Downloaded 634 times


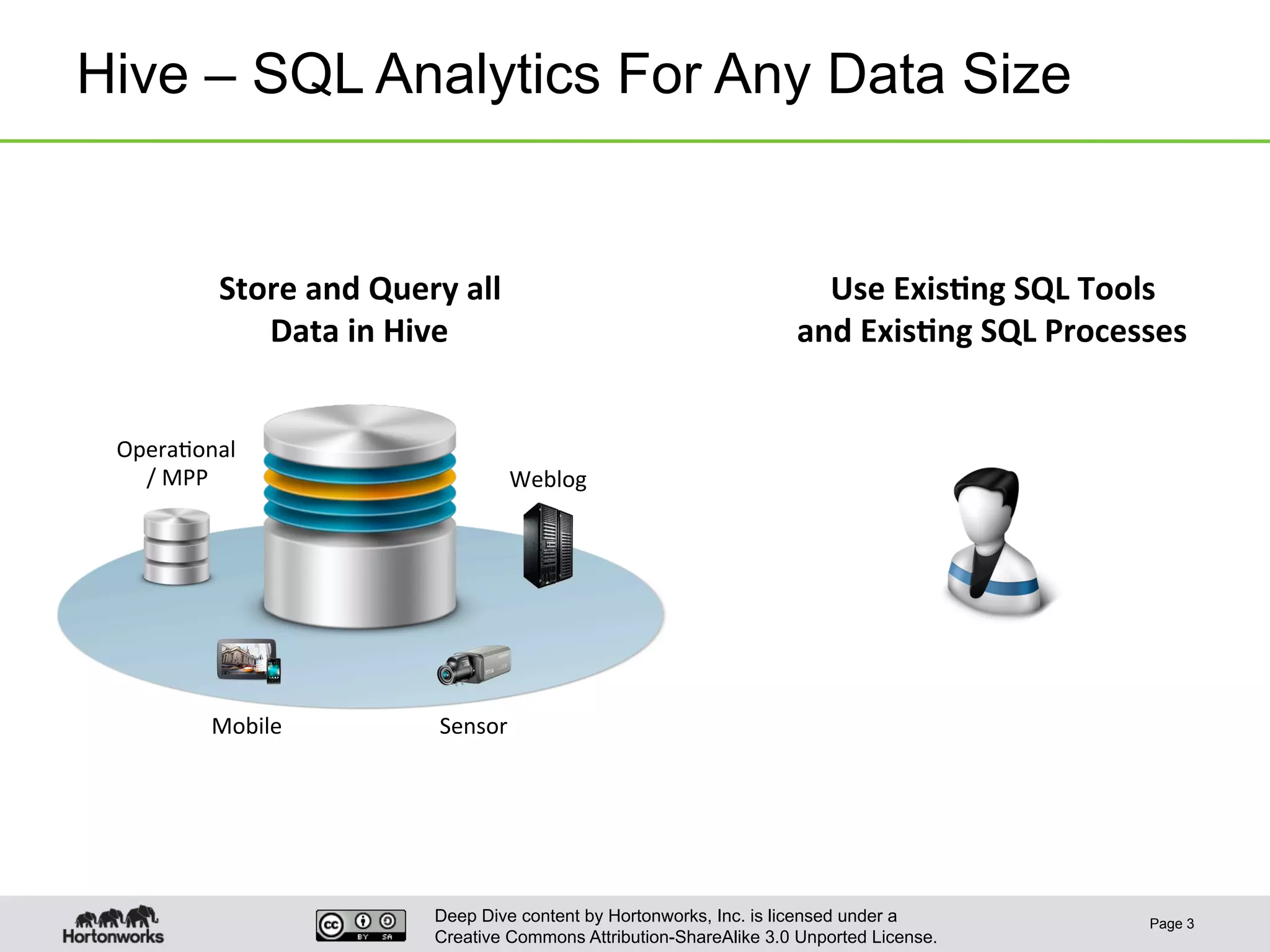



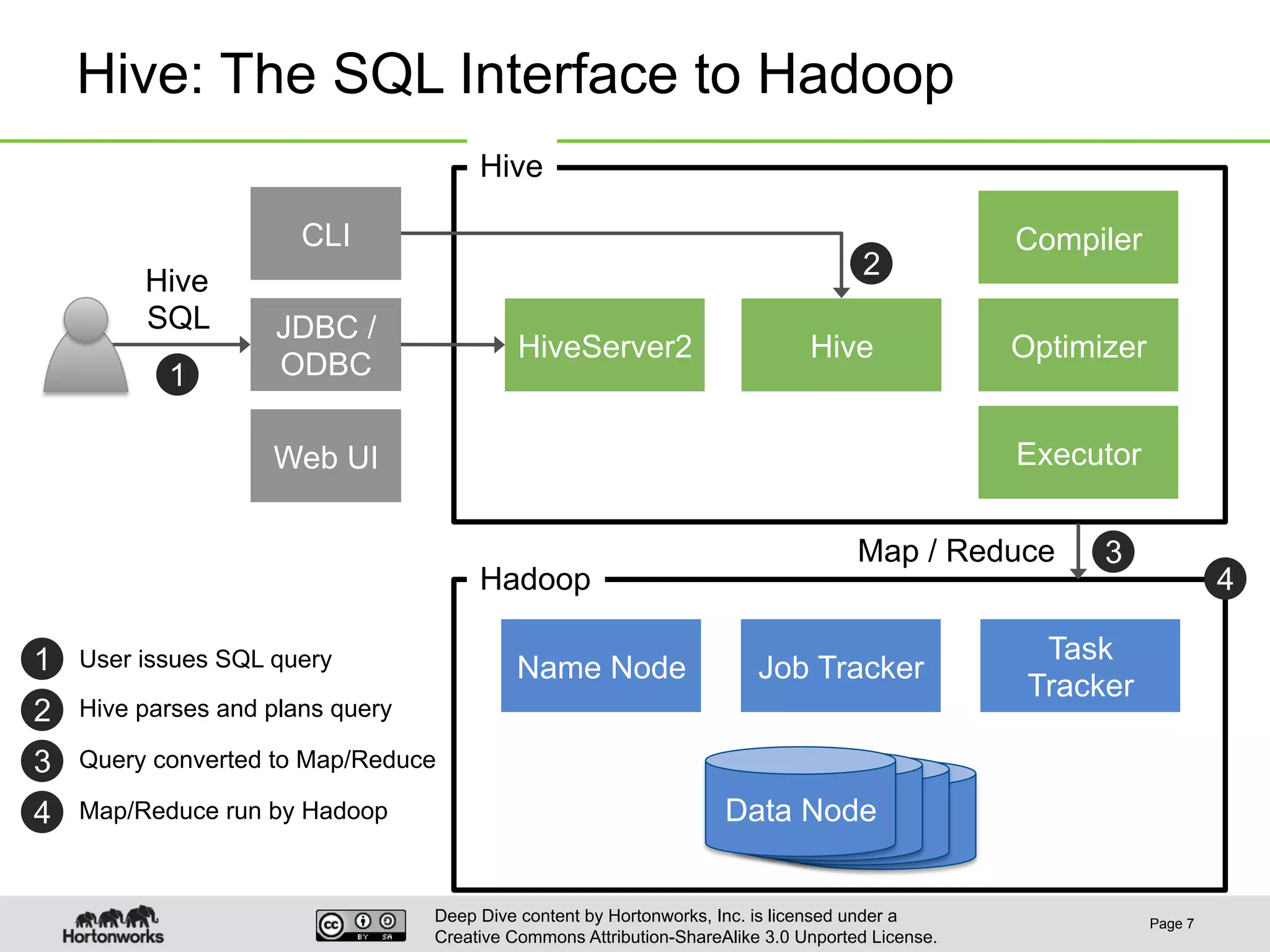
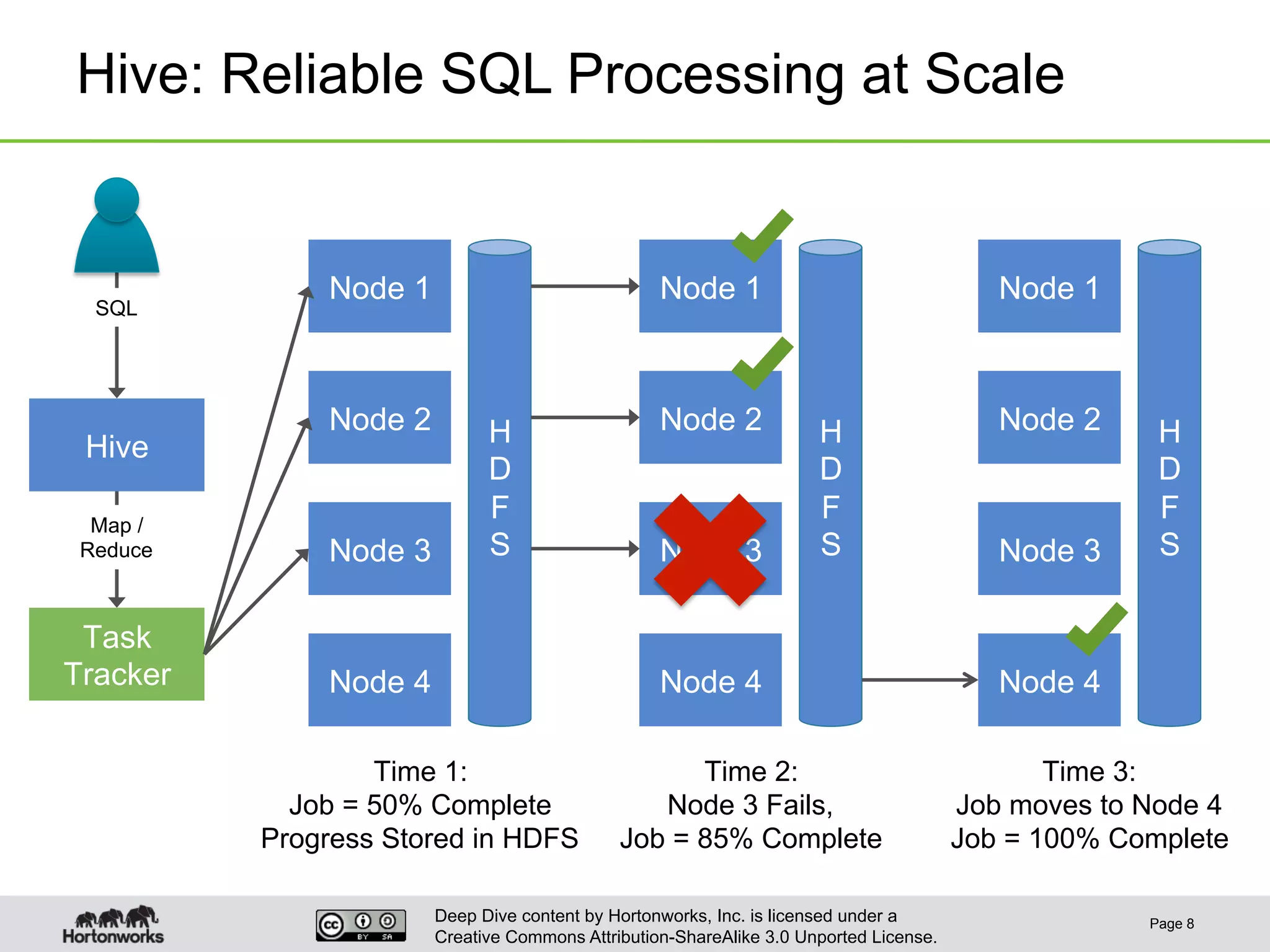


