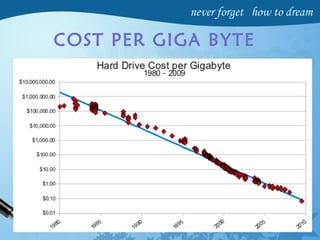
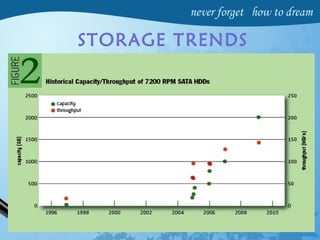
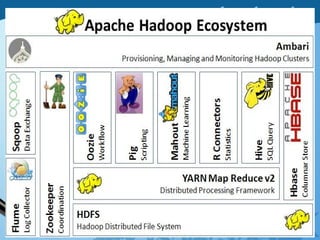
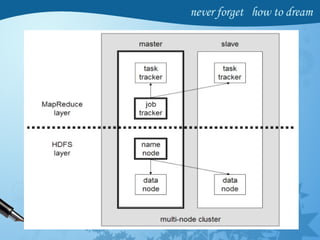
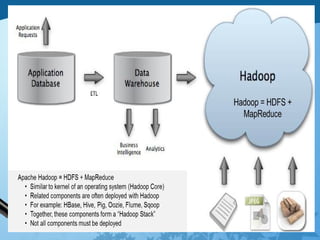
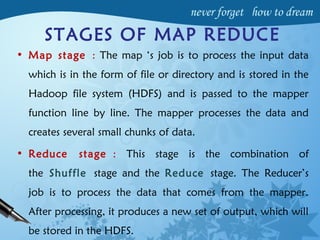
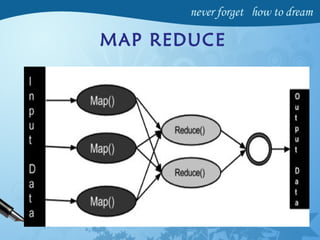
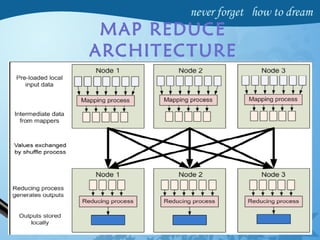
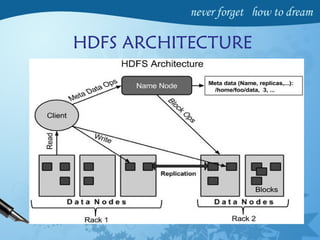
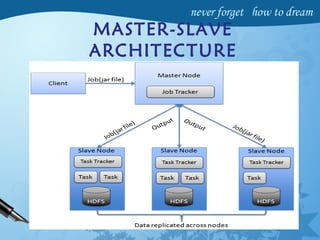
Hadoop is an open-source software framework for distributed storage and processing of large datasets across clusters of computers. It has four main modules - Hadoop Common, HDFS, YARN and MapReduce. HDFS provides a distributed file system that stores data reliably across commodity hardware. MapReduce is a programming model used to process large amounts of data in parallel. Hadoop architecture uses a master-slave model, with a NameNode master and DataNode slaves. It provides fault tolerance, high throughput access to application data and scales to thousands of machines.