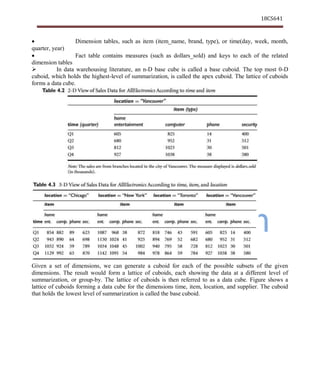
This document discusses key concepts in data warehousing and modeling. It describes a multitier architecture for data warehousing consisting of a bottom tier warehouse database, middle tier OLAP server, and top tier front-end client tools. It also discusses different data warehouse models including enterprise warehouses, data marts, and virtual warehouses. The document outlines the extraction, transformation, and loading process used to populate data warehouses and the role of metadata repositories.









































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)

















