Downloaded 74 times



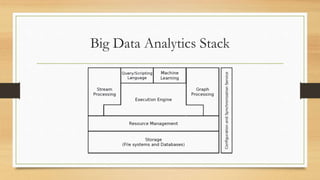







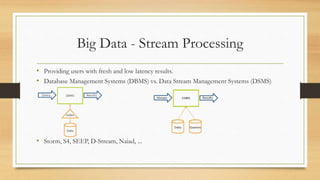



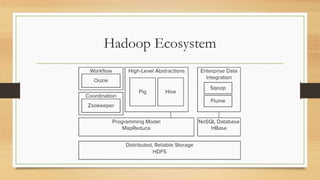












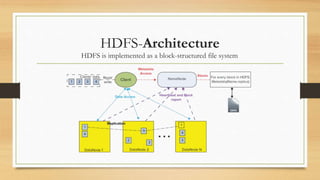

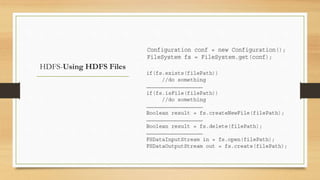




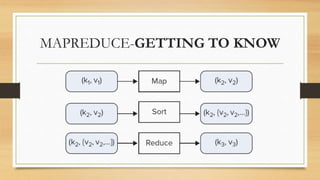
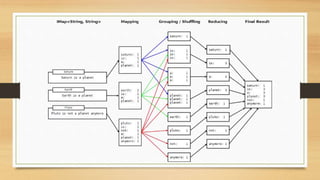
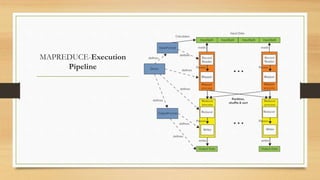



















This document discusses cloud and big data technologies. It provides an overview of Hadoop and its ecosystem, which includes components like HDFS, MapReduce, HBase, Zookeeper, Pig and Hive. It also describes how data is stored in HDFS and HBase, and how MapReduce can be used for parallel processing across large datasets. Finally, it gives examples of using MapReduce to implement algorithms for word counting, building inverted indexes and performing joins.
















































