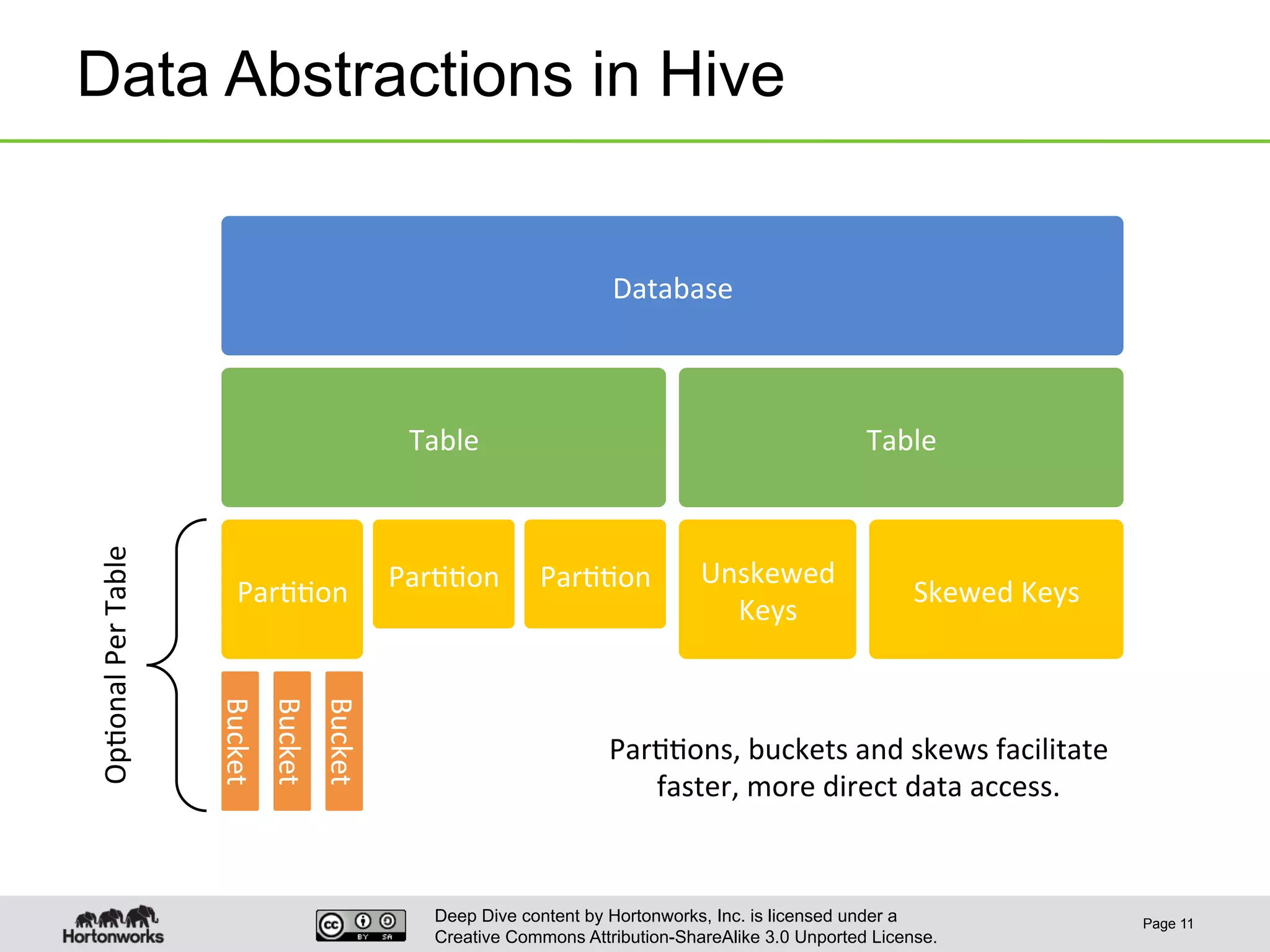



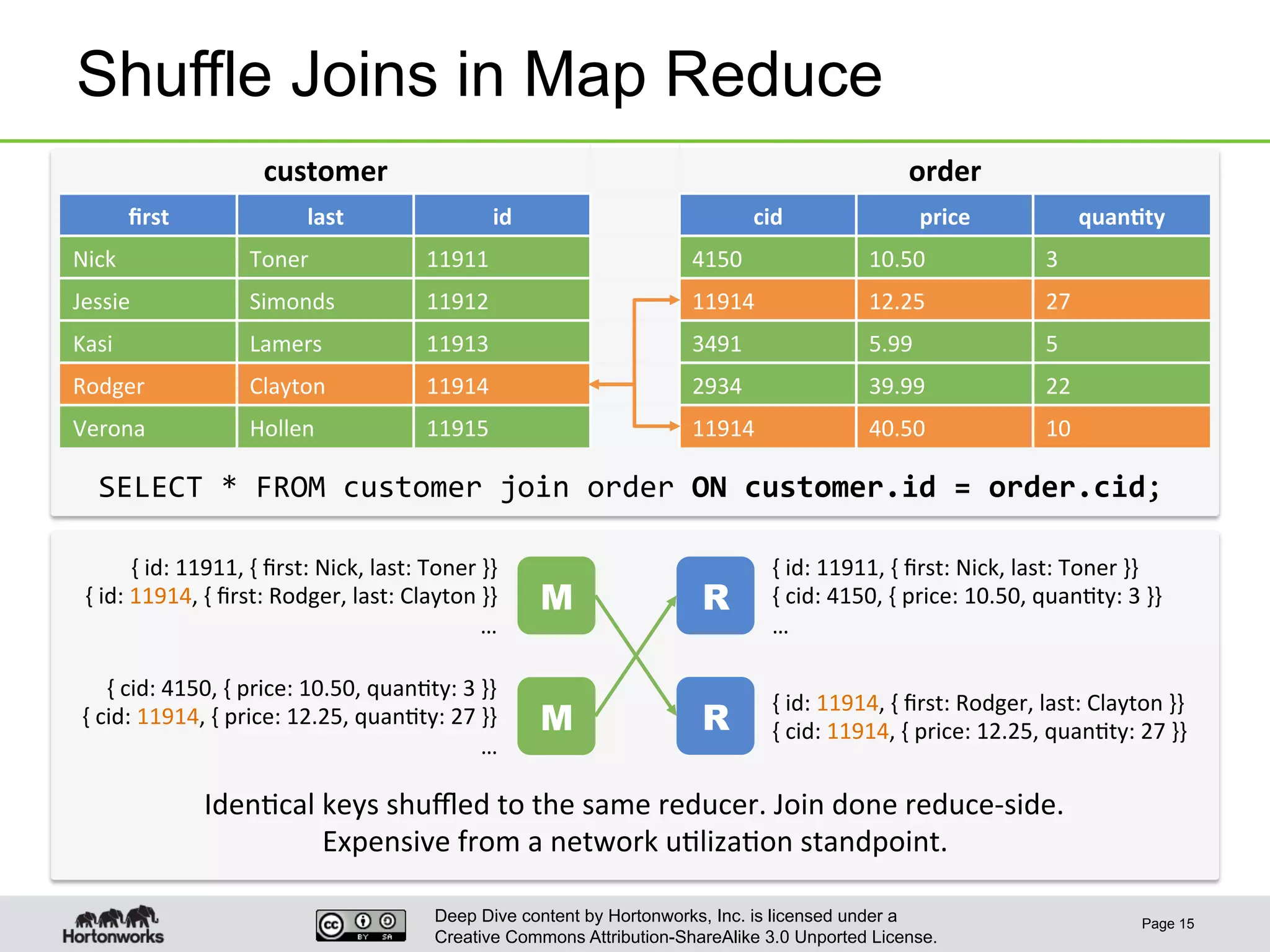

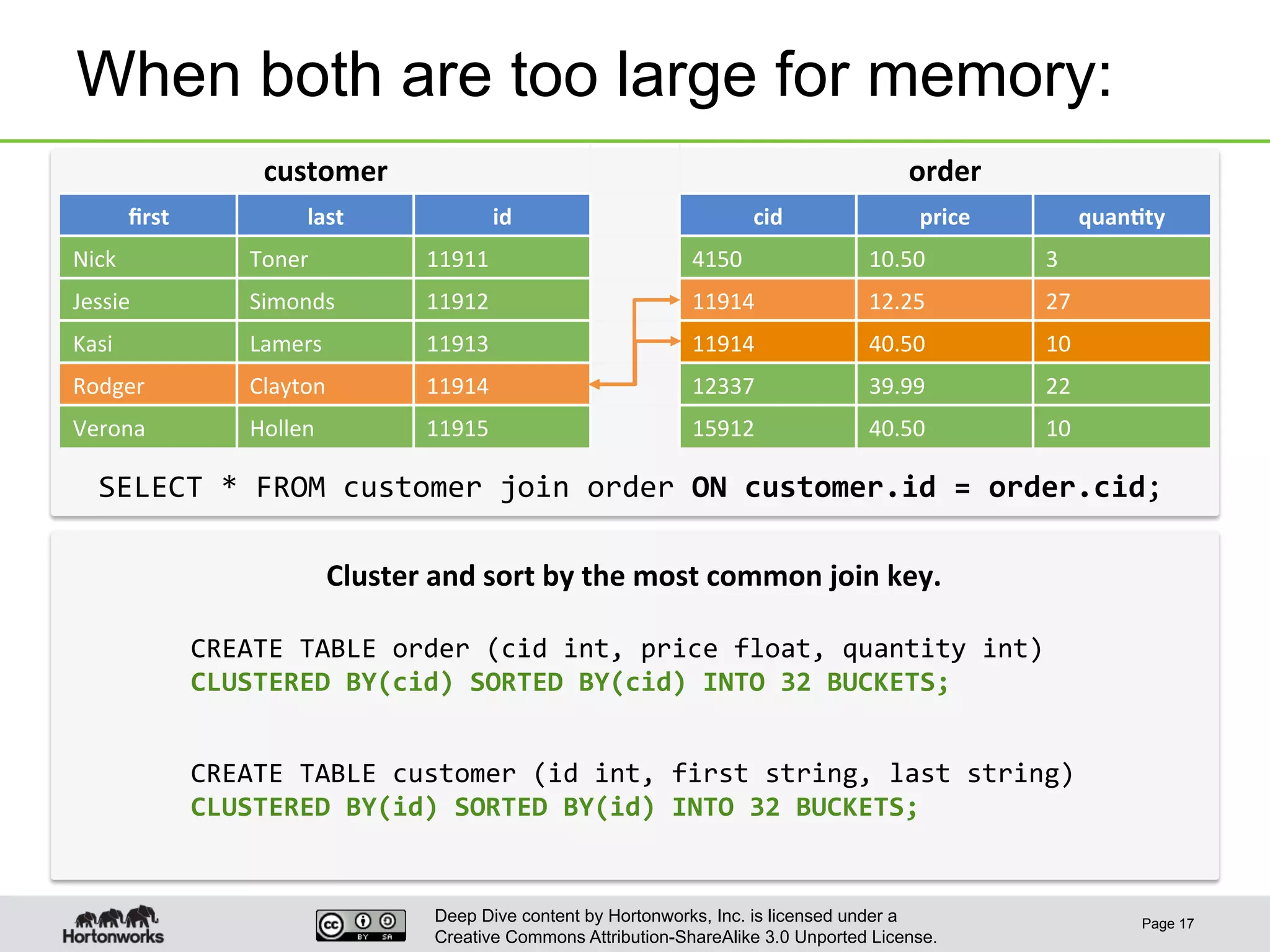
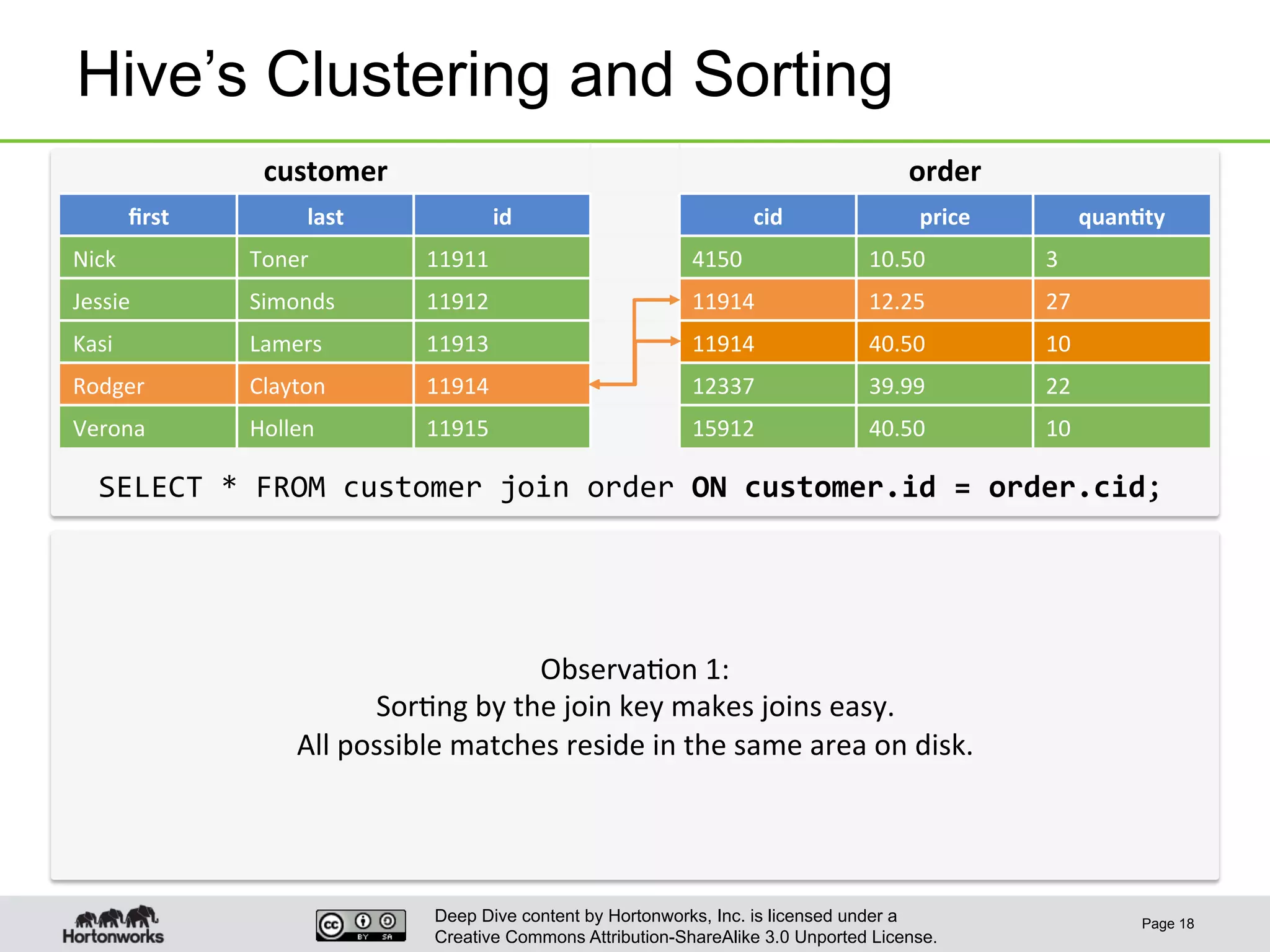
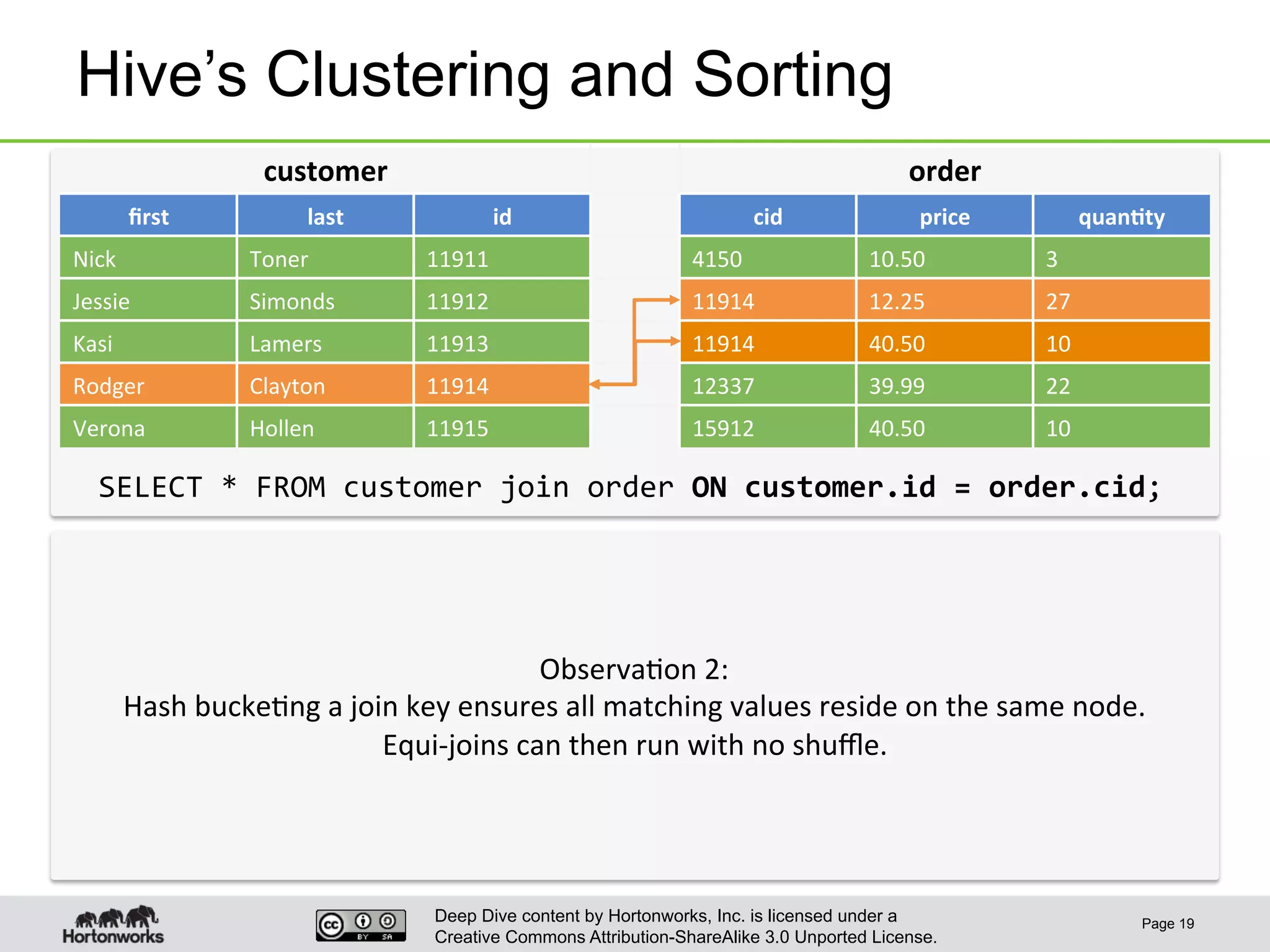

