Downloaded 23 times








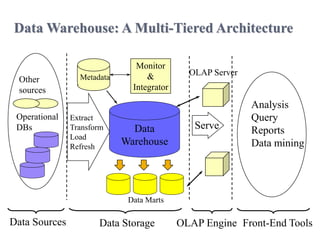










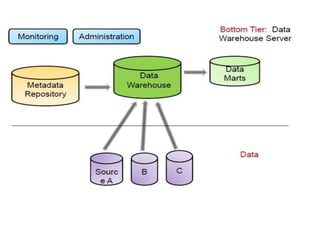



















The document explains that a data warehouse is an architectural construct designed to provide historical and current decision support information through various technologies and components. It distinguishes between operational databases and data warehouses in terms of data organization, access methods, and user types, and categorizes data warehousing processes and models, including multi-dimensional data models and various schemas such as star, snowflake, and fact constellation. Additionally, it discusses performance considerations, including parallel architectures and the importance of optimizing speed and scalability.