







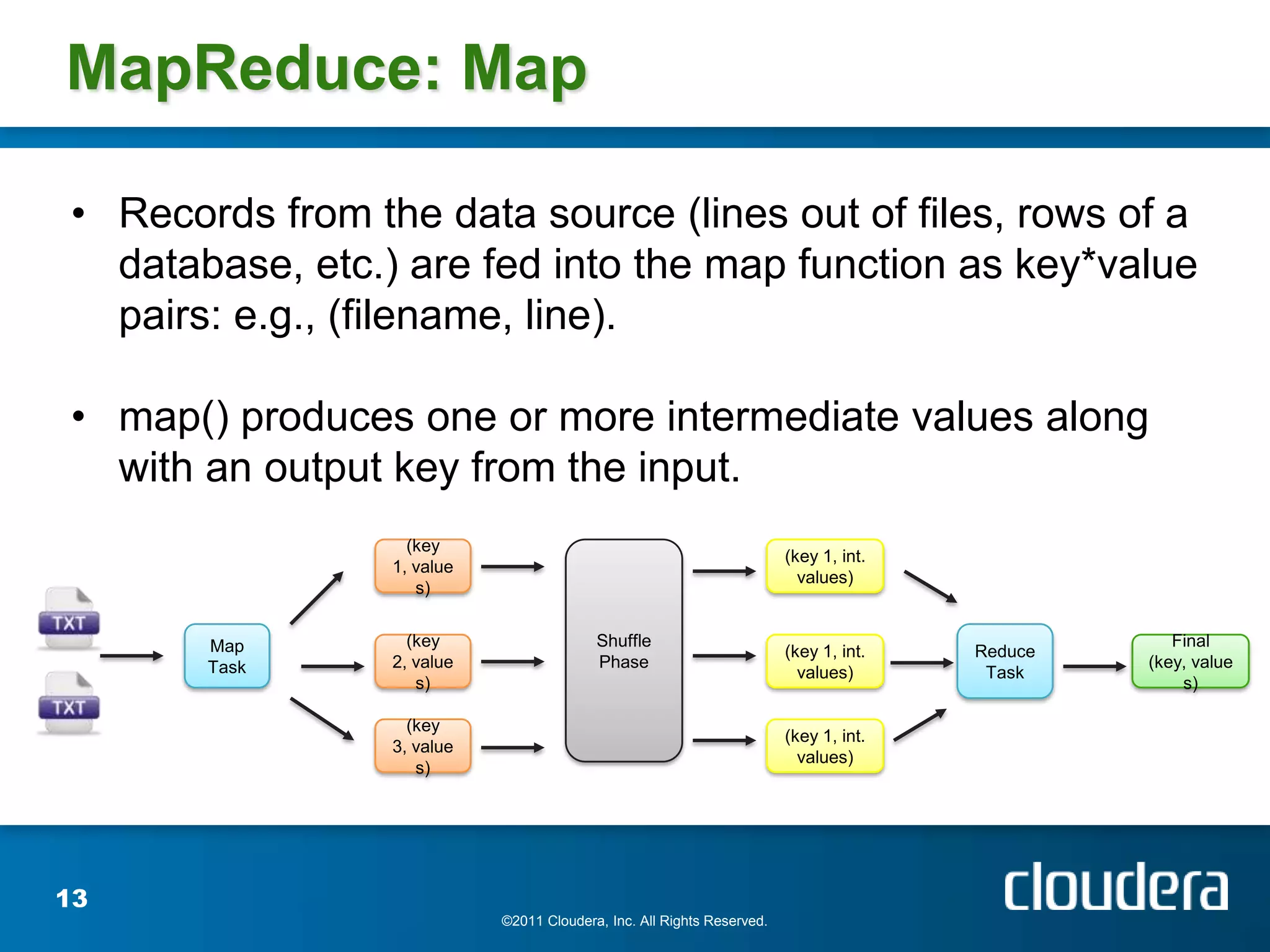
![MapReduce: WordCount
Input text: The cat sat on the mat. The aardvark sat on the sofa.
Mapping Shuffling Reducing
The, 1 aardvark, 1 aardvark, 1
cat, 1
cat, 1 Final Result
sat, 1 cat, 1
on, 1 aardvark, 1
the, 1 mat, 1 mat, 1 cat, 1
mat, 1 mat, 1
The, 1 on [1, 1] on, 2 on, 2
aardvark, 1 sat, 2
sat, 1 sat [1, 1] sat, 2 sofa, 1
on, 1 the, 4
the, 1 sofa, 1 sofa, 1
sofa, 1
the [1, 1, 1, 1] the, 4
16
©2011 Cloudera, Inc. All Rights Reserved.](https://image.slidesharecdn.com/clouderaapachehadoop101aug212012tohug-120829062101-phpapp02/75/hadoop-101-aug-21-2012-tohug-16-2048.jpg)
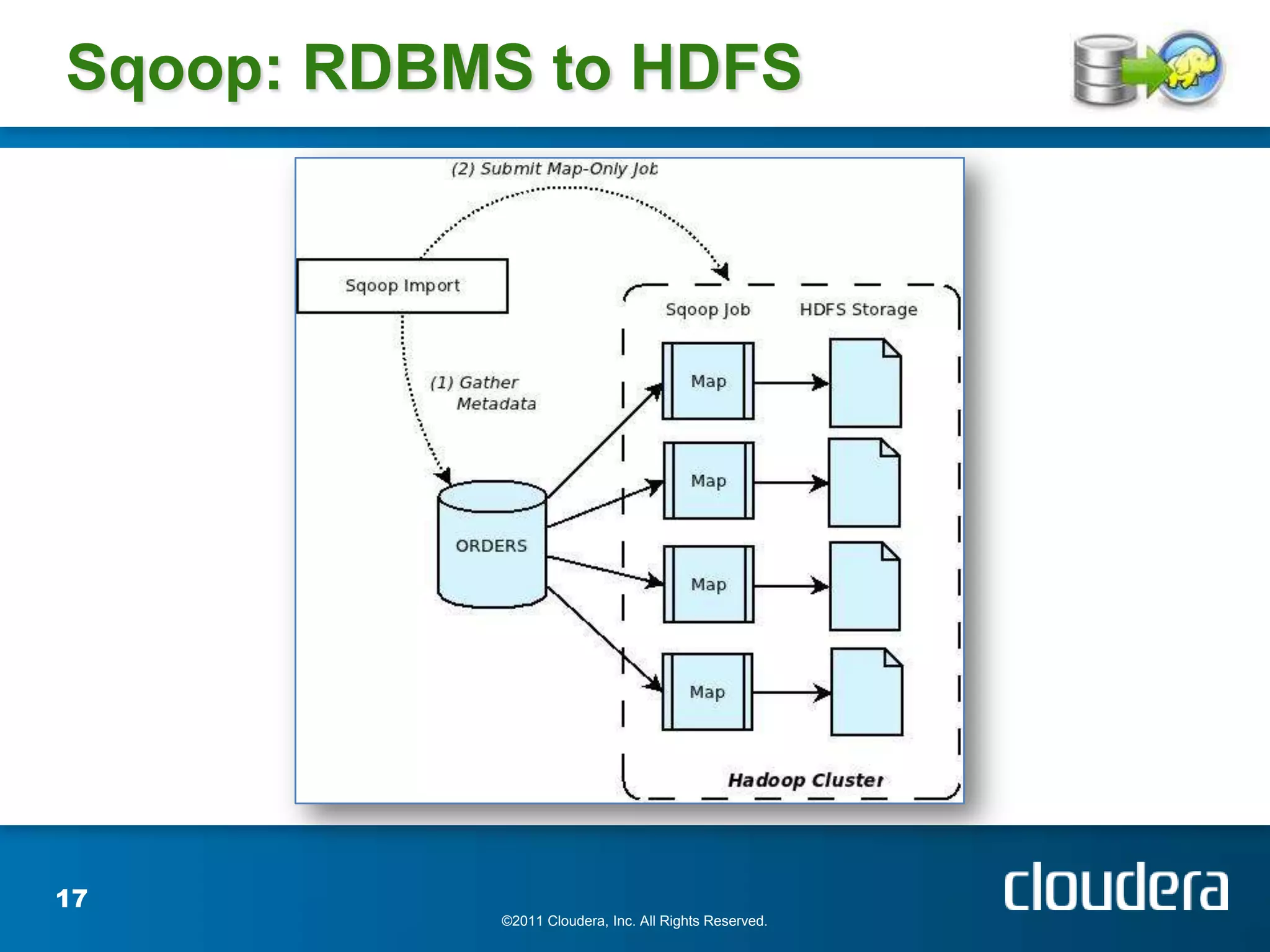