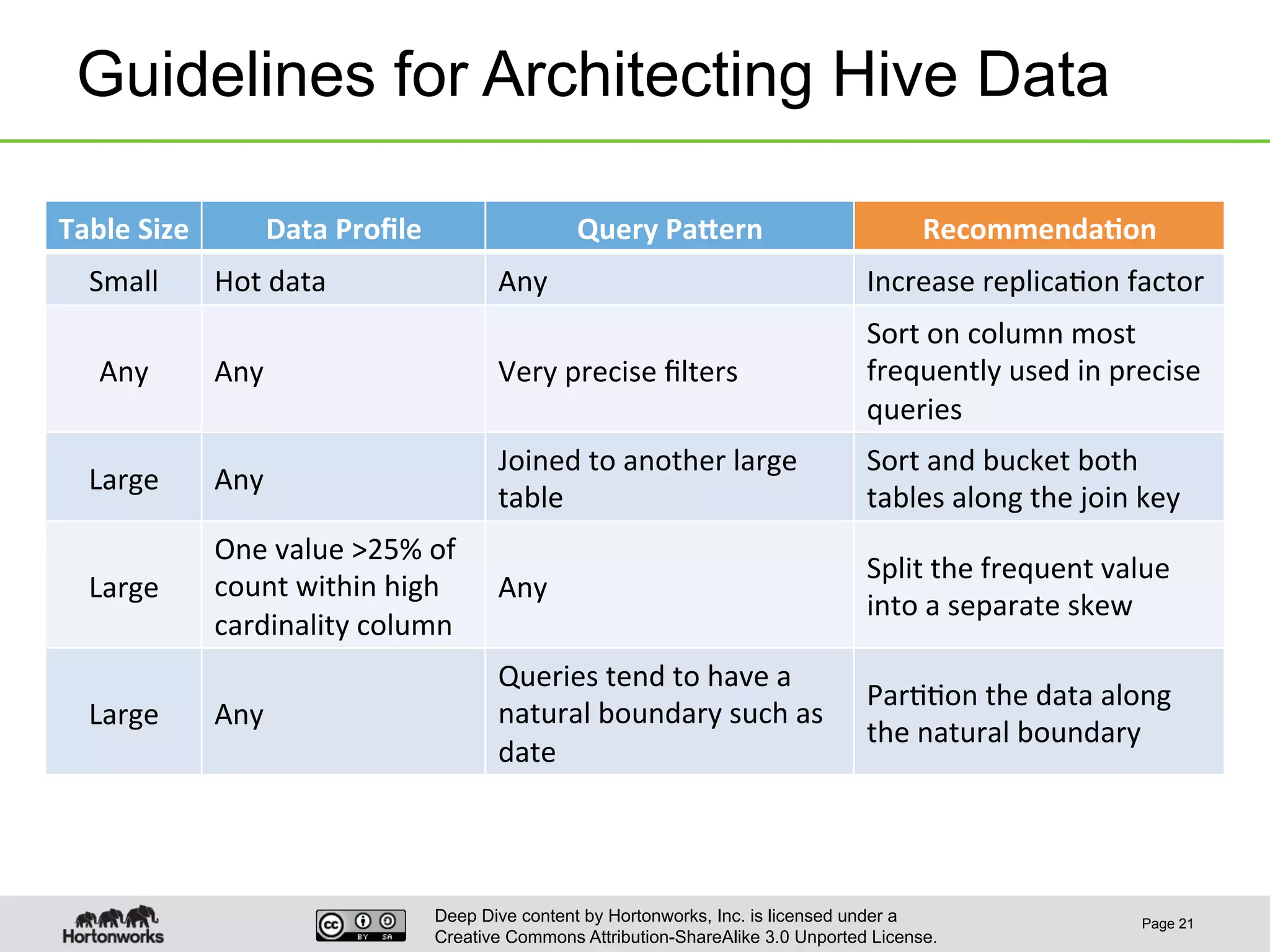


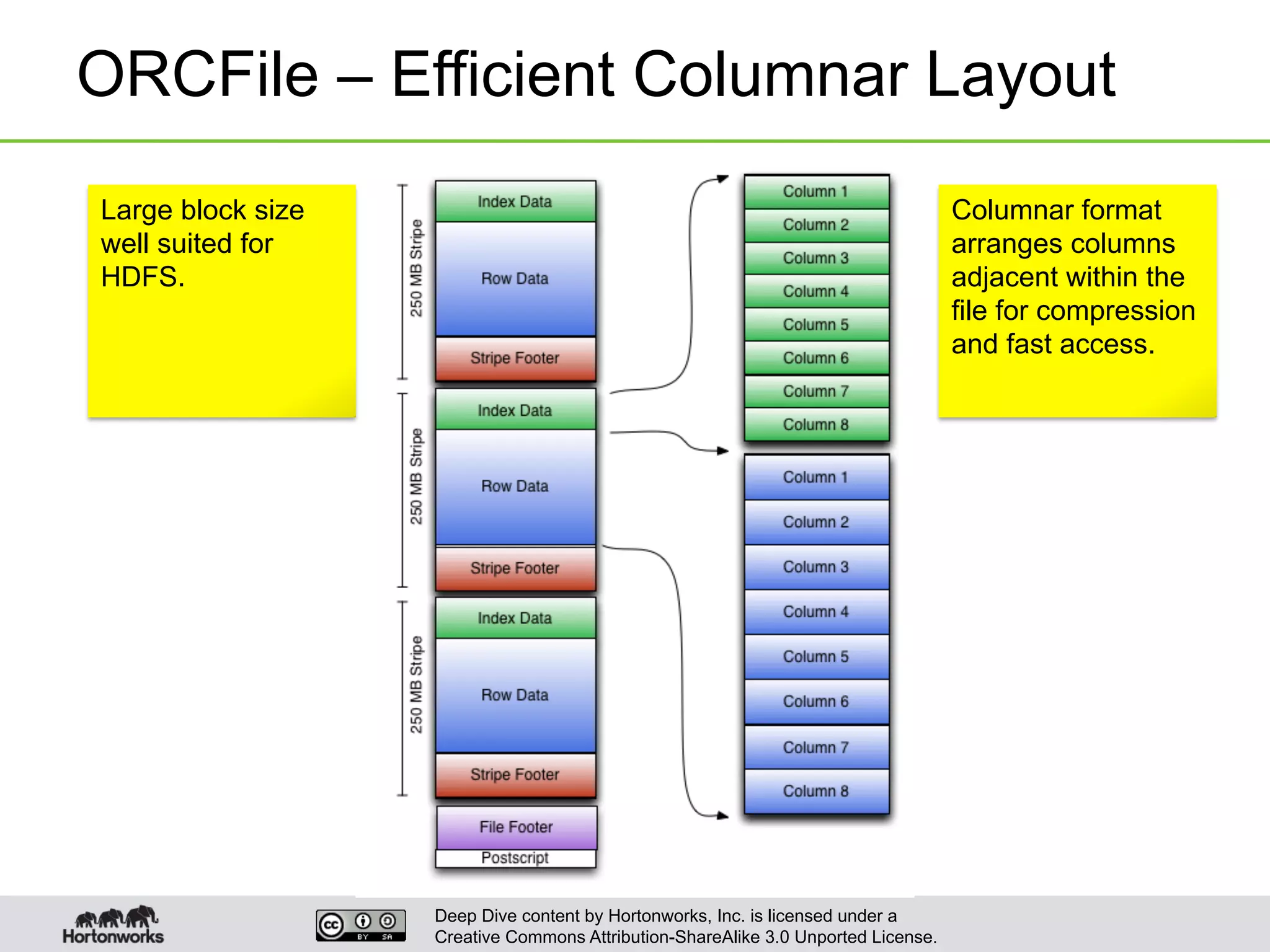

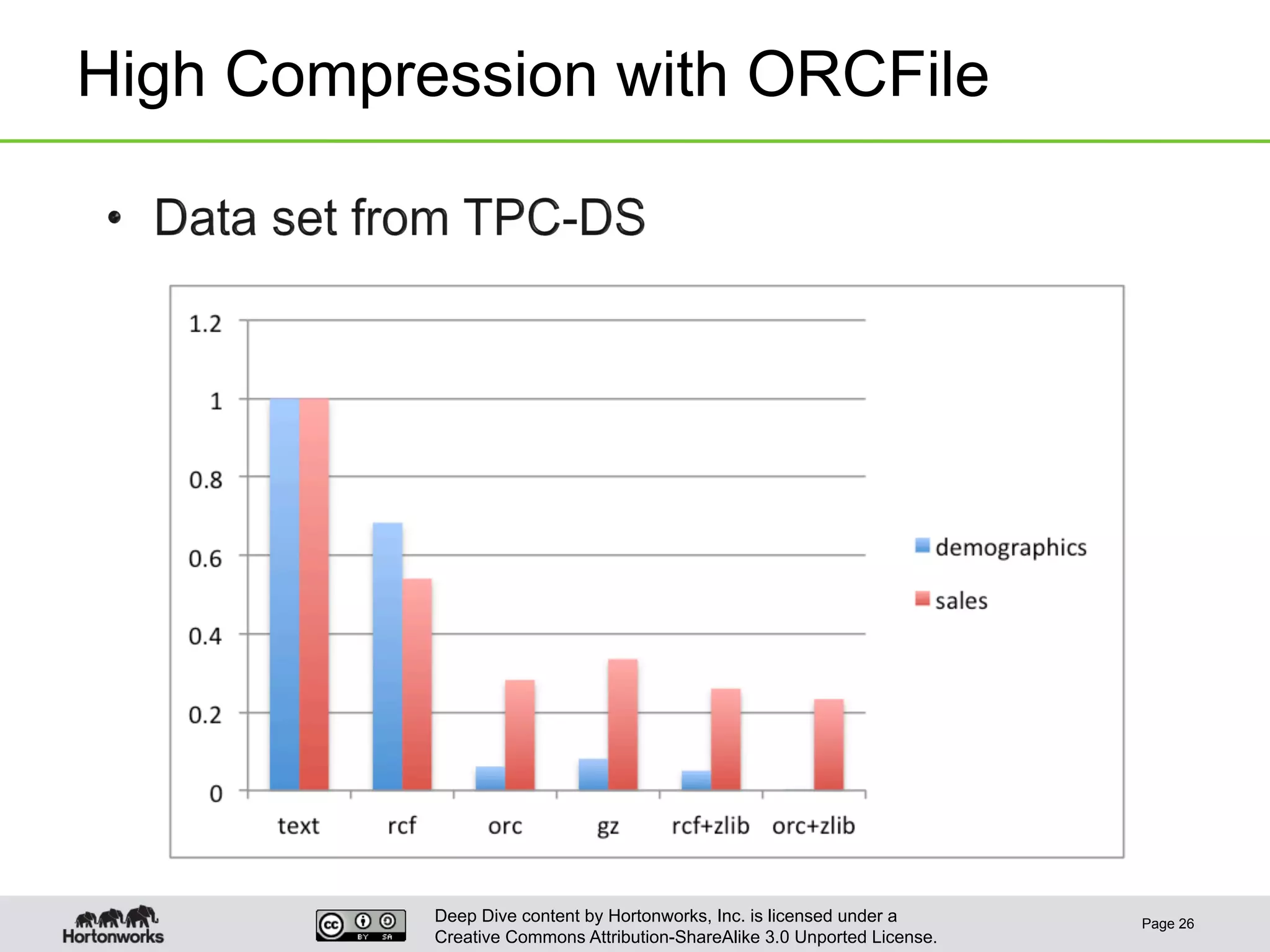
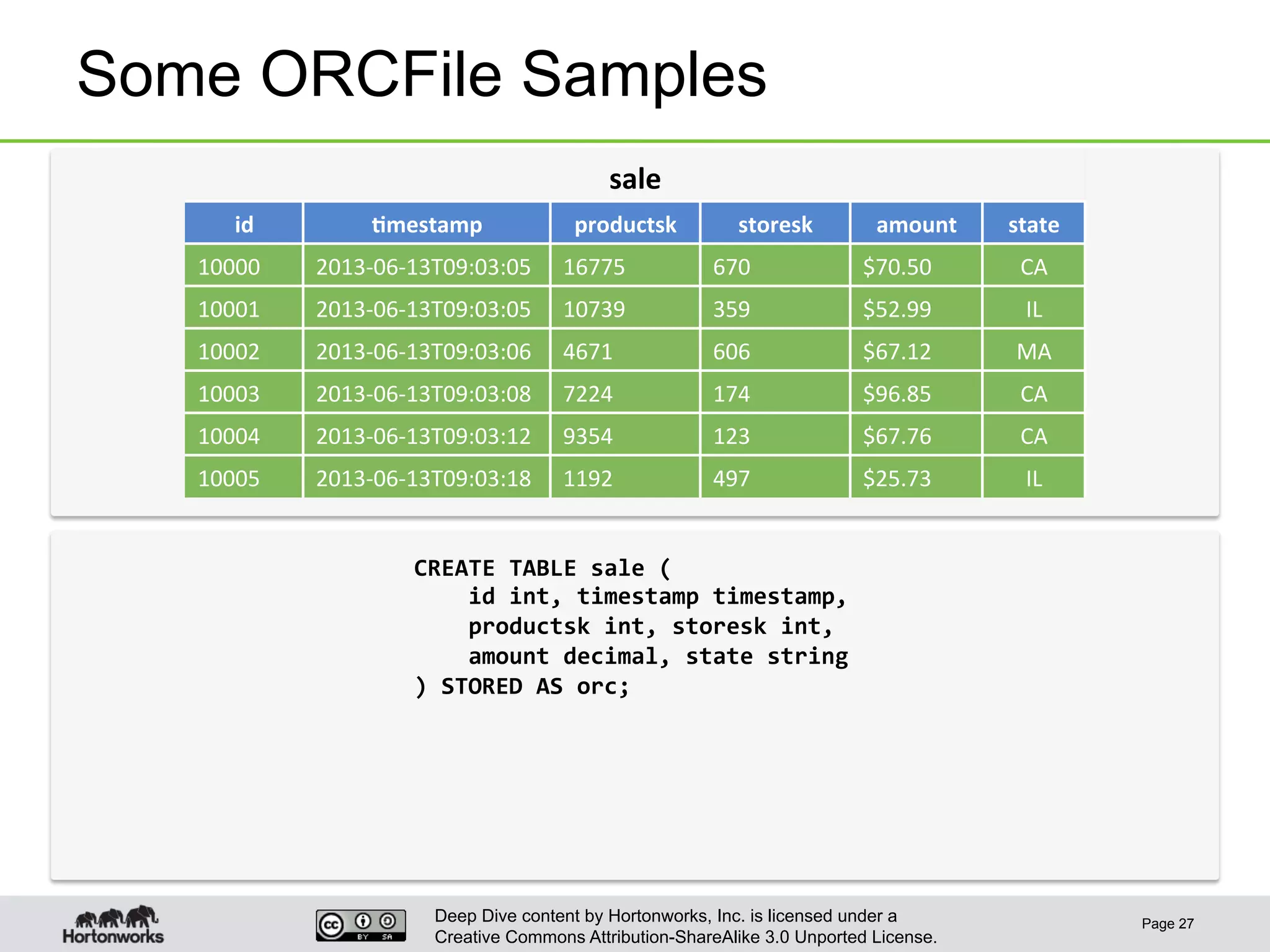


