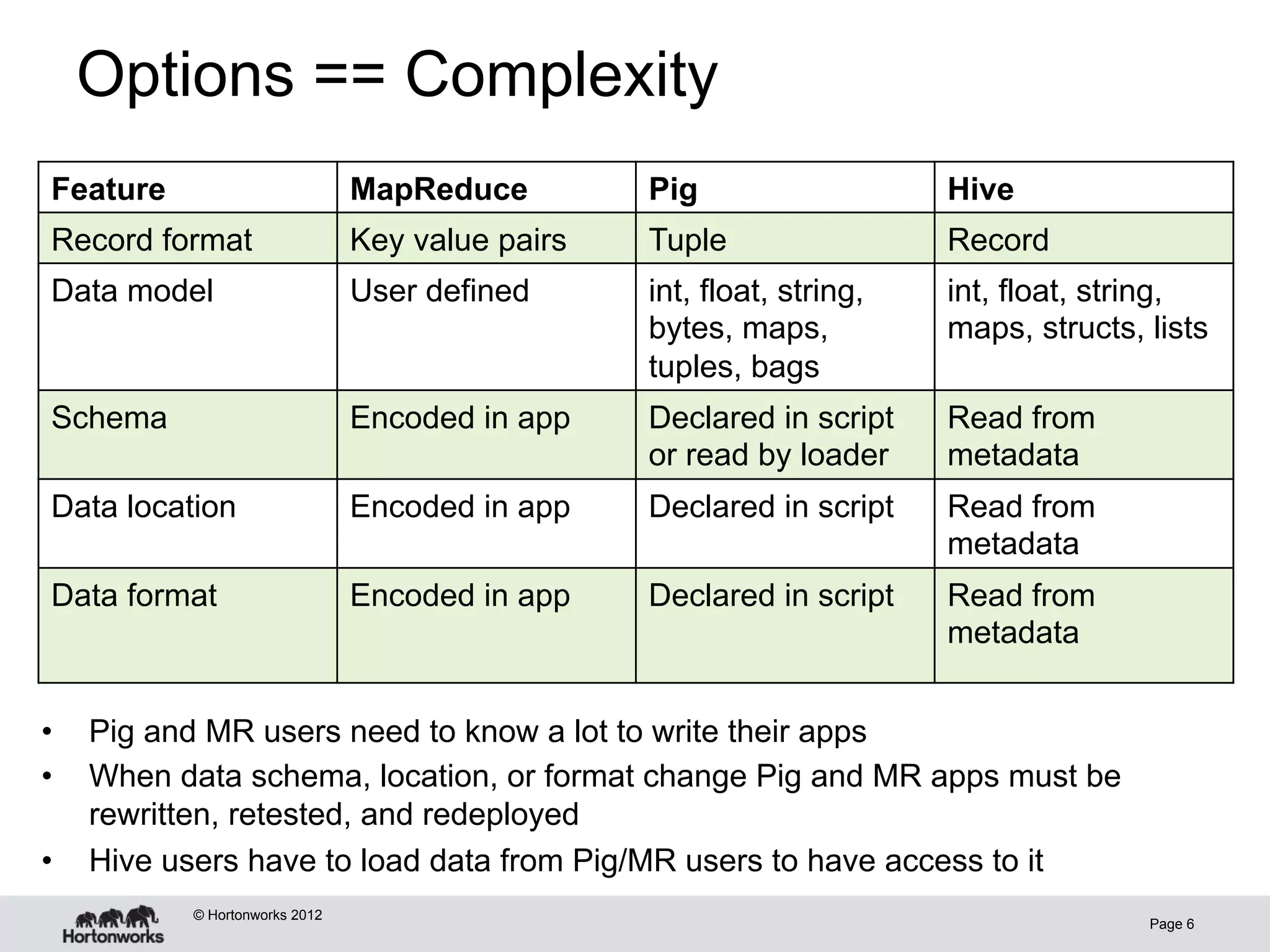
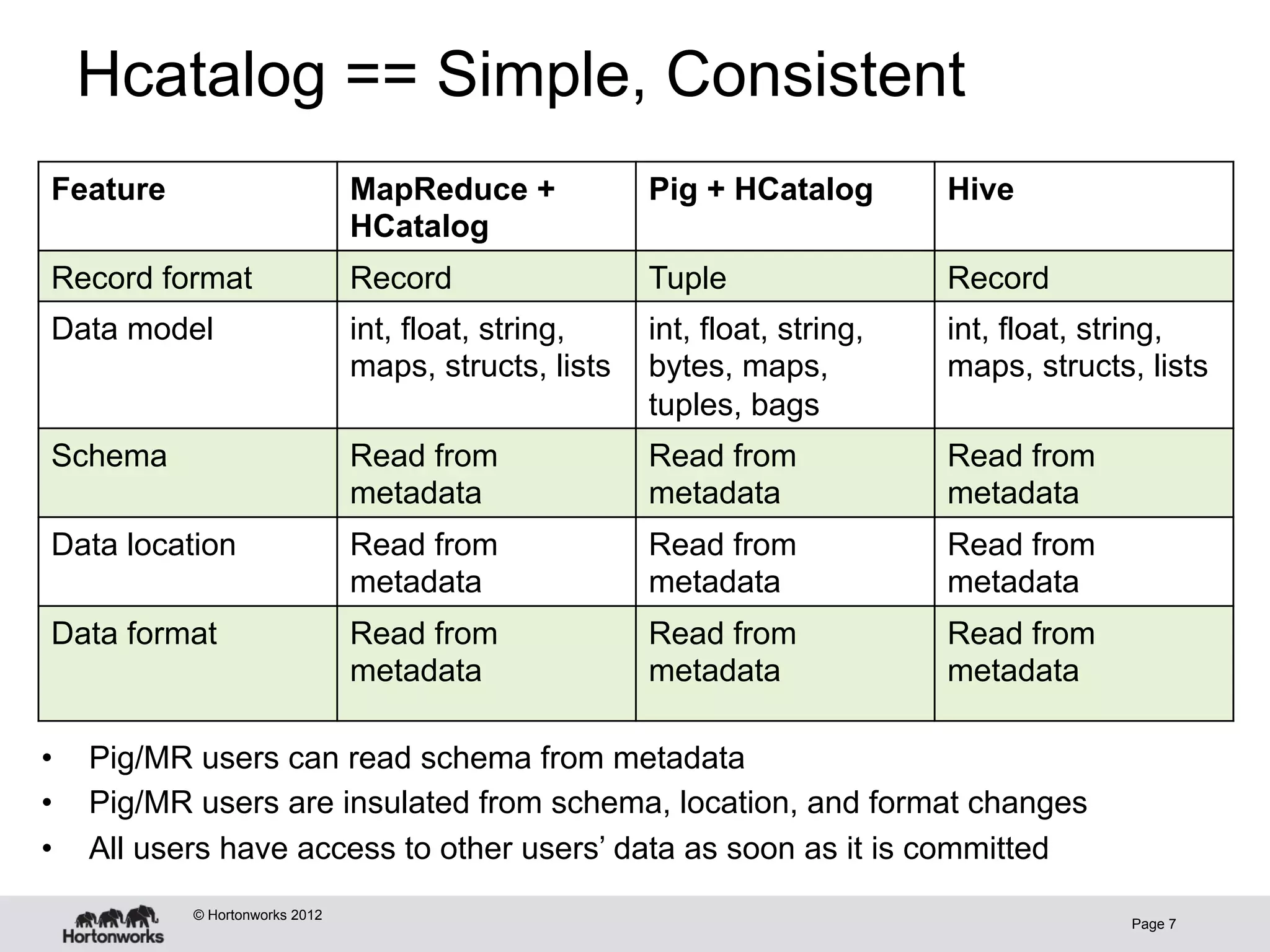
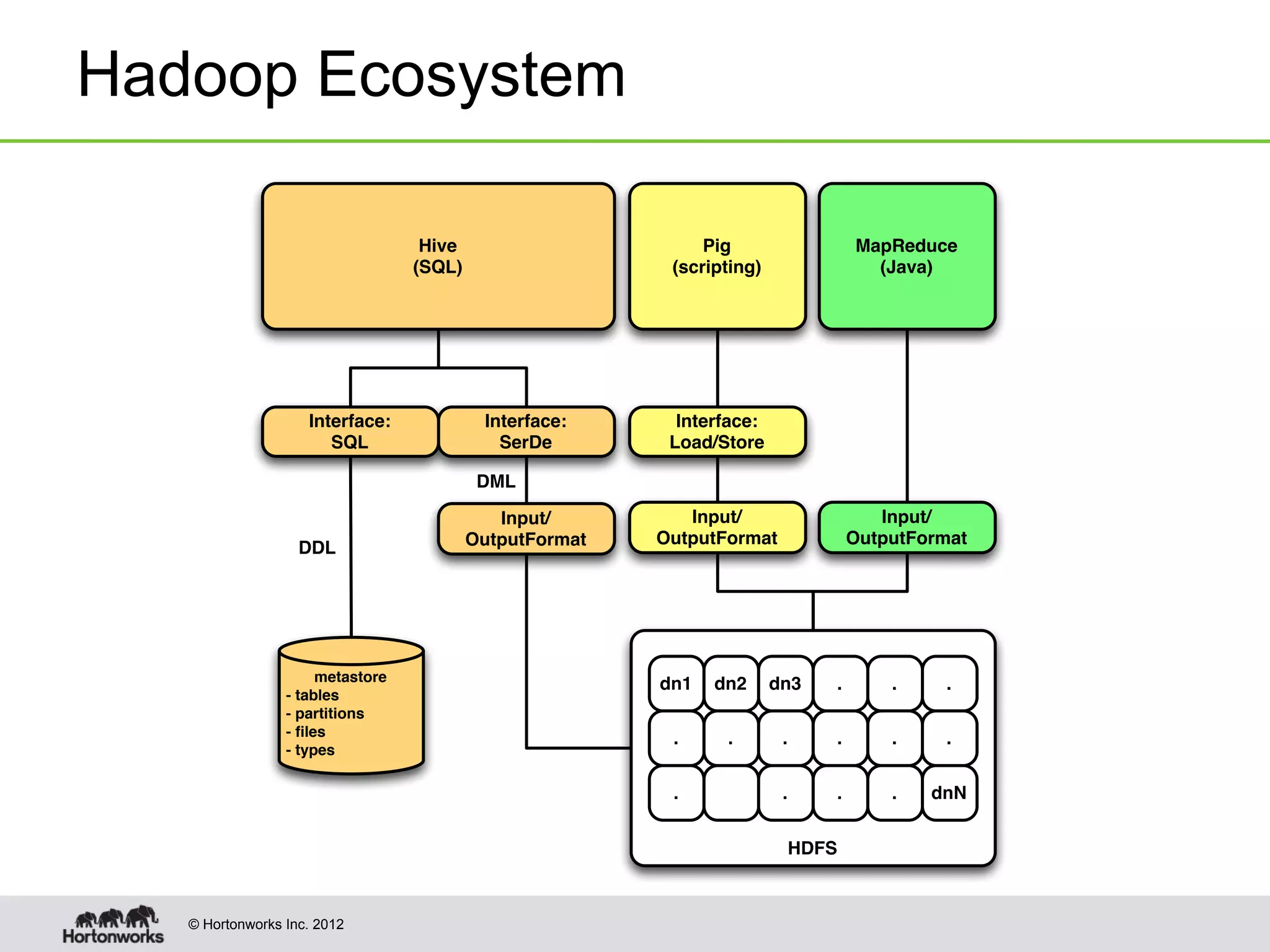