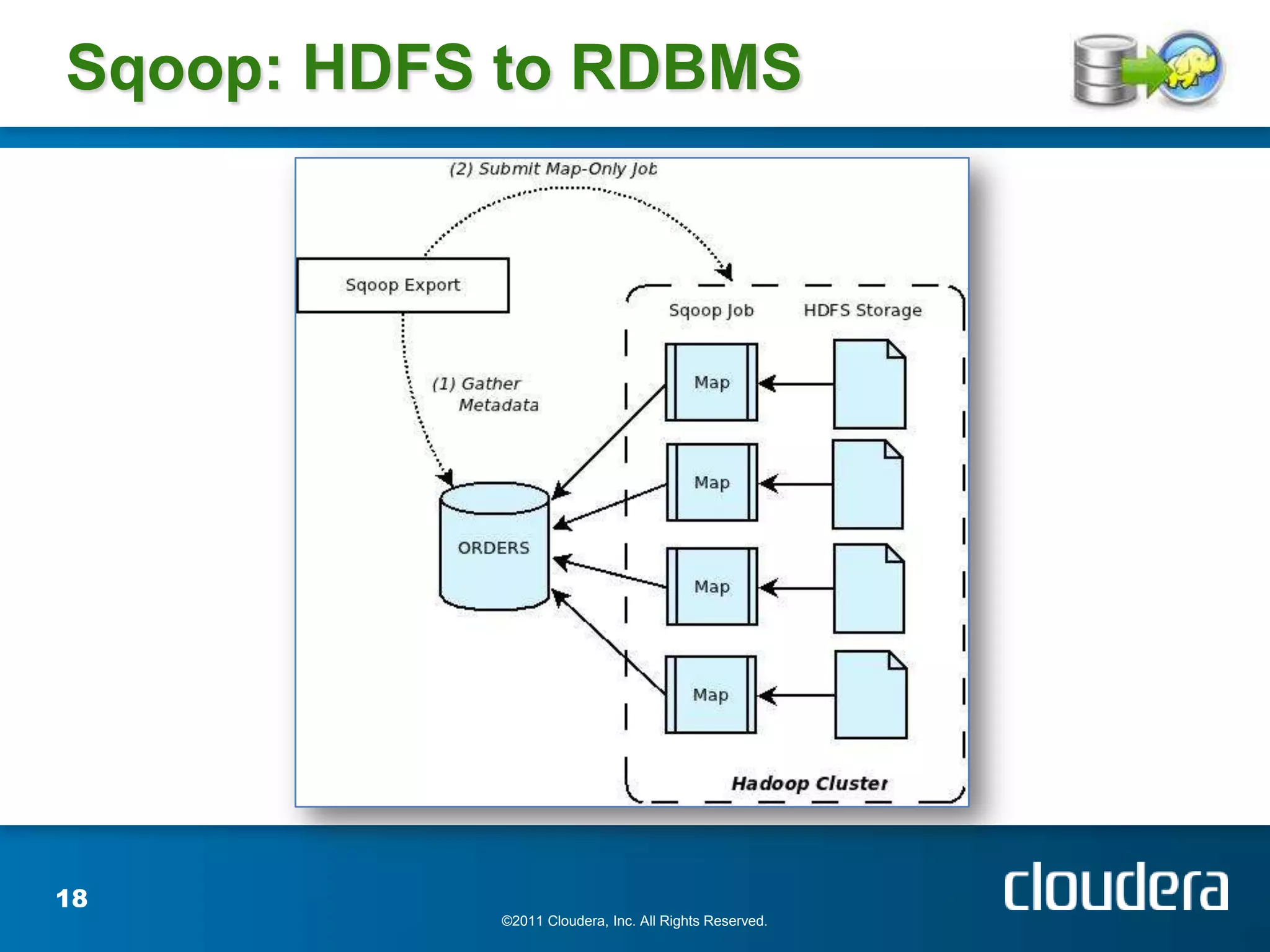
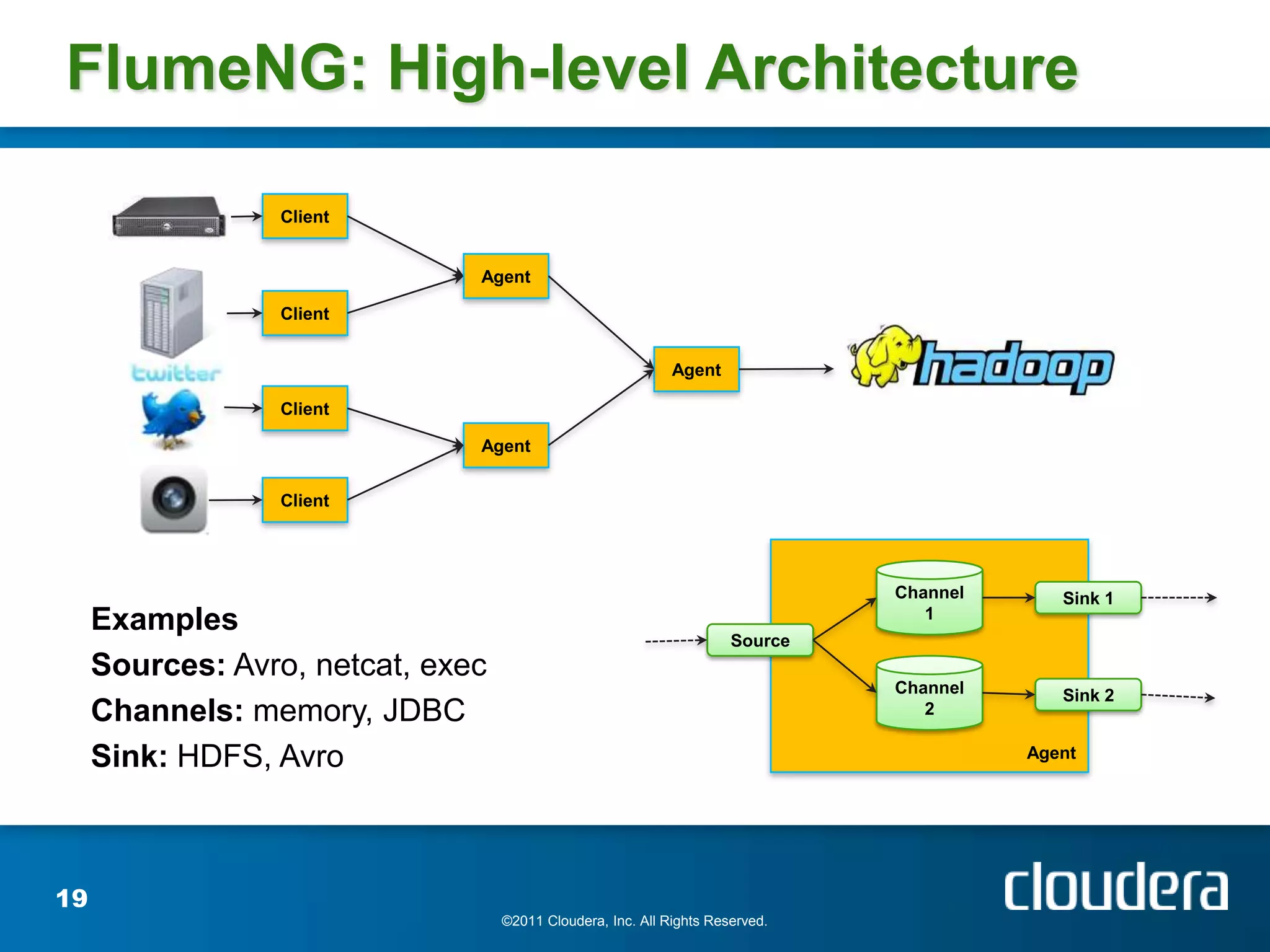
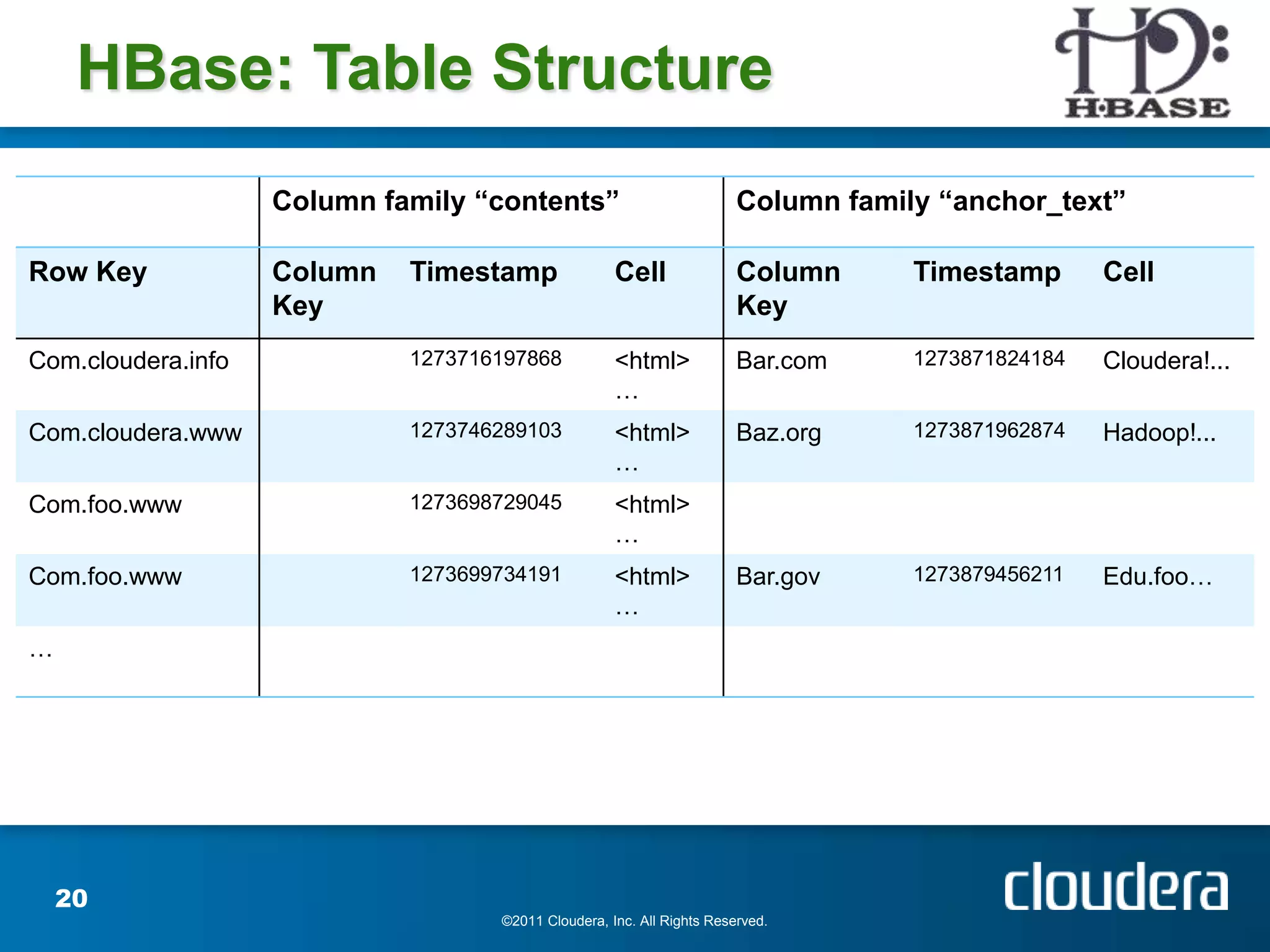
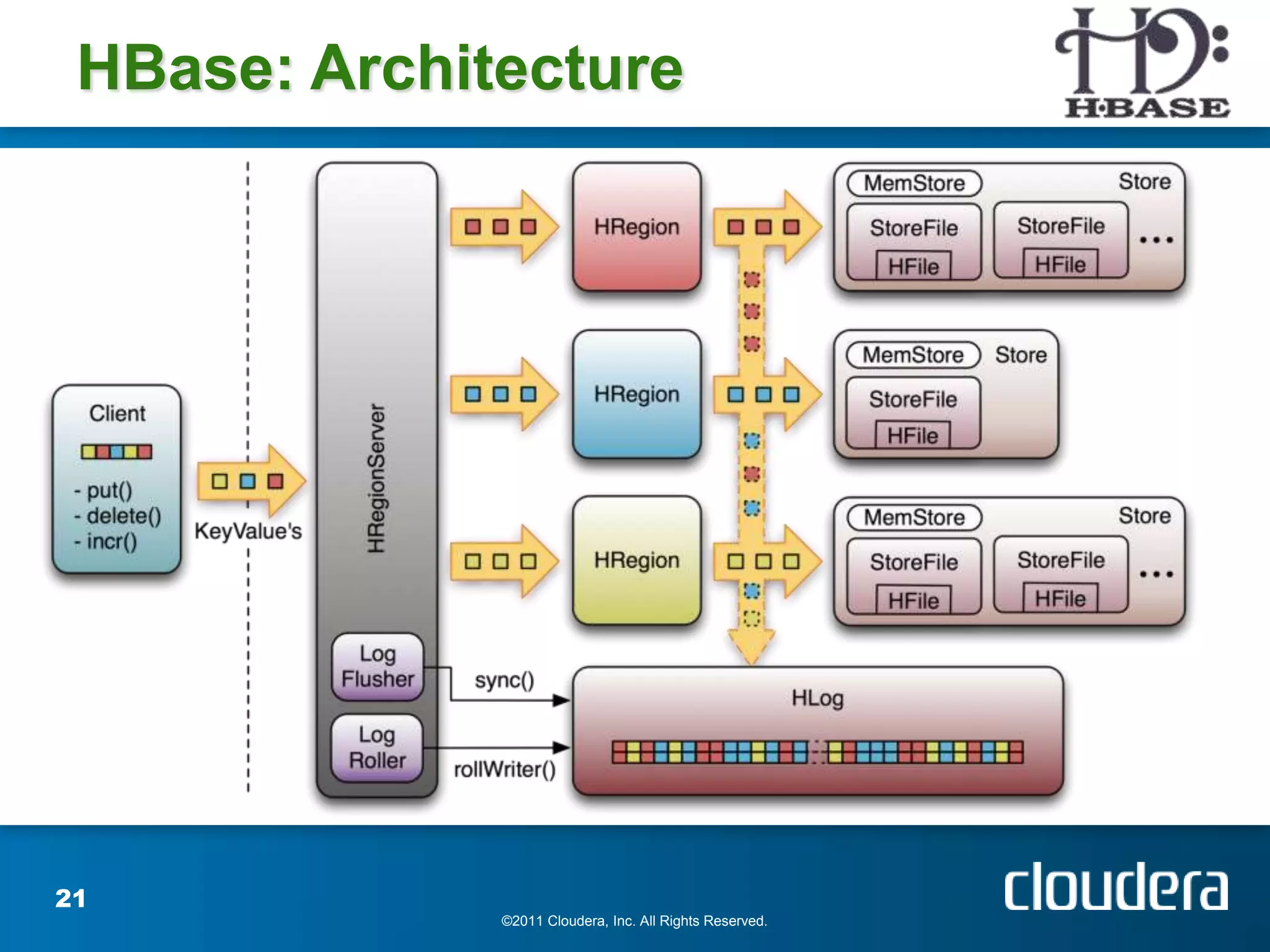


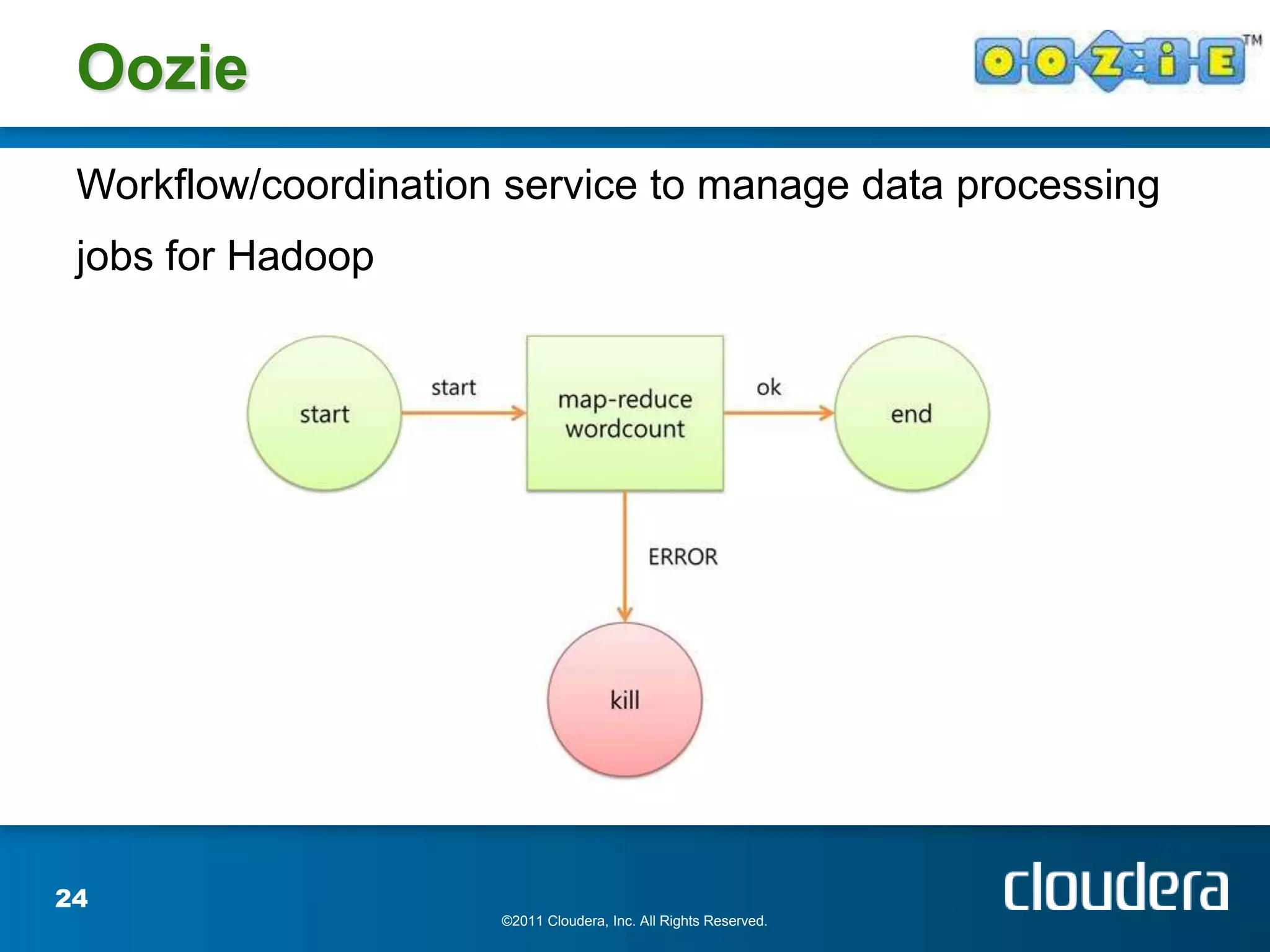