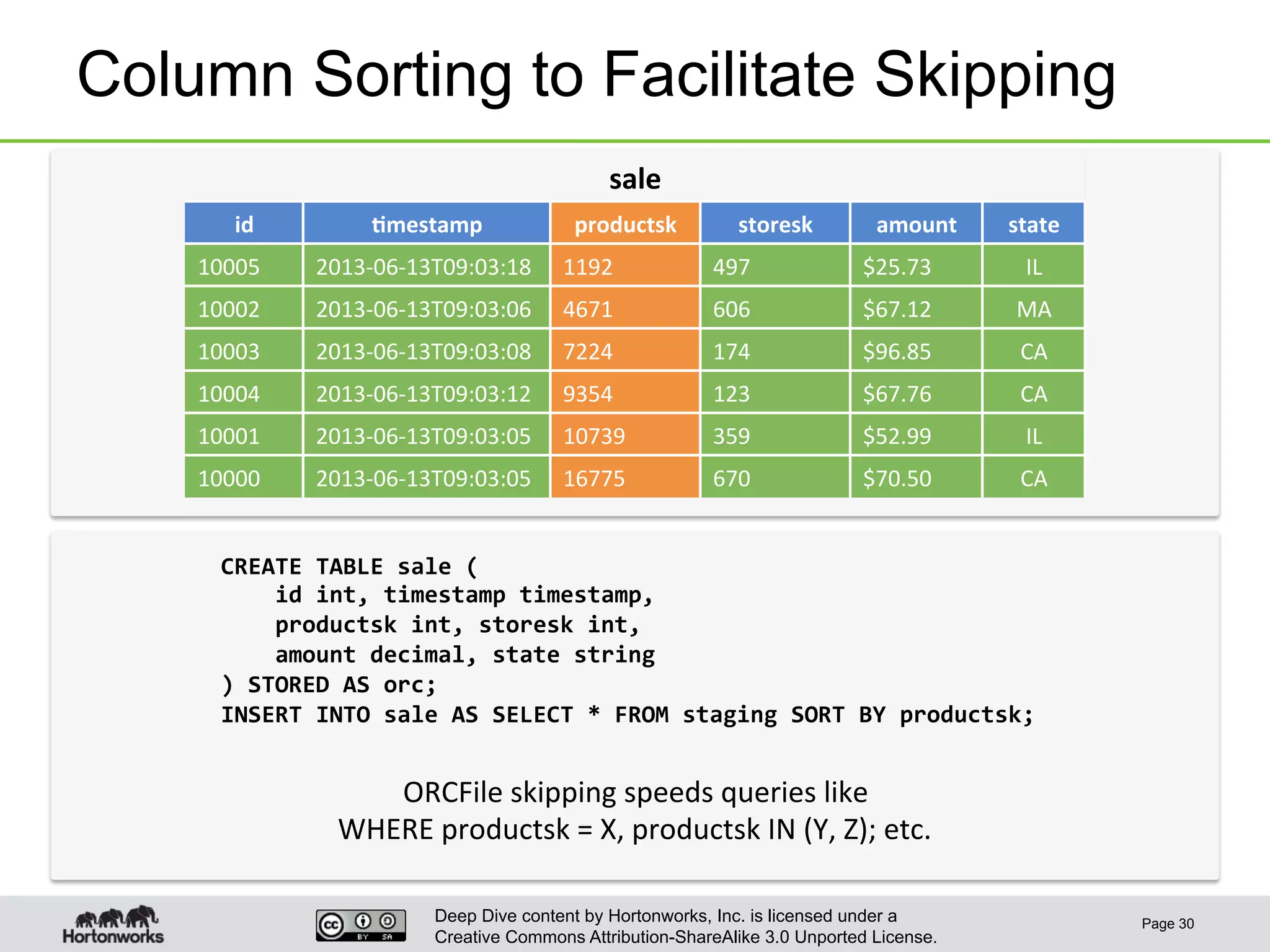





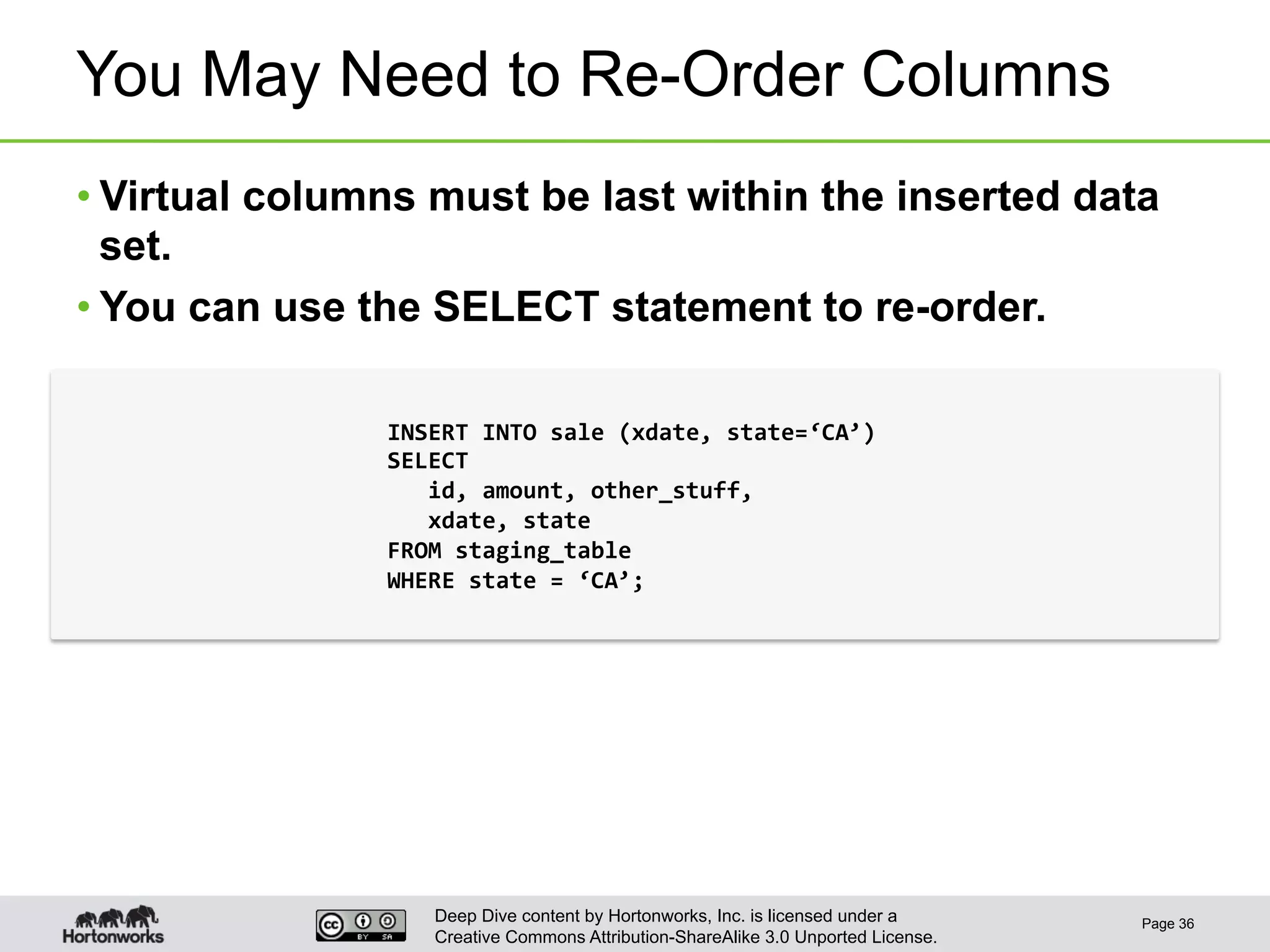



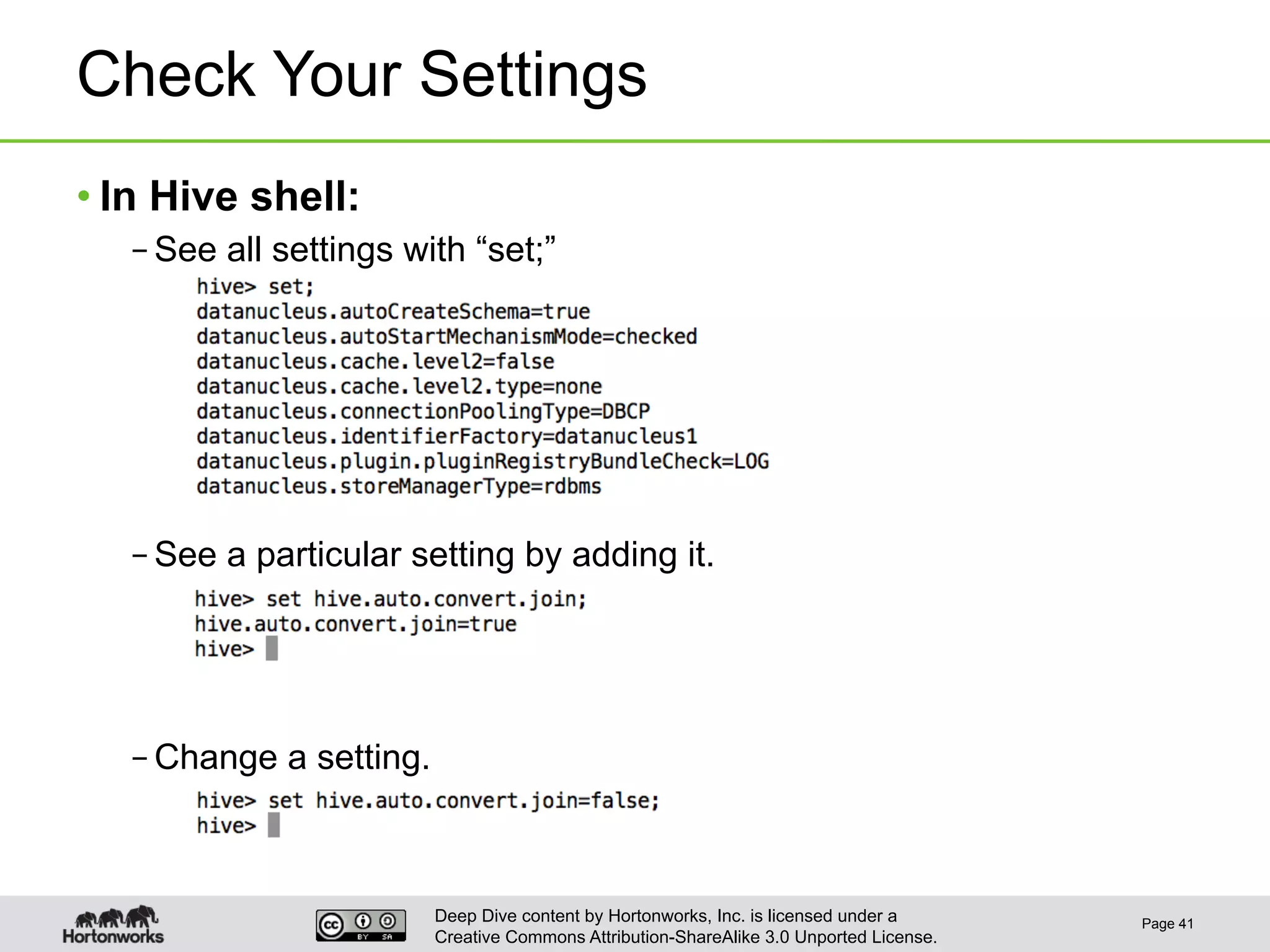


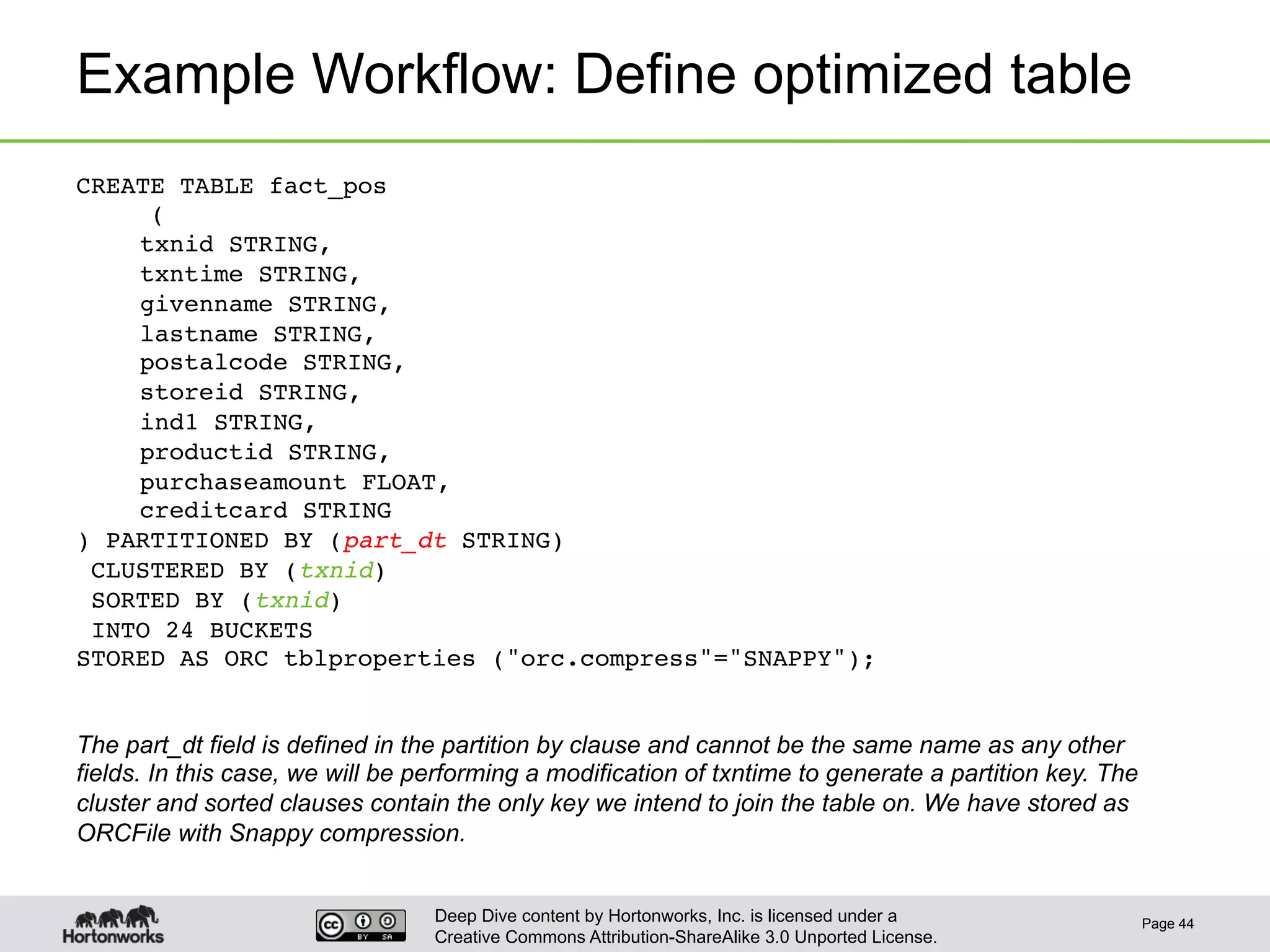
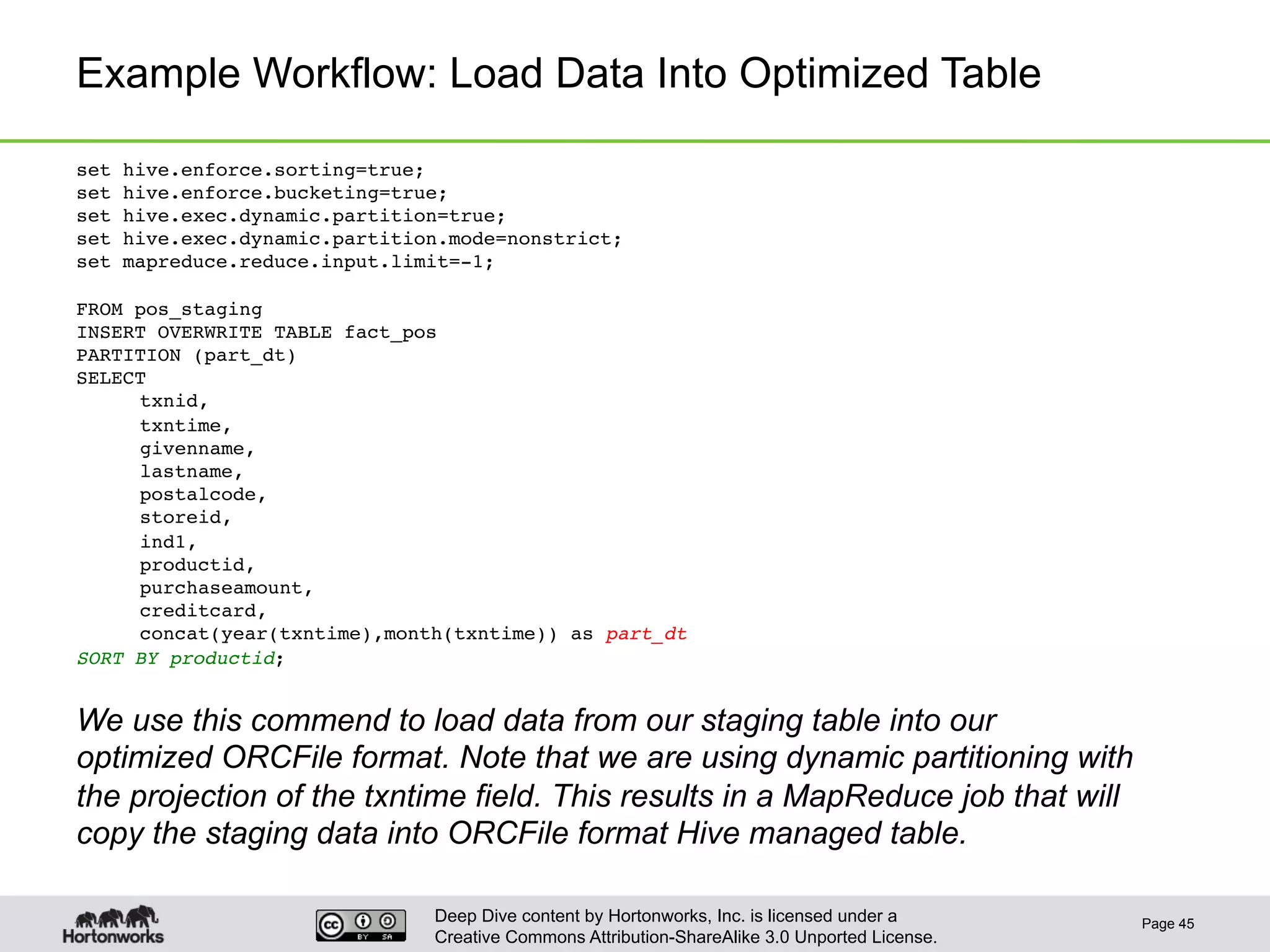