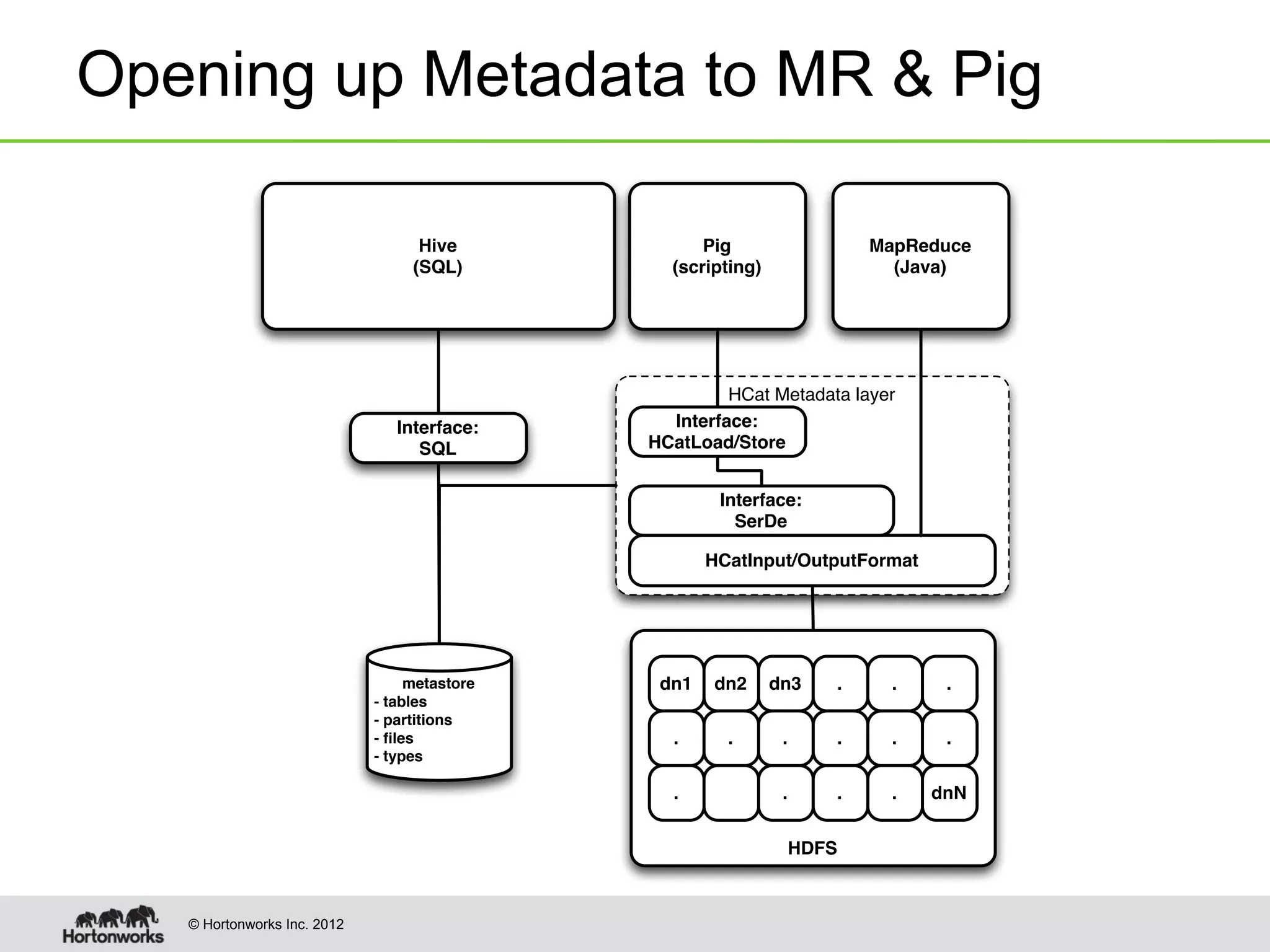



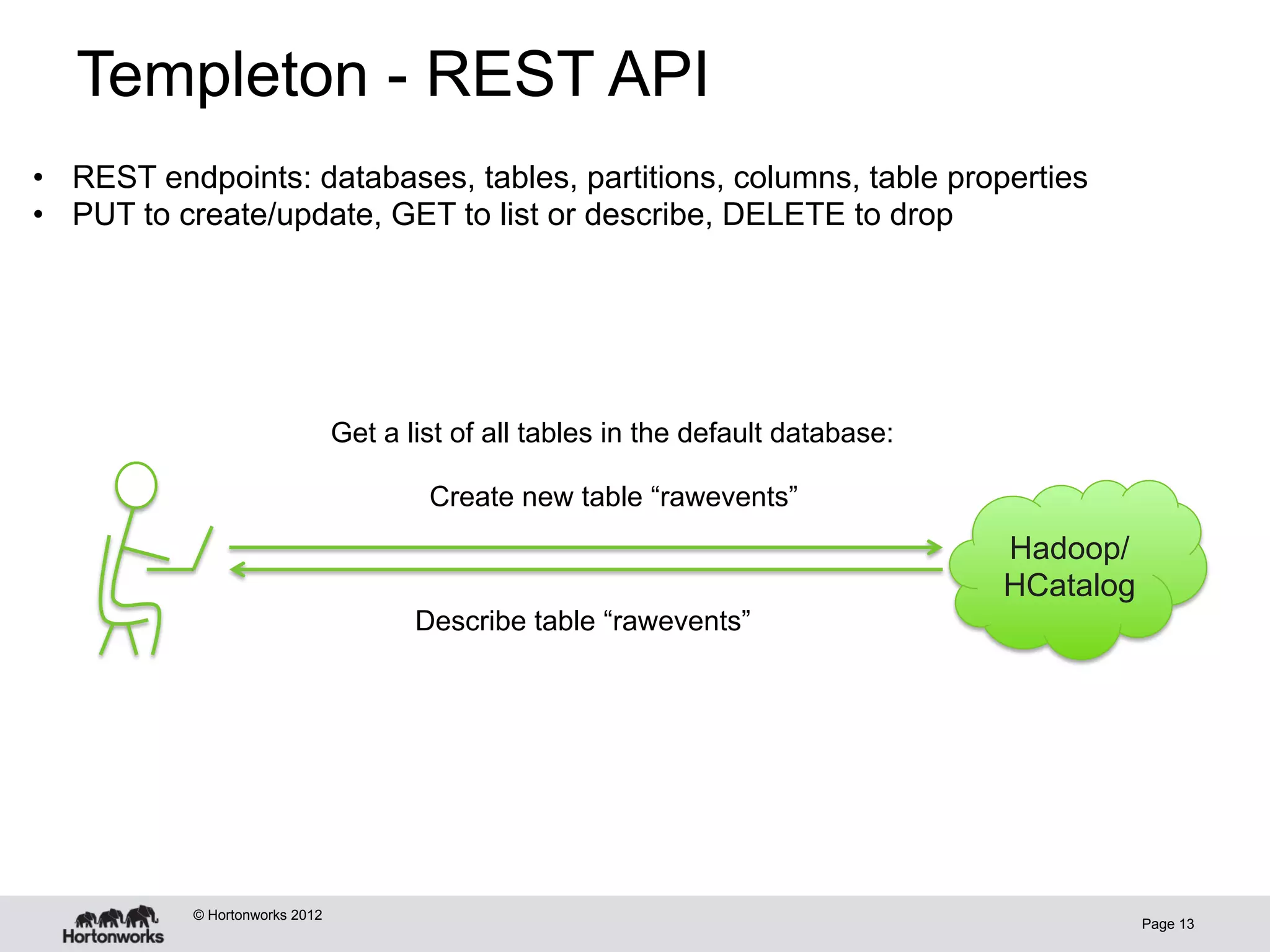
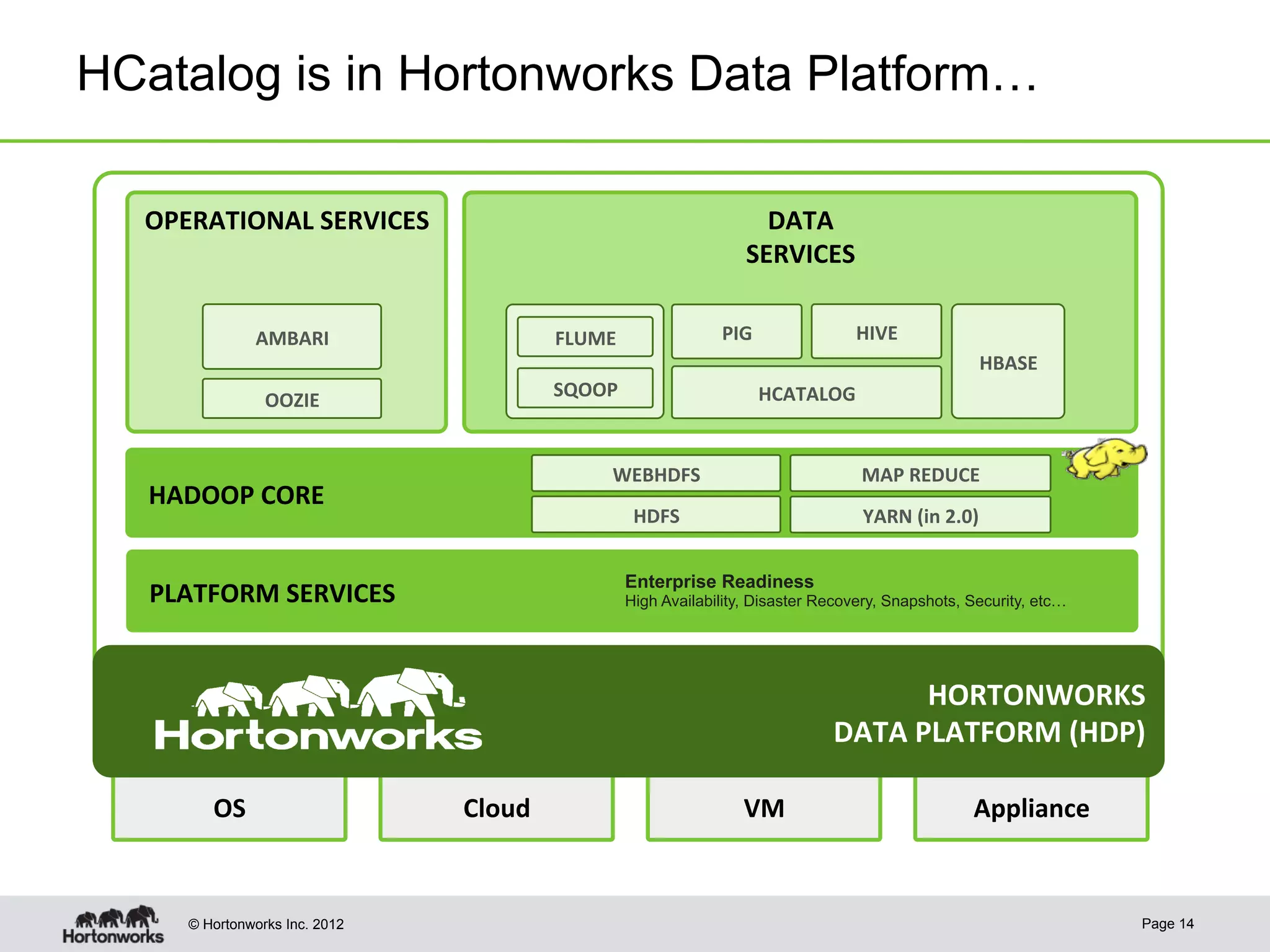