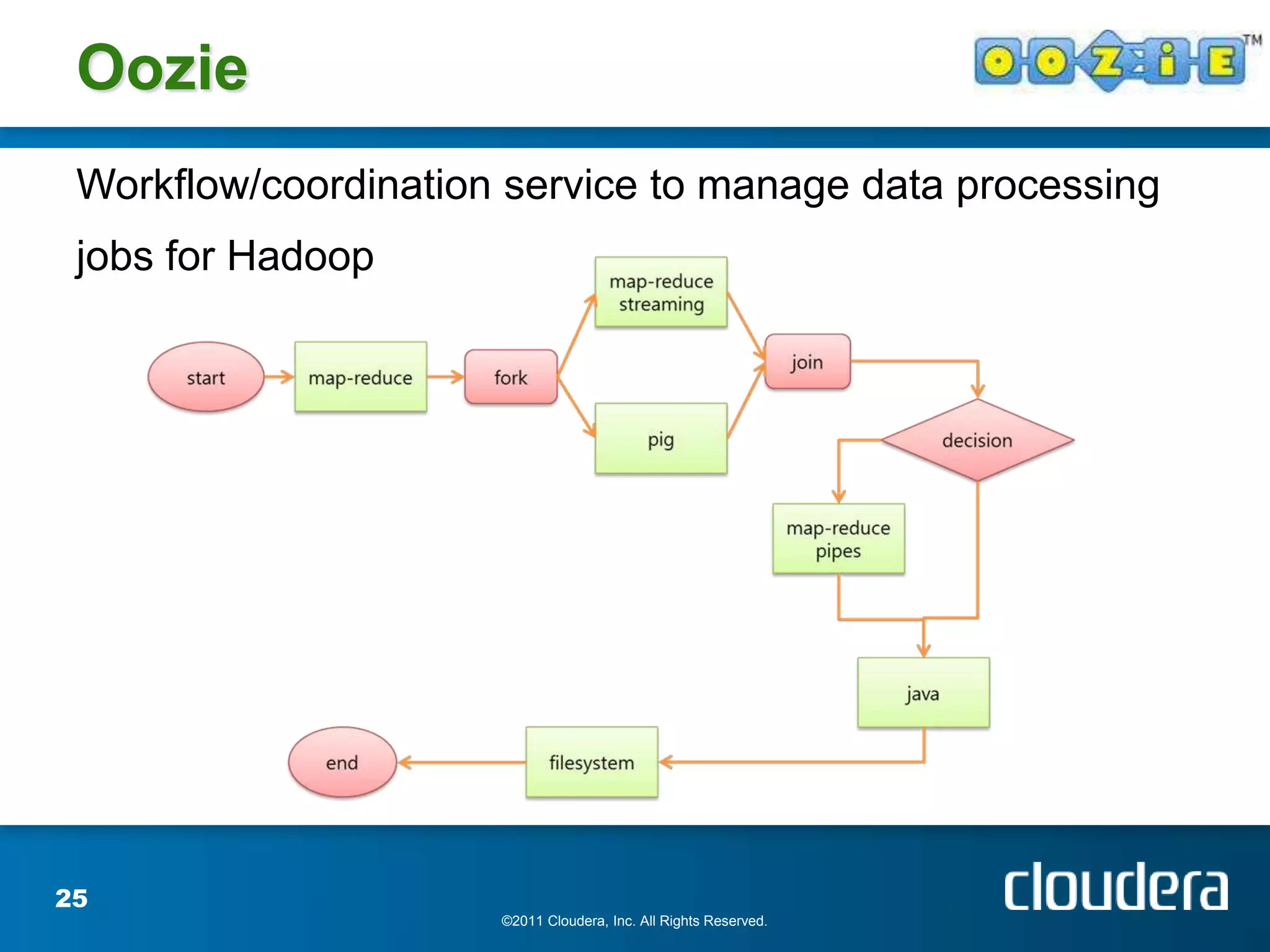




































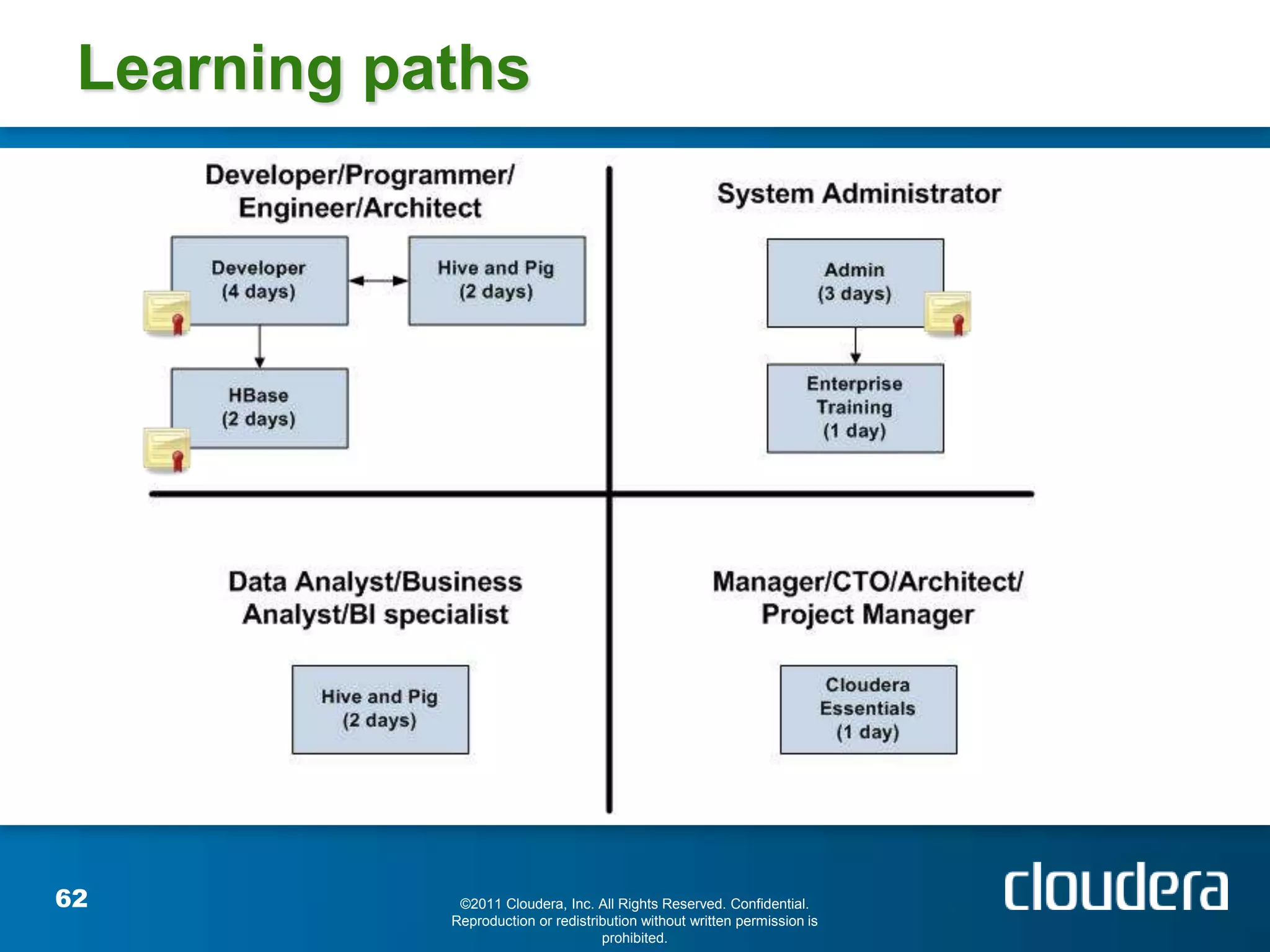

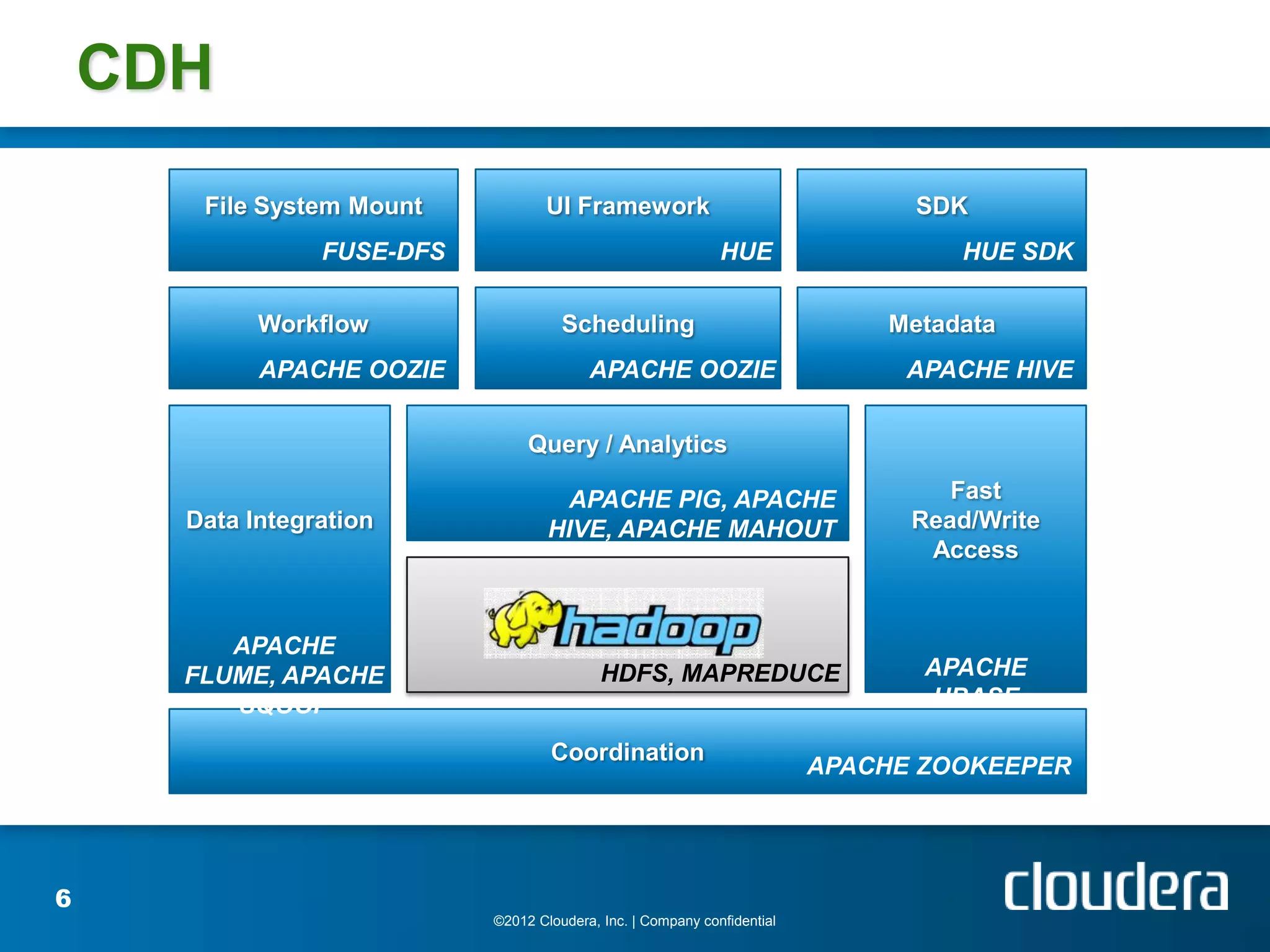
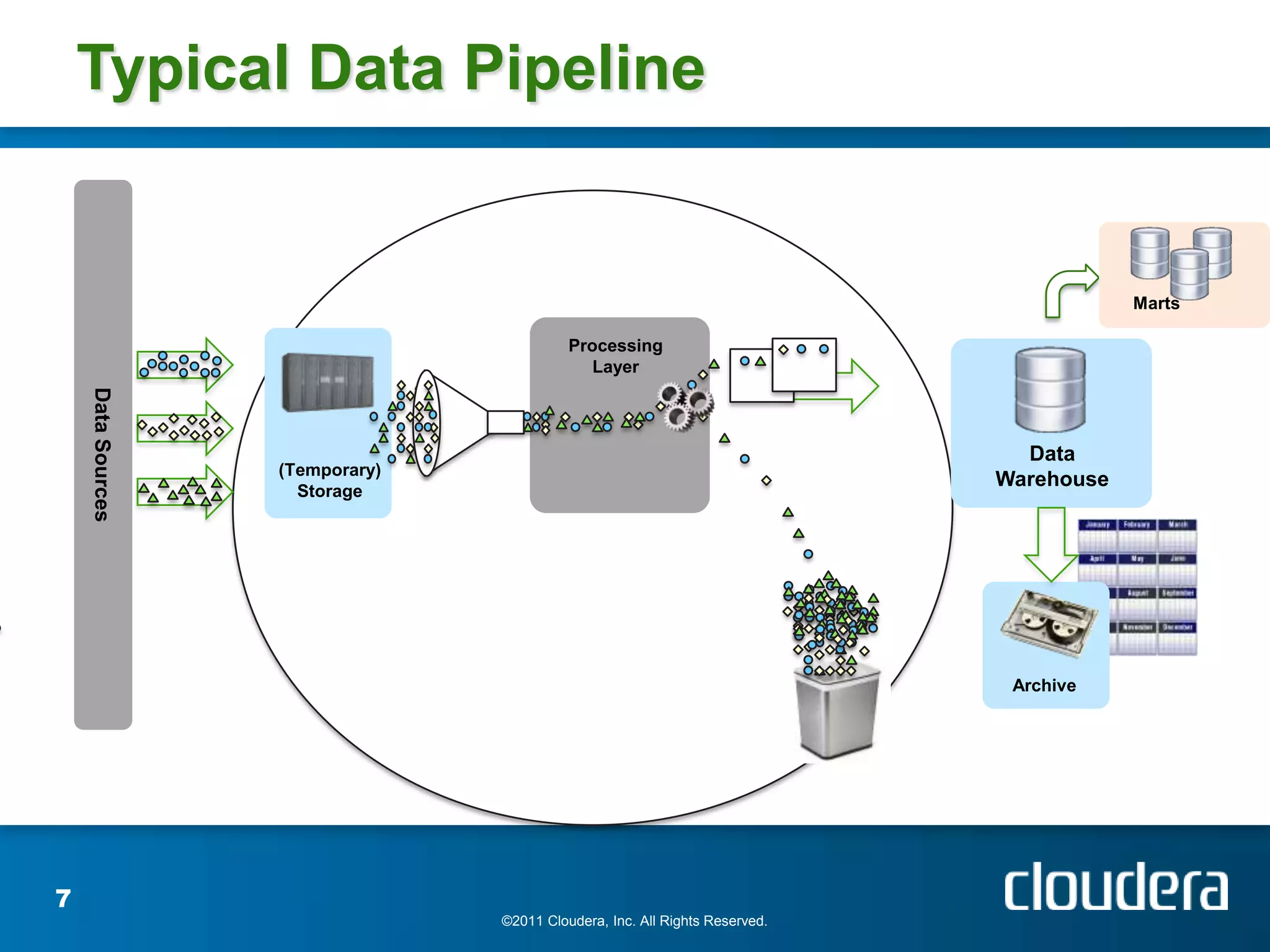
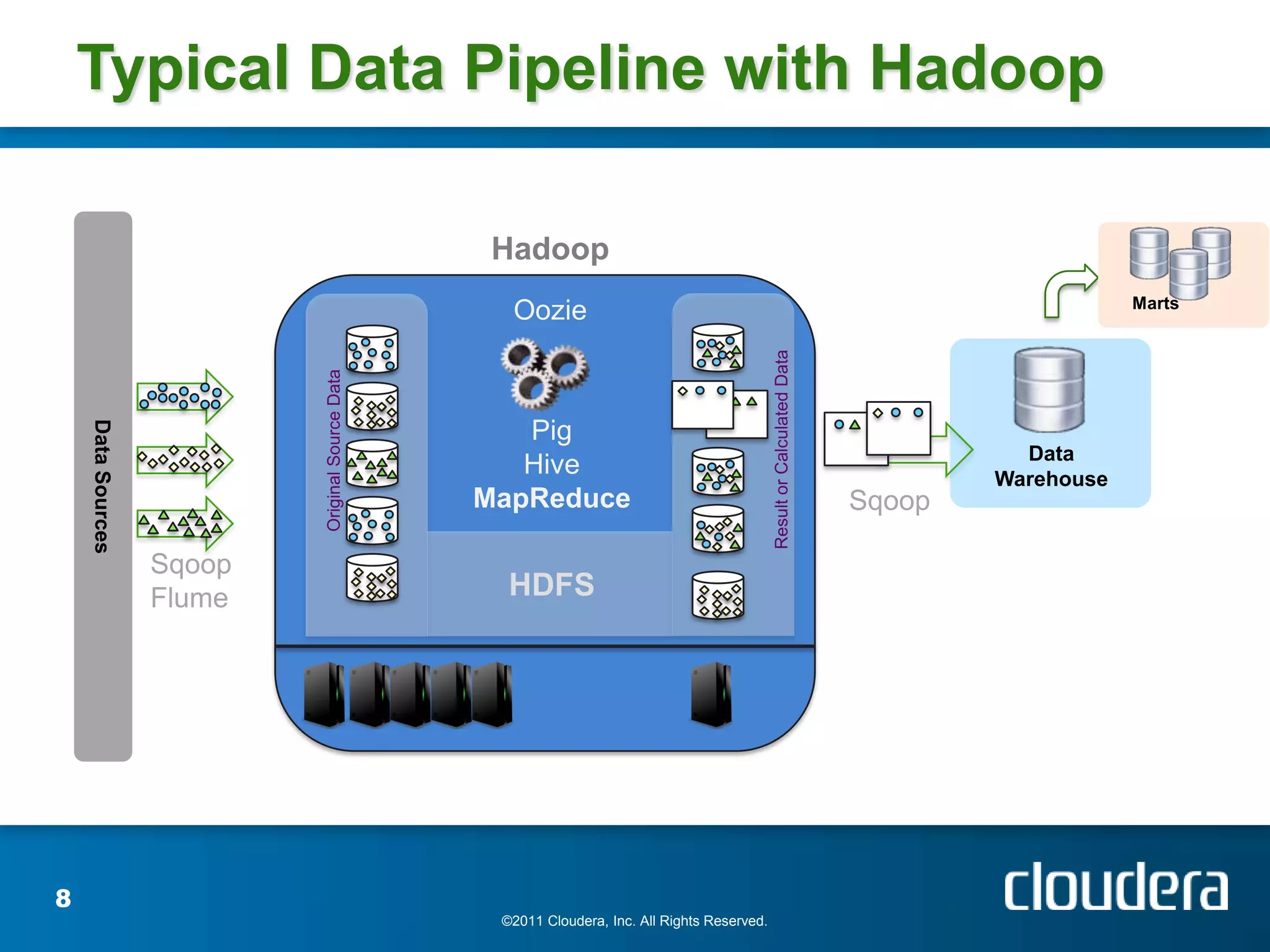