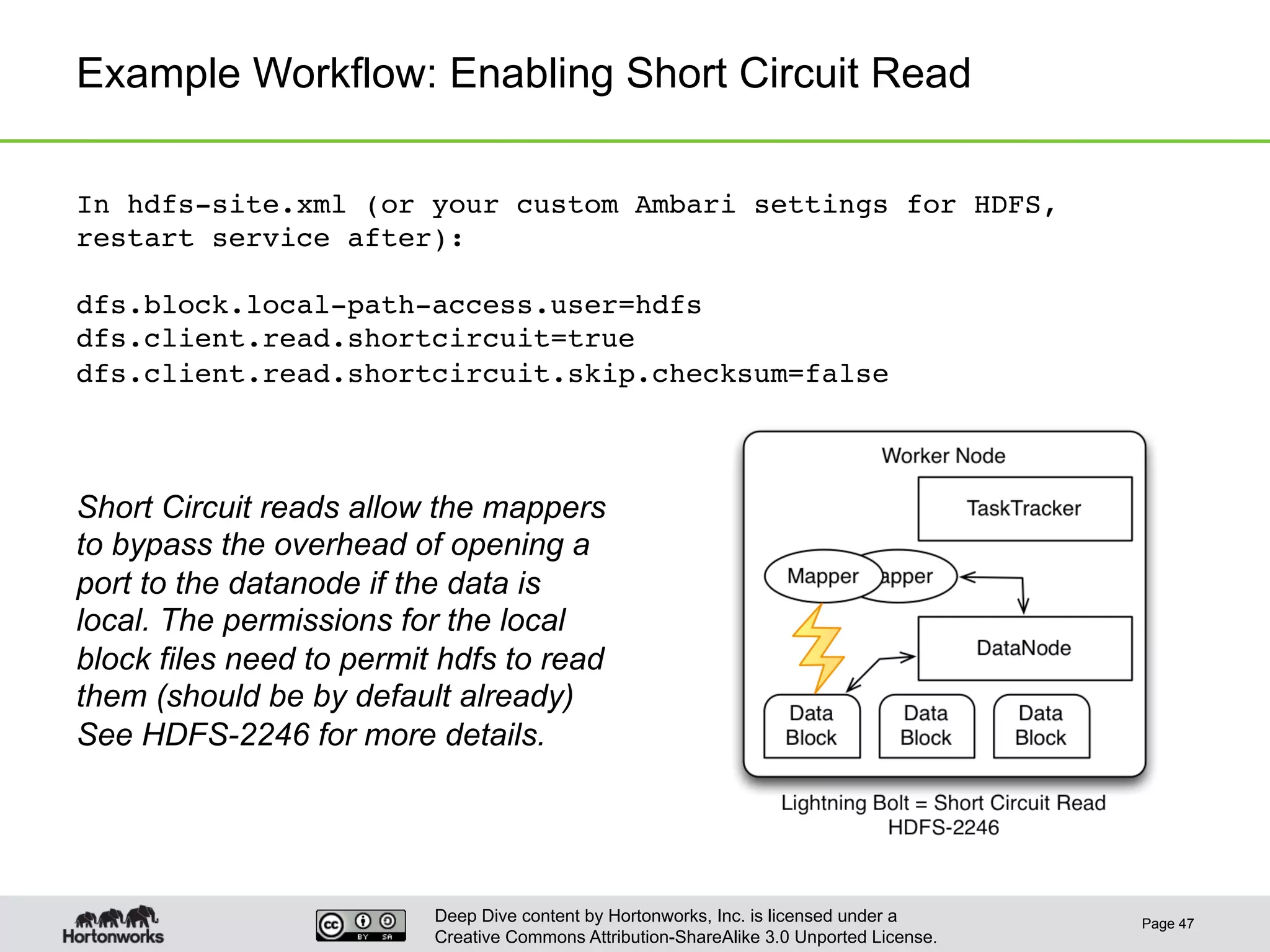

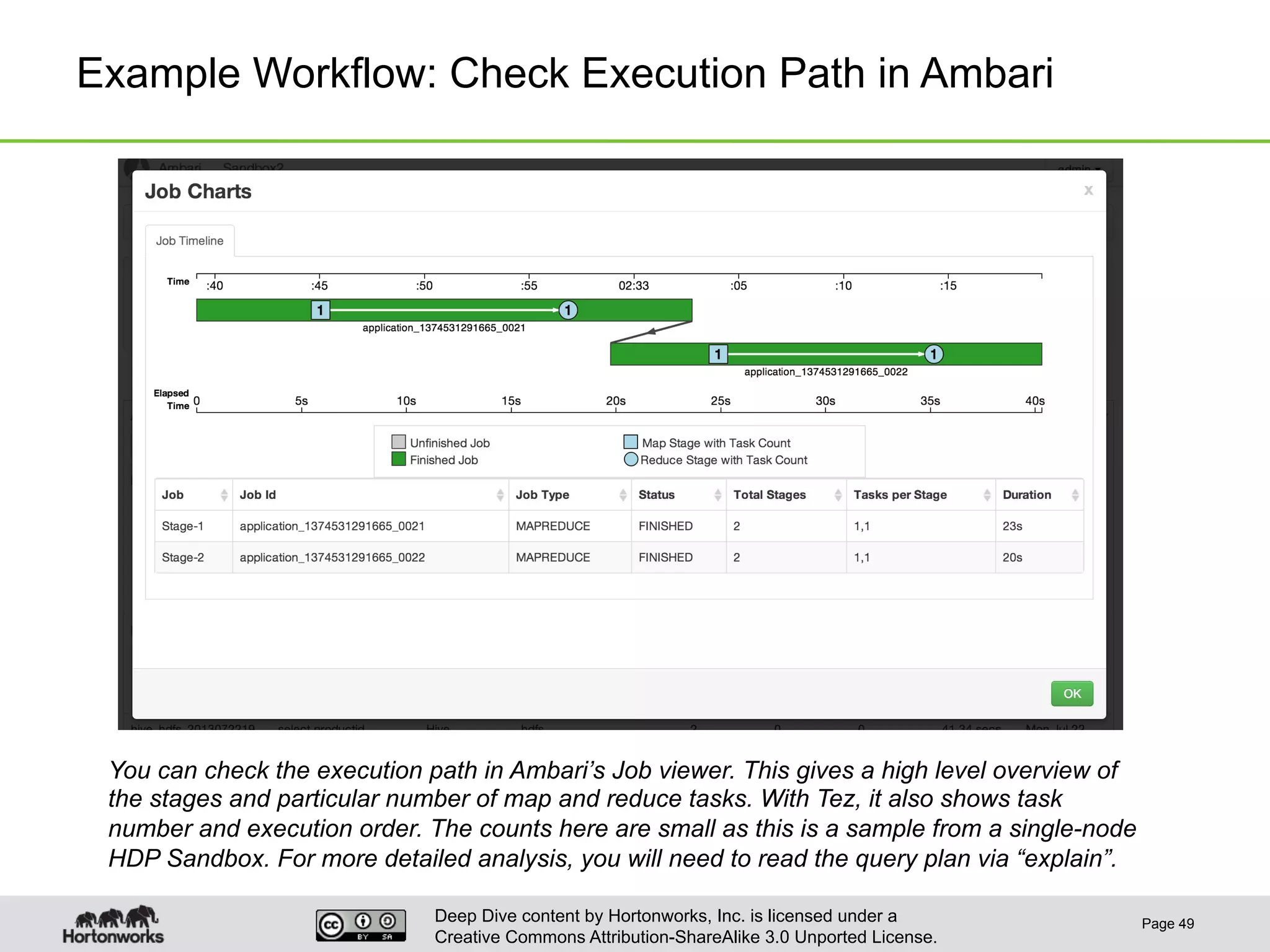

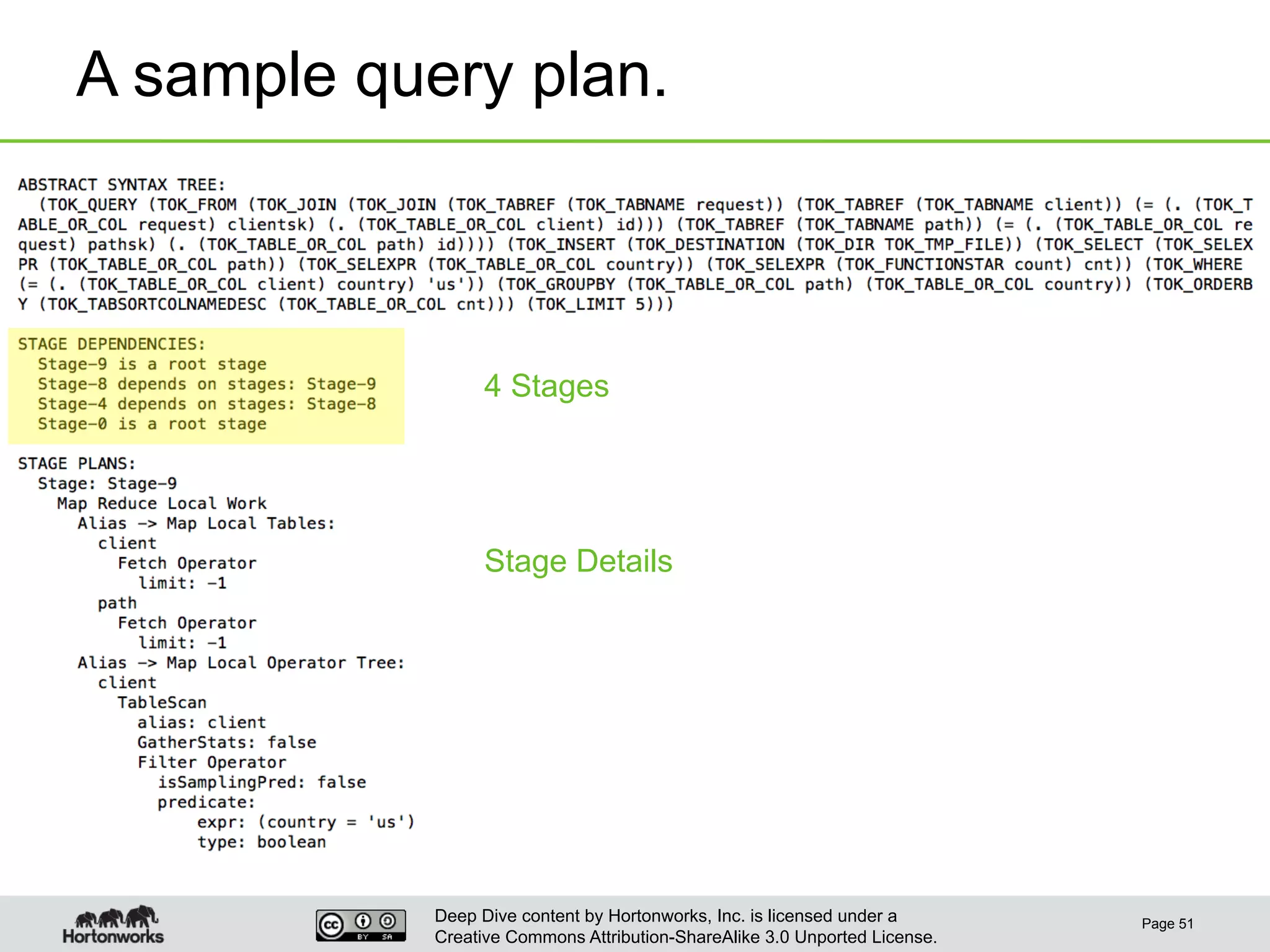











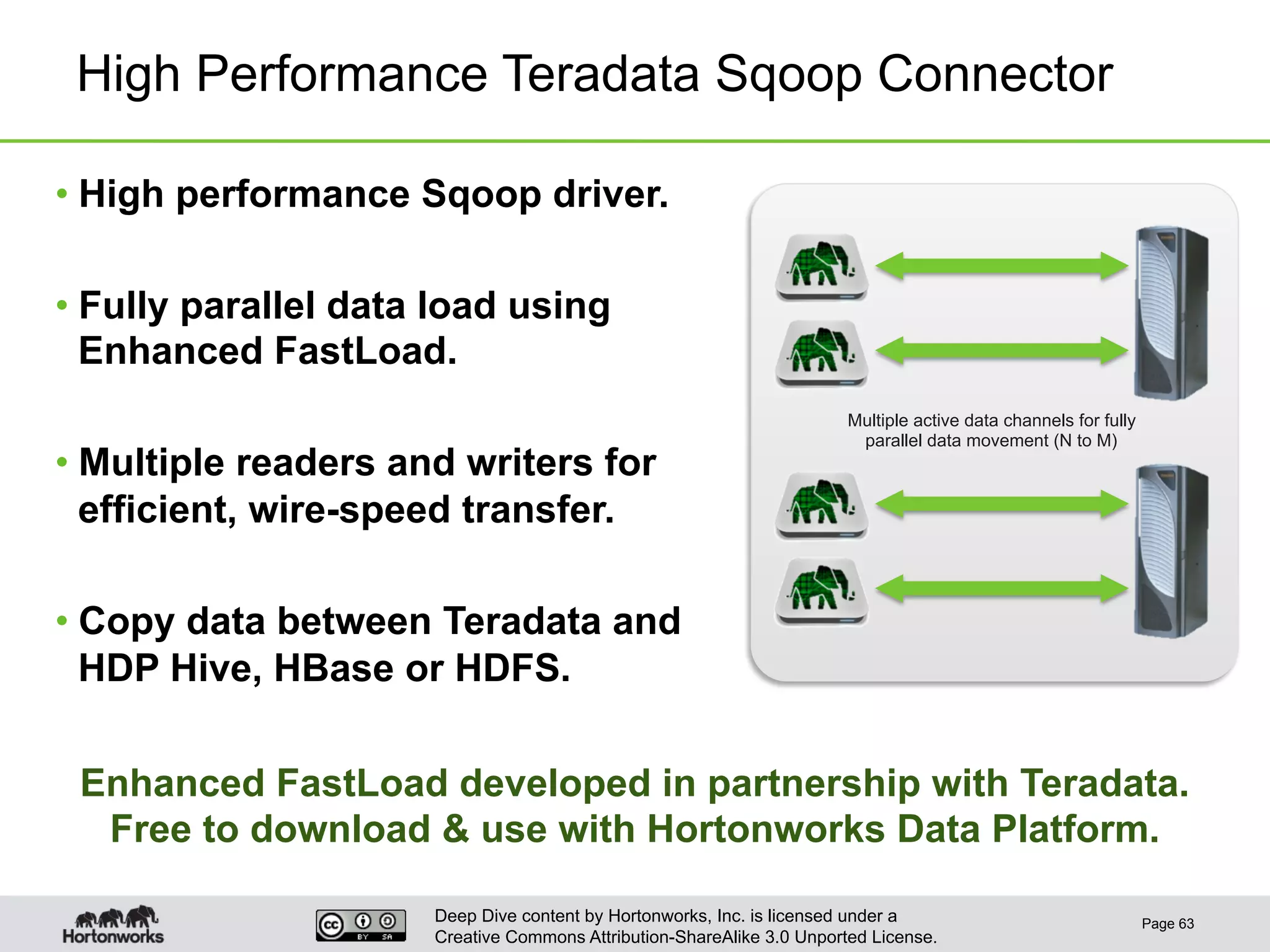