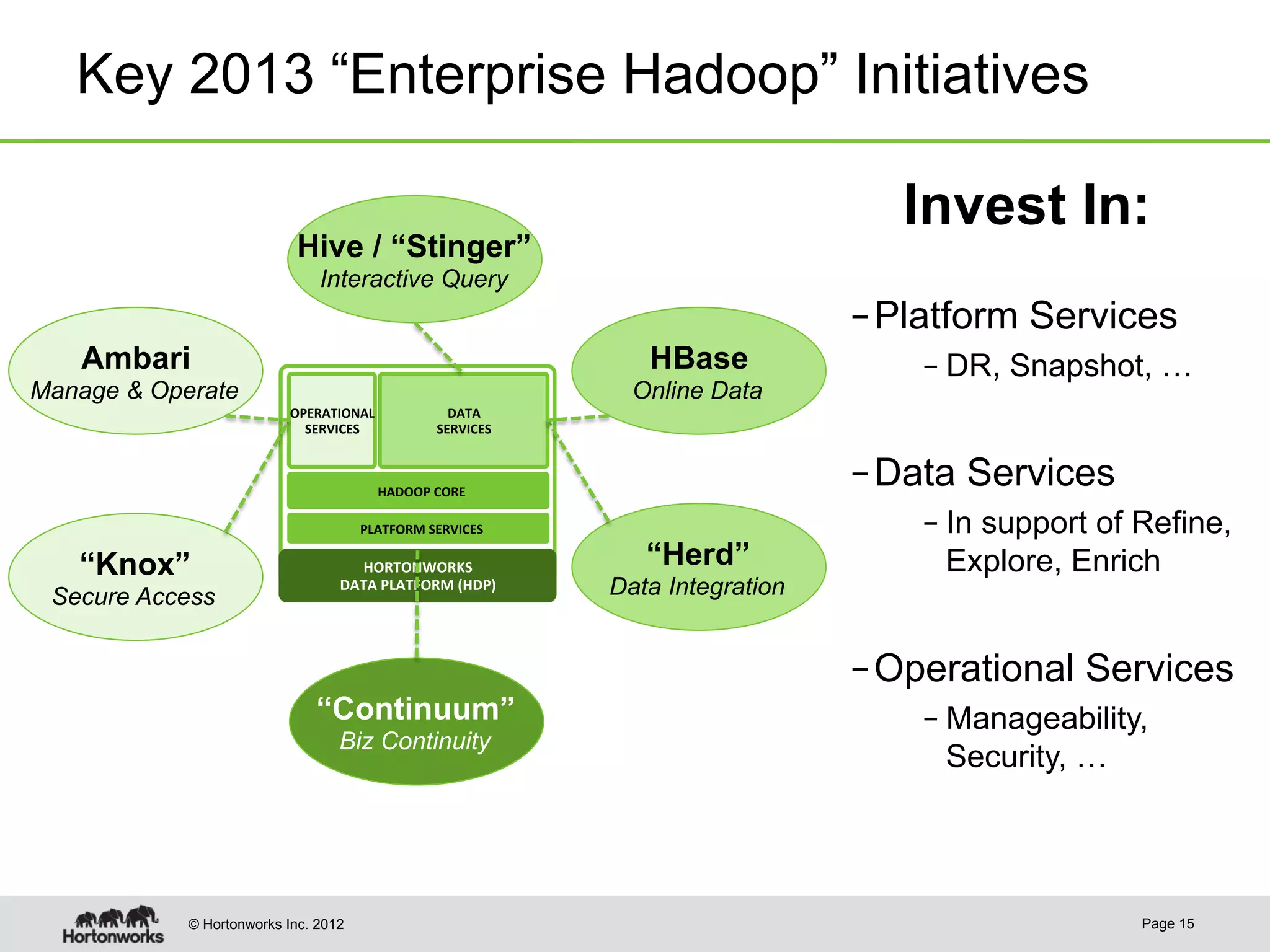





The document discusses Apache HCatalog, which provides metadata services and a unified view of data across Hadoop tools like Hive, Pig, and MapReduce. It allows sharing of data and metadata between tools and external systems through a consistent schema. HCatalog simplifies data management by allowing tools to access metadata like the schema, location, and format of data from a shared metastore instead of encoding that information within each application.













































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













