Download as ODP, PPTX






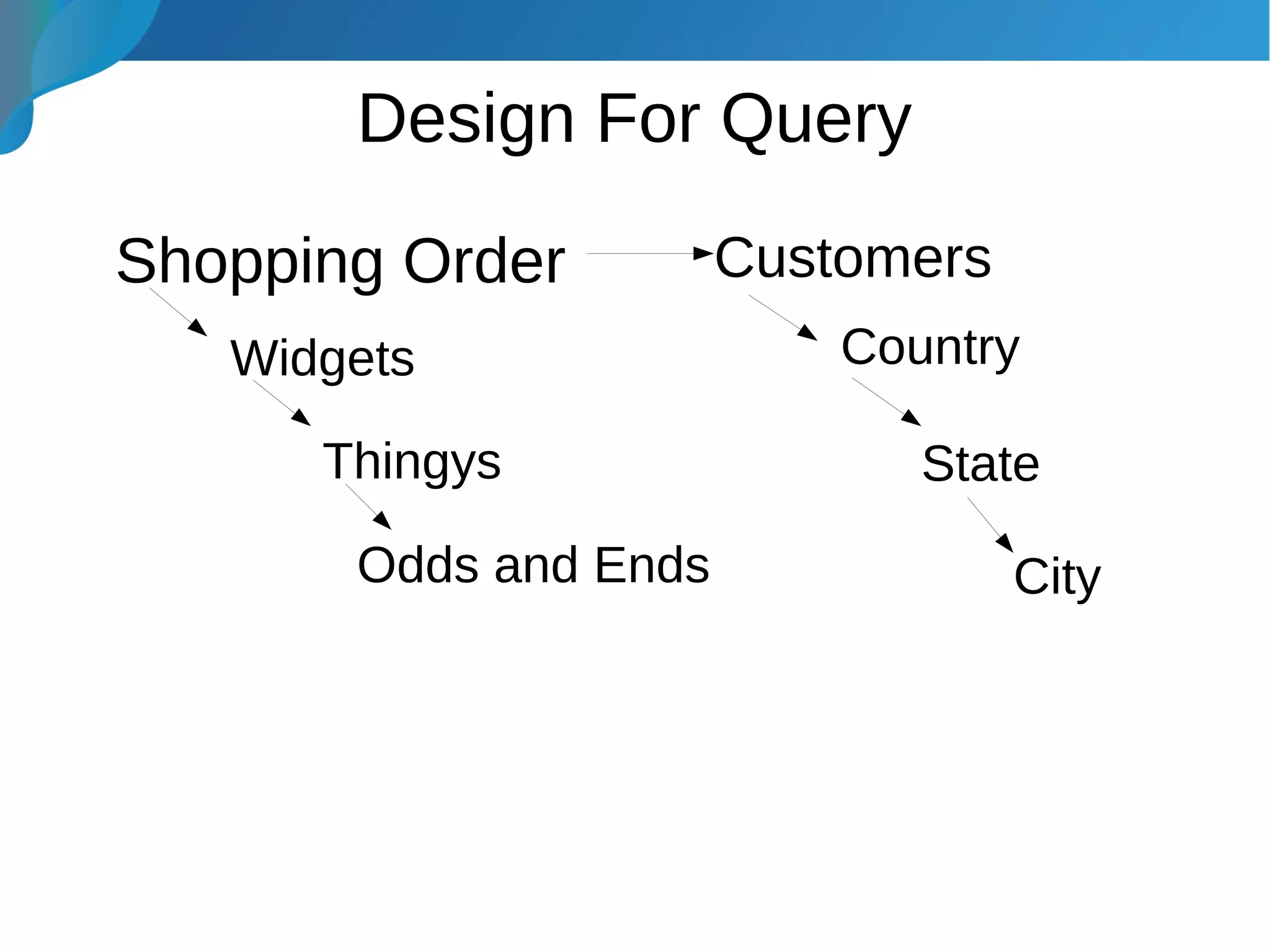