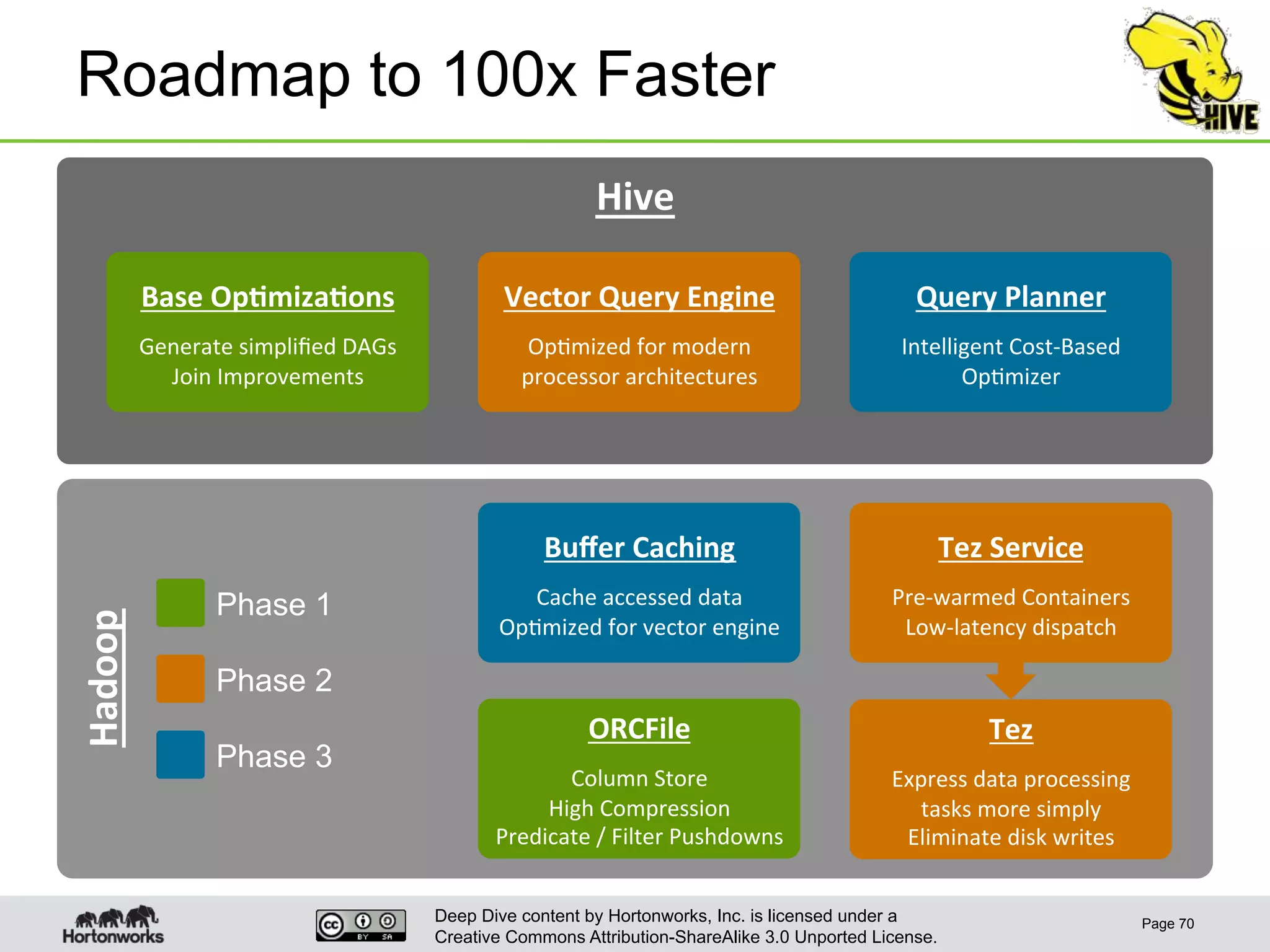



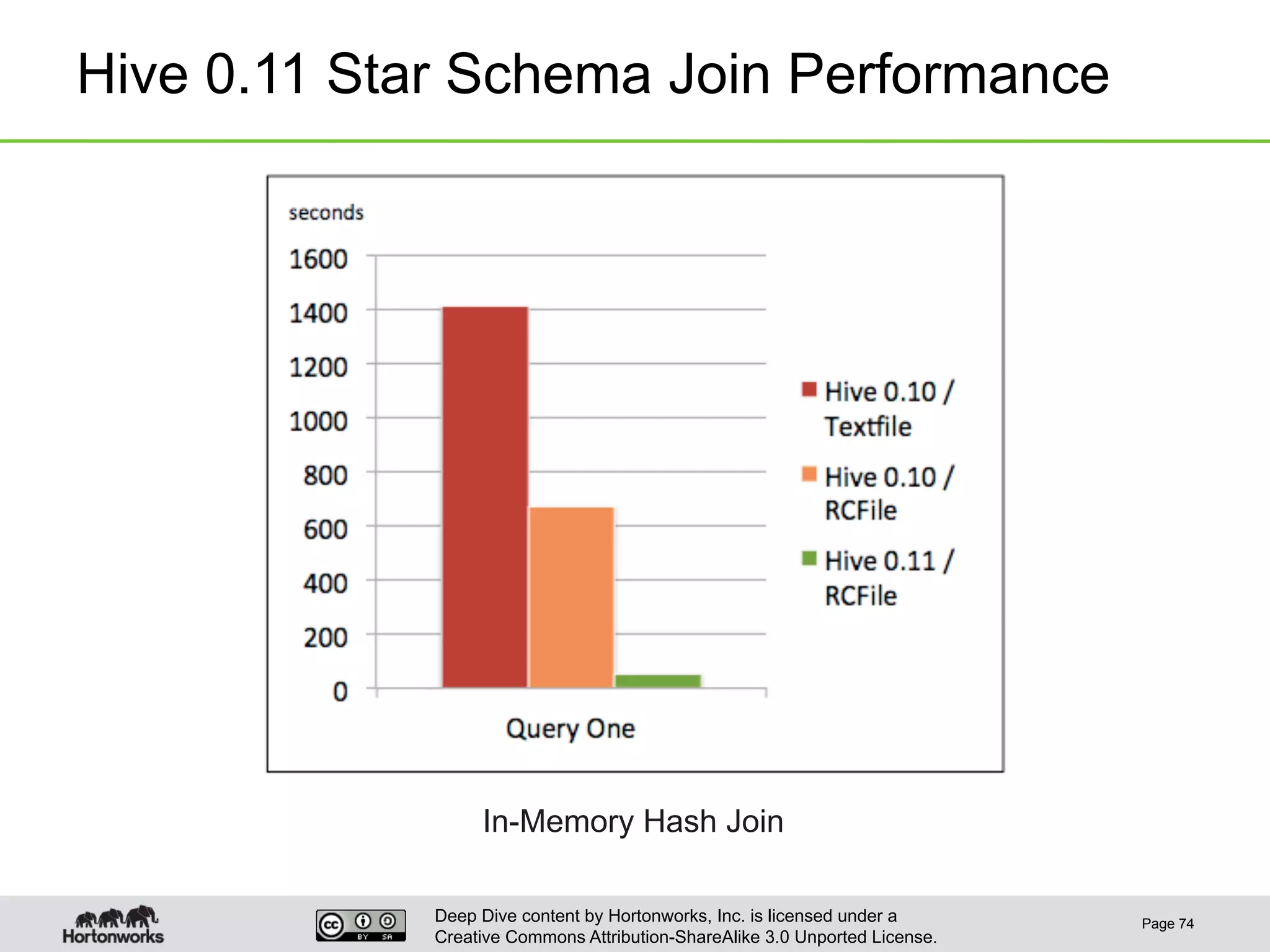
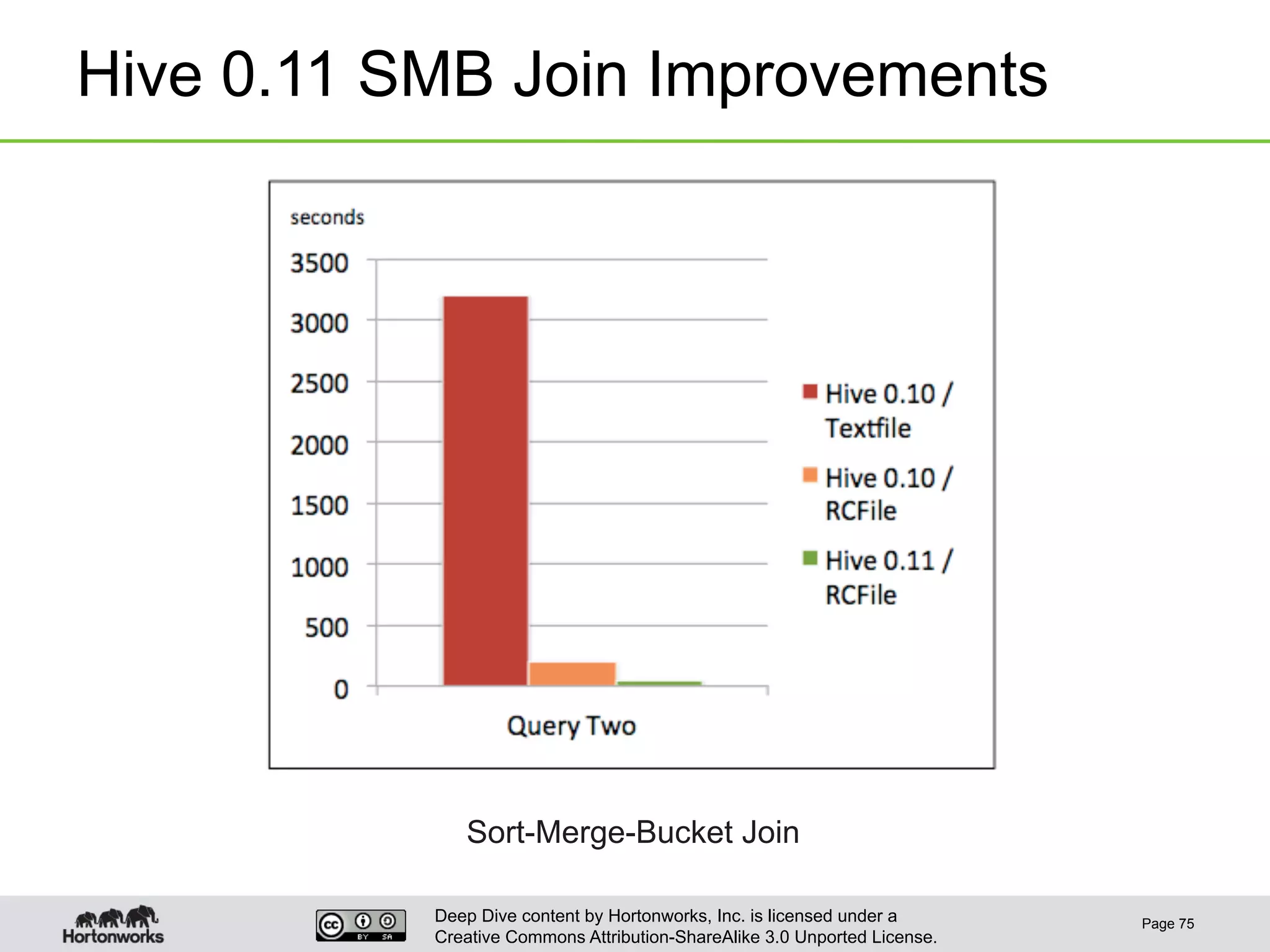
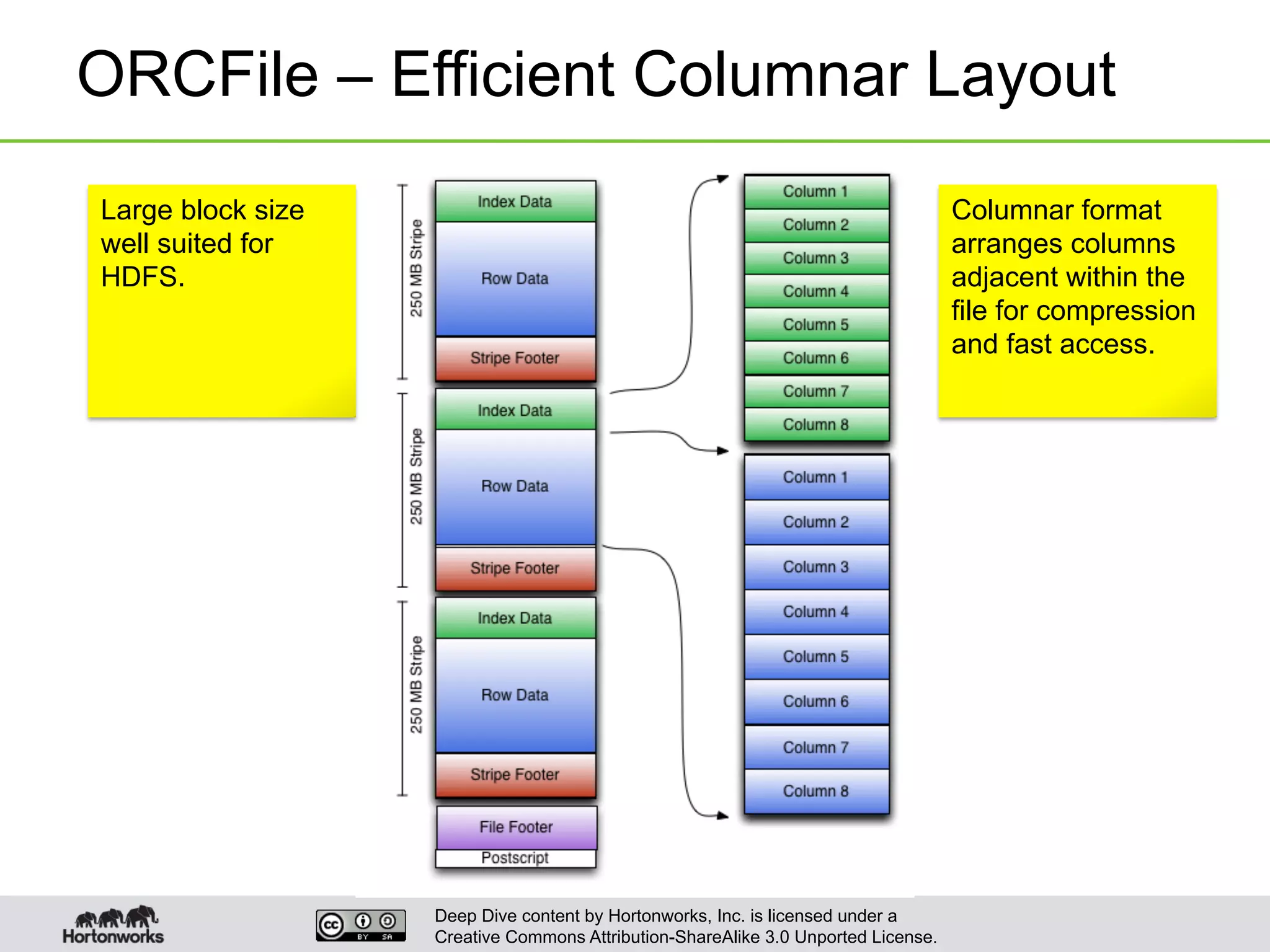
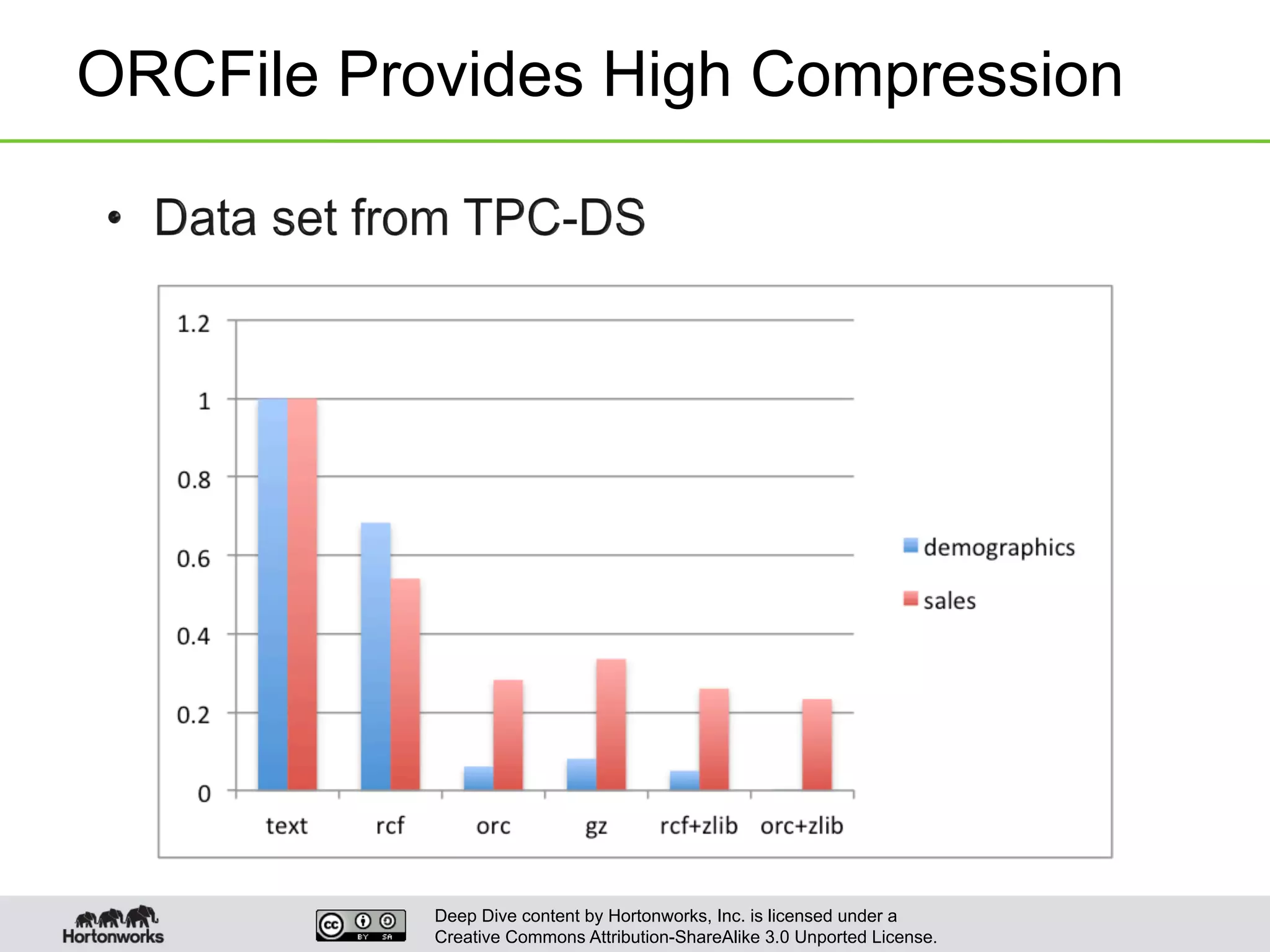