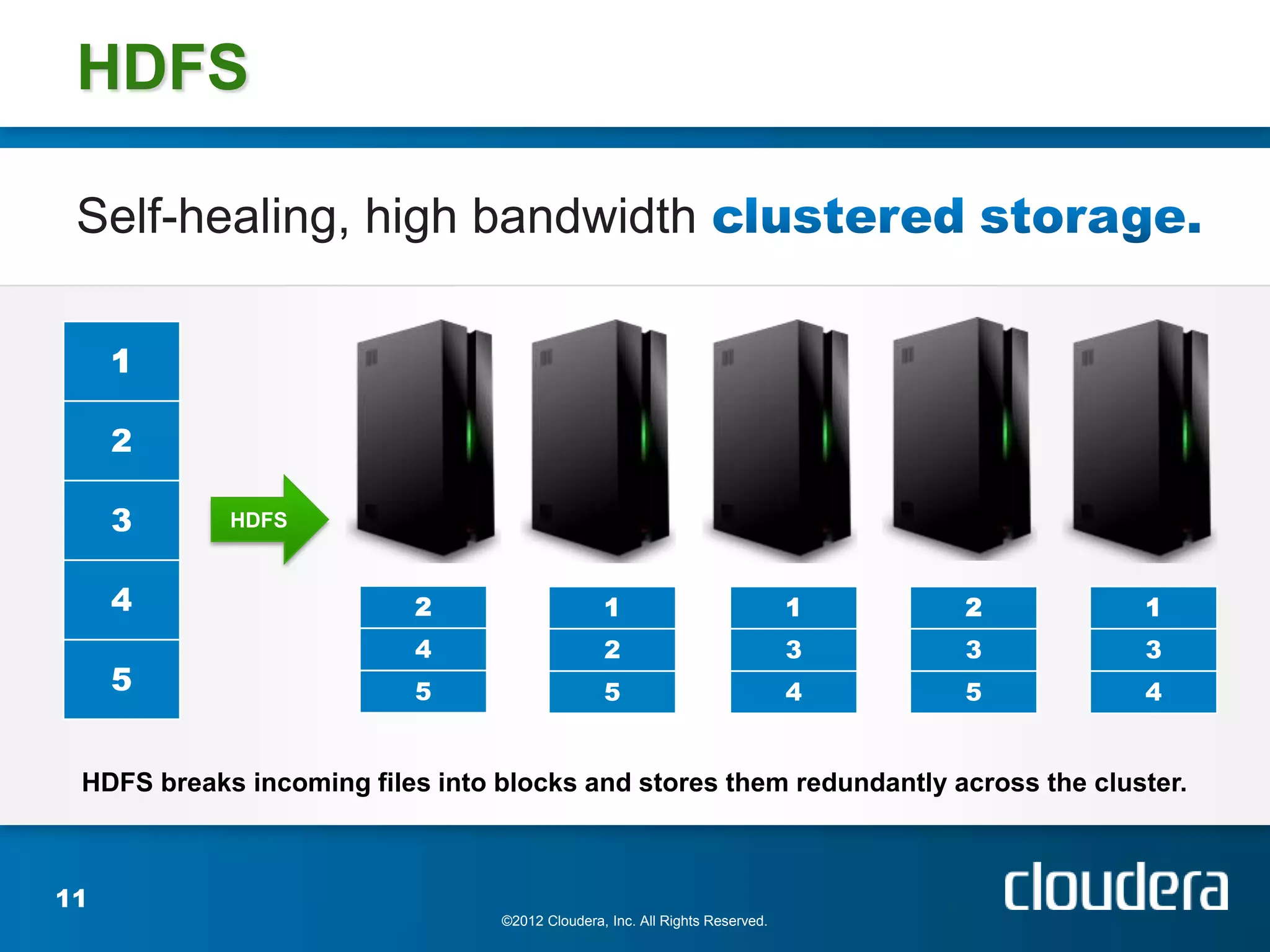
The document provides an introduction to Hadoop concepts including the core projects within Hadoop and how they fit together. It discusses common use cases for Hadoop across different industries and provides examples of how Hadoop can be used for tasks like social network analysis, content optimization, network analytics, and more. The document also summarizes key Hadoop concepts including HDFS, MapReduce, Pig, Hive, HBase and gives examples of how Hadoop can be applied in domains like financial services, science, energy and others.

































































