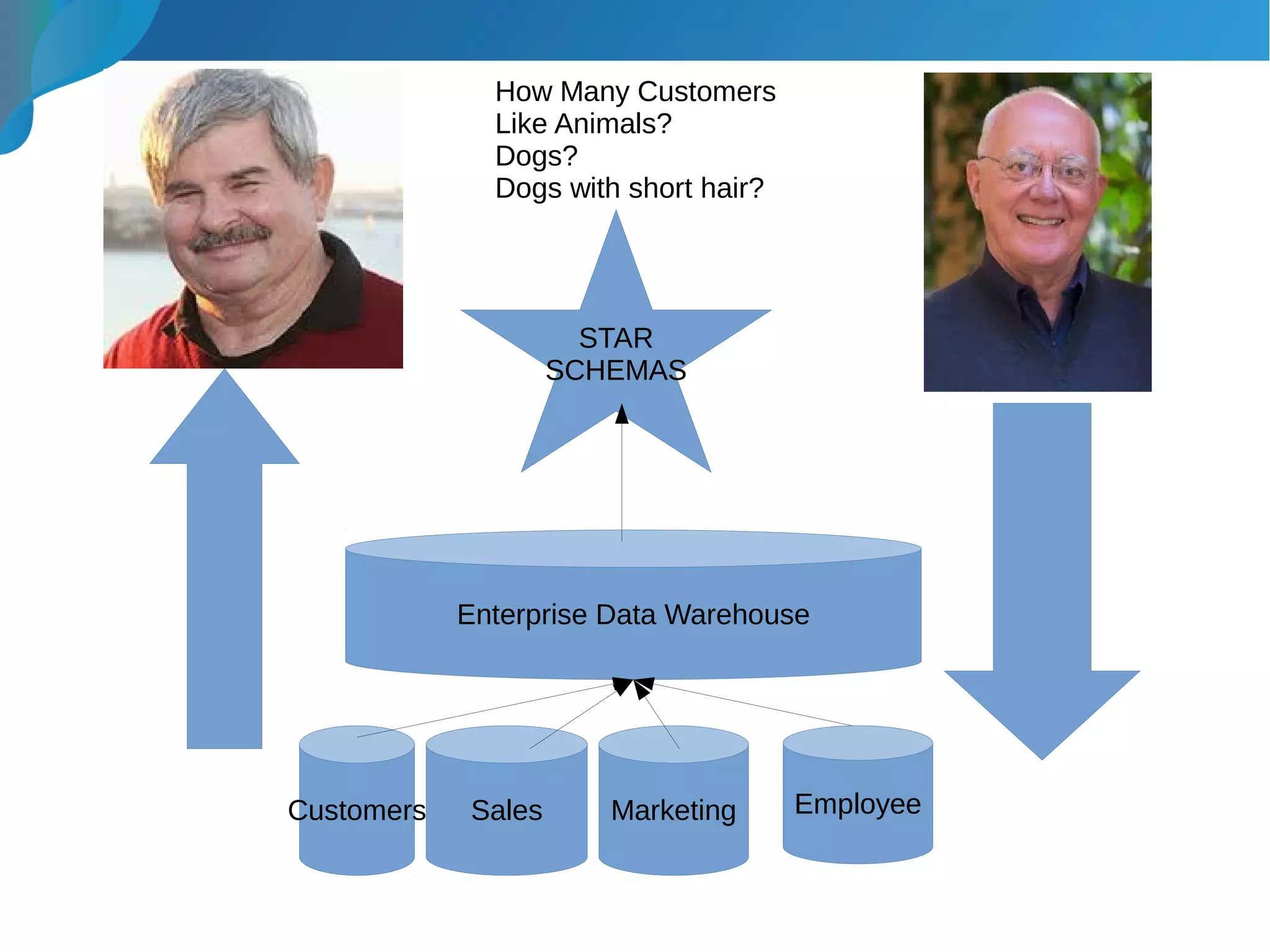