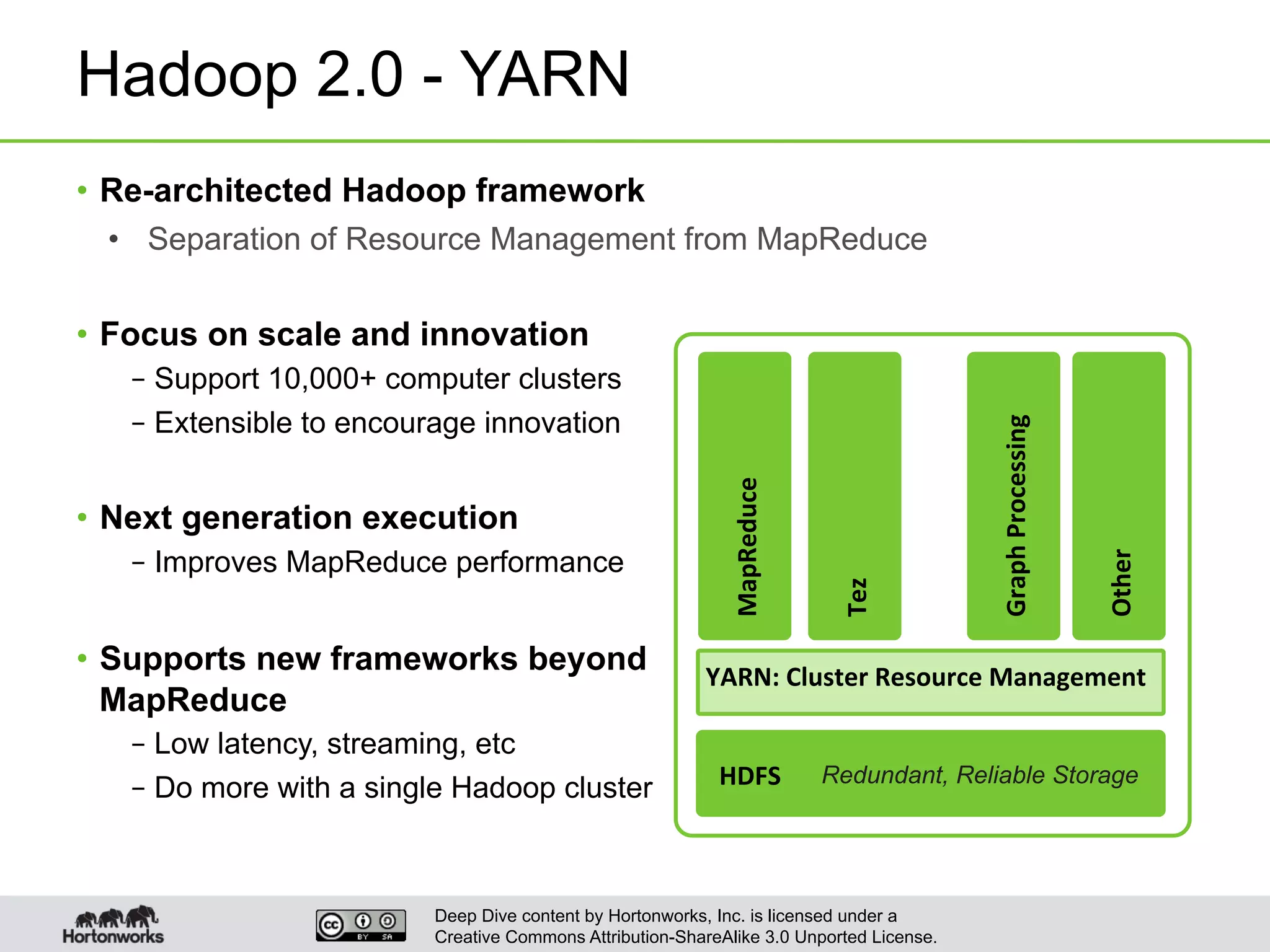

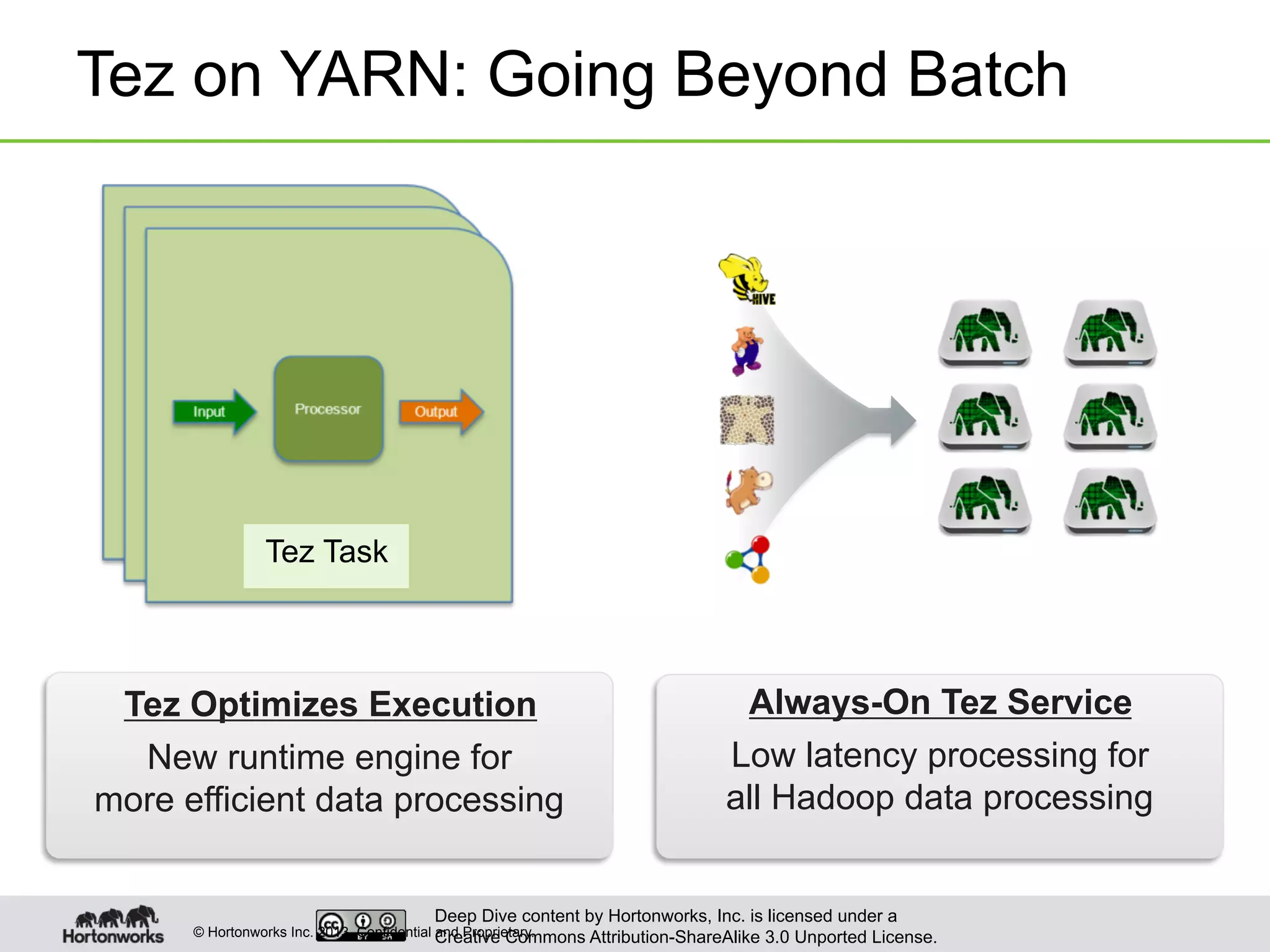
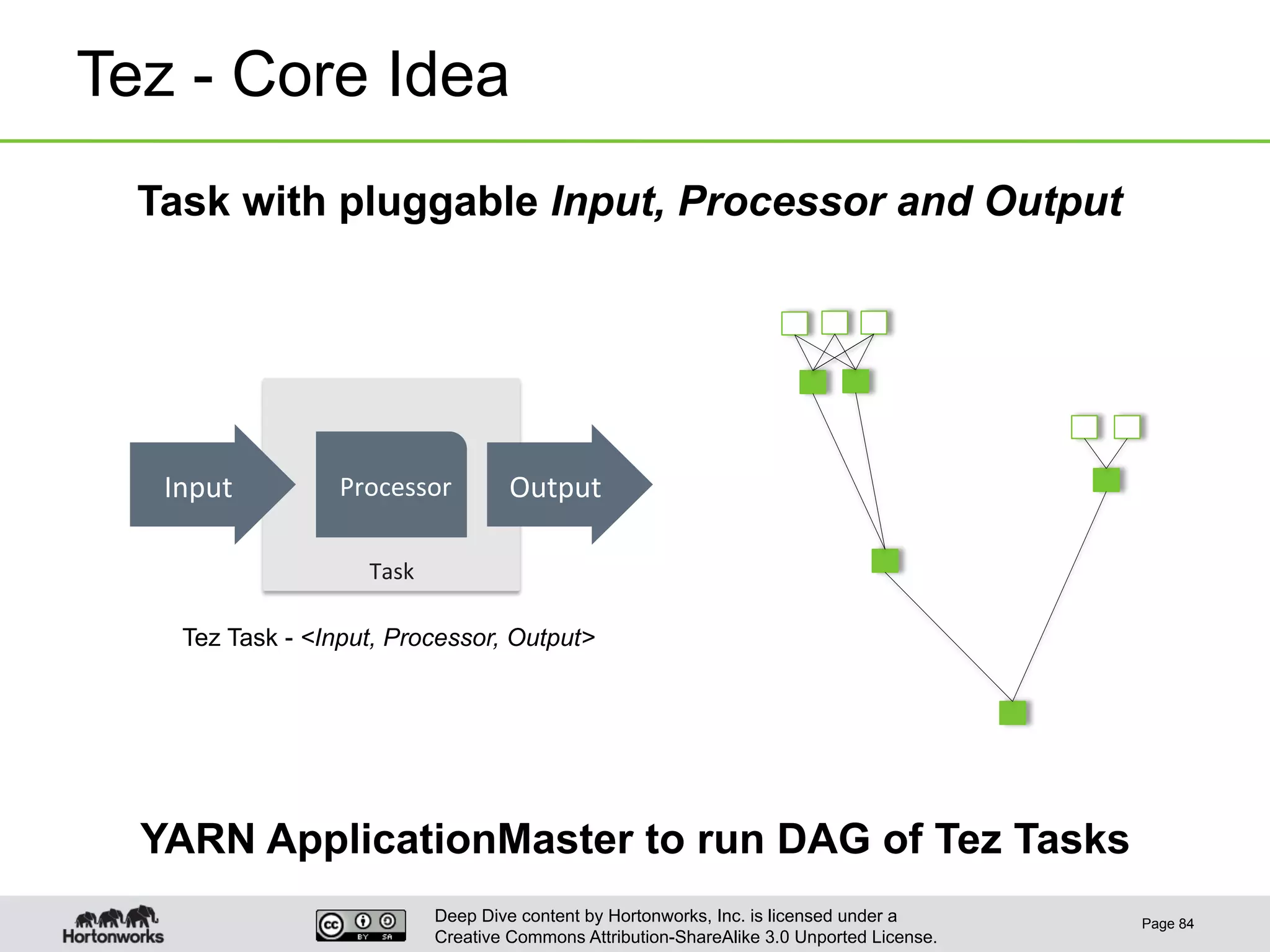
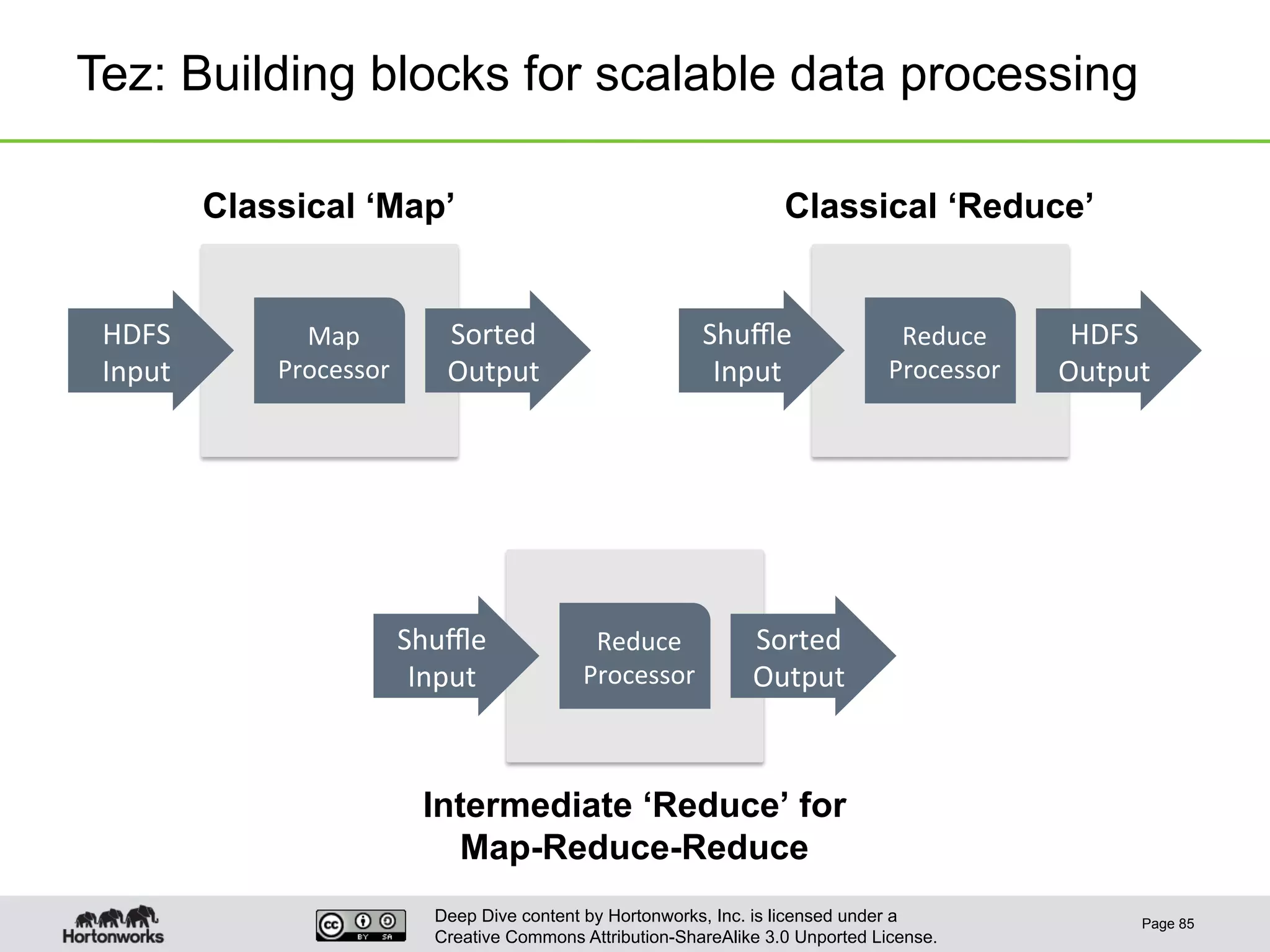
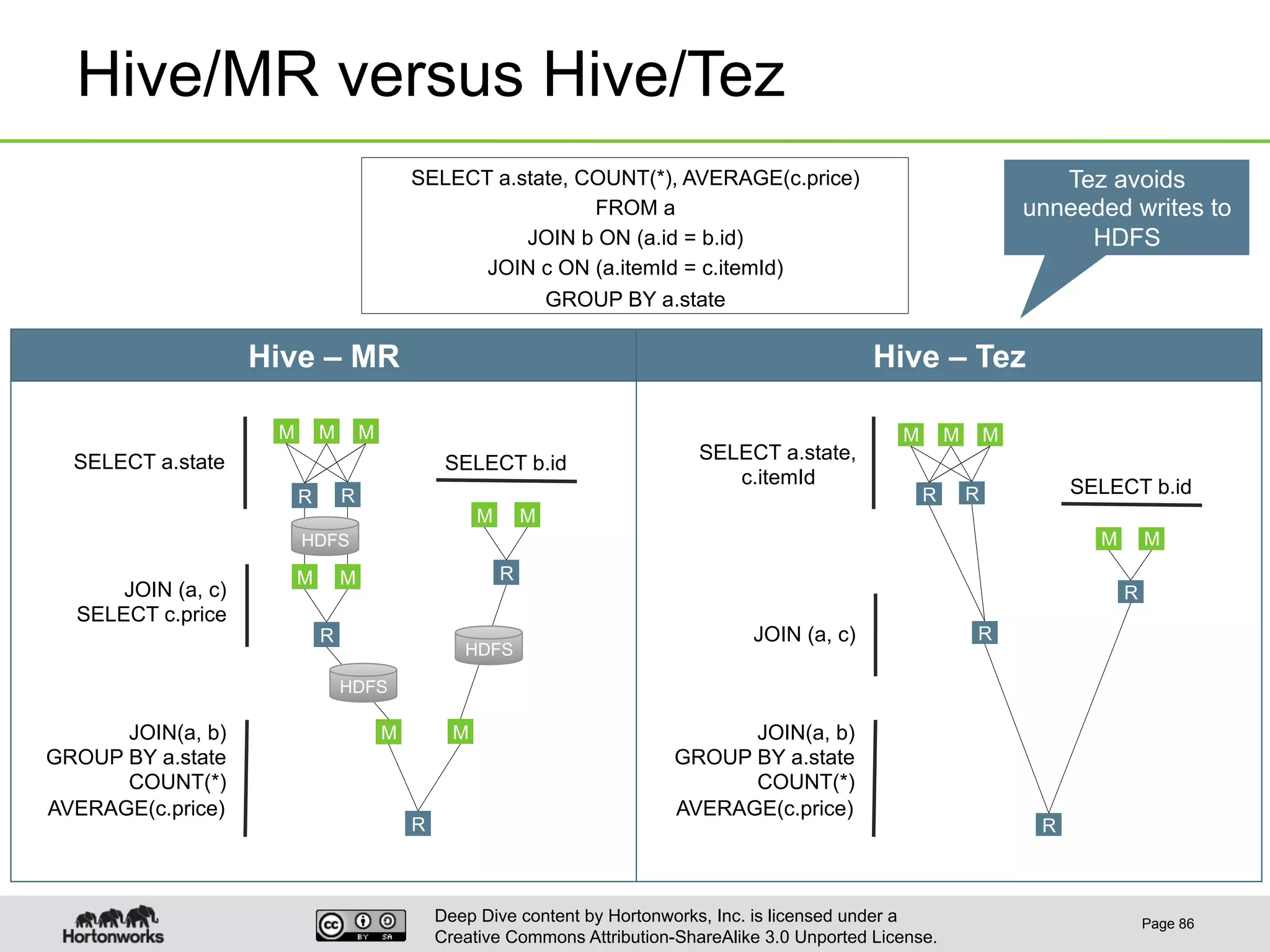





This document provides an overview of Hive and its performance capabilities. It discusses Hive's SQL interface for querying large datasets stored in Hadoop, its architecture which compiles SQL queries into MapReduce jobs, and its support for SQL features. The document also covers techniques for optimizing Hive performance, including data abstractions like partitions, buckets and skews. It describes different join strategies in Hive like shuffle joins, broadcast joins and sort-merge bucket joins, and how shuffle joins are implemented in MapReduce.








































































![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)








![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)