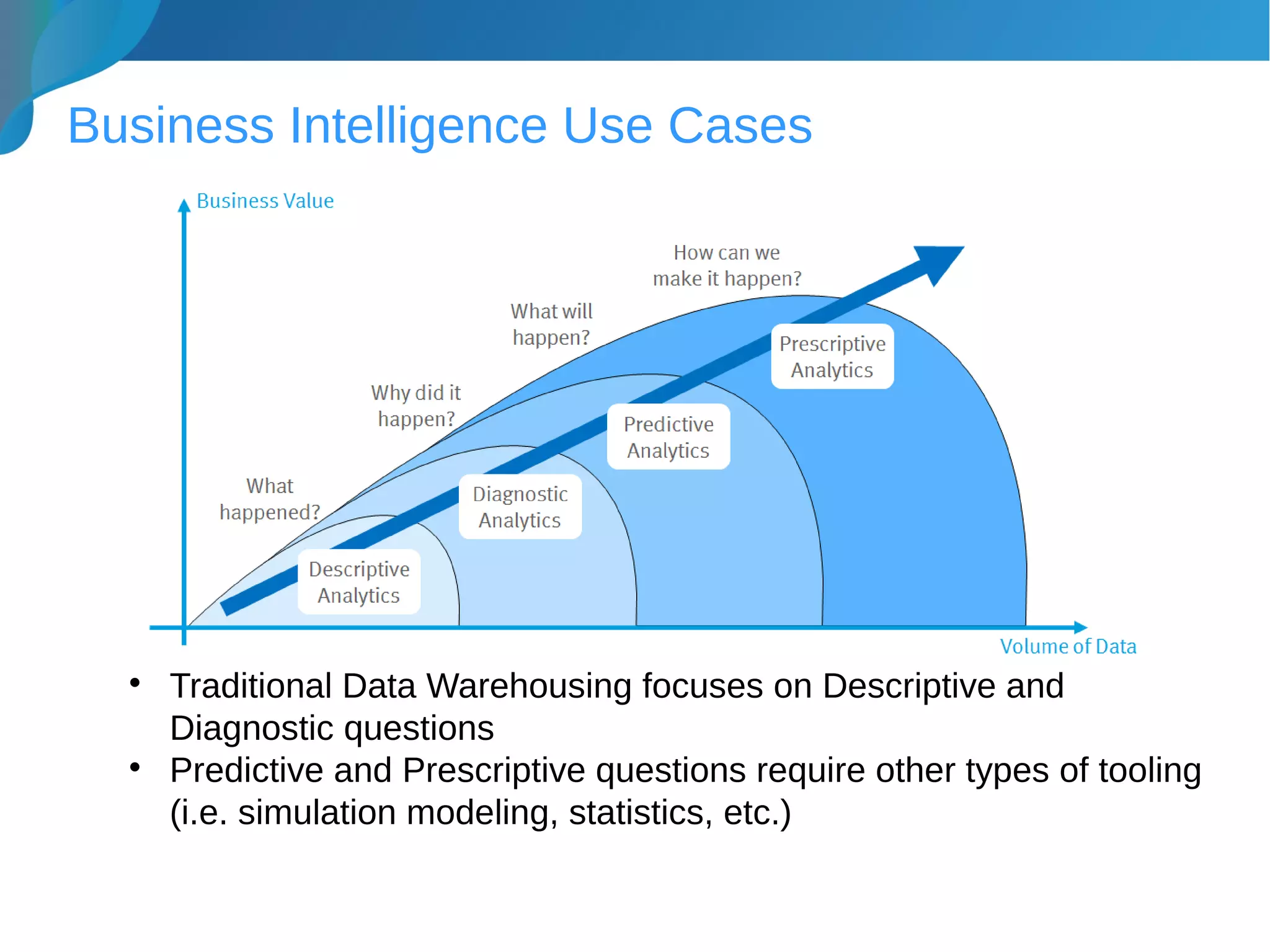








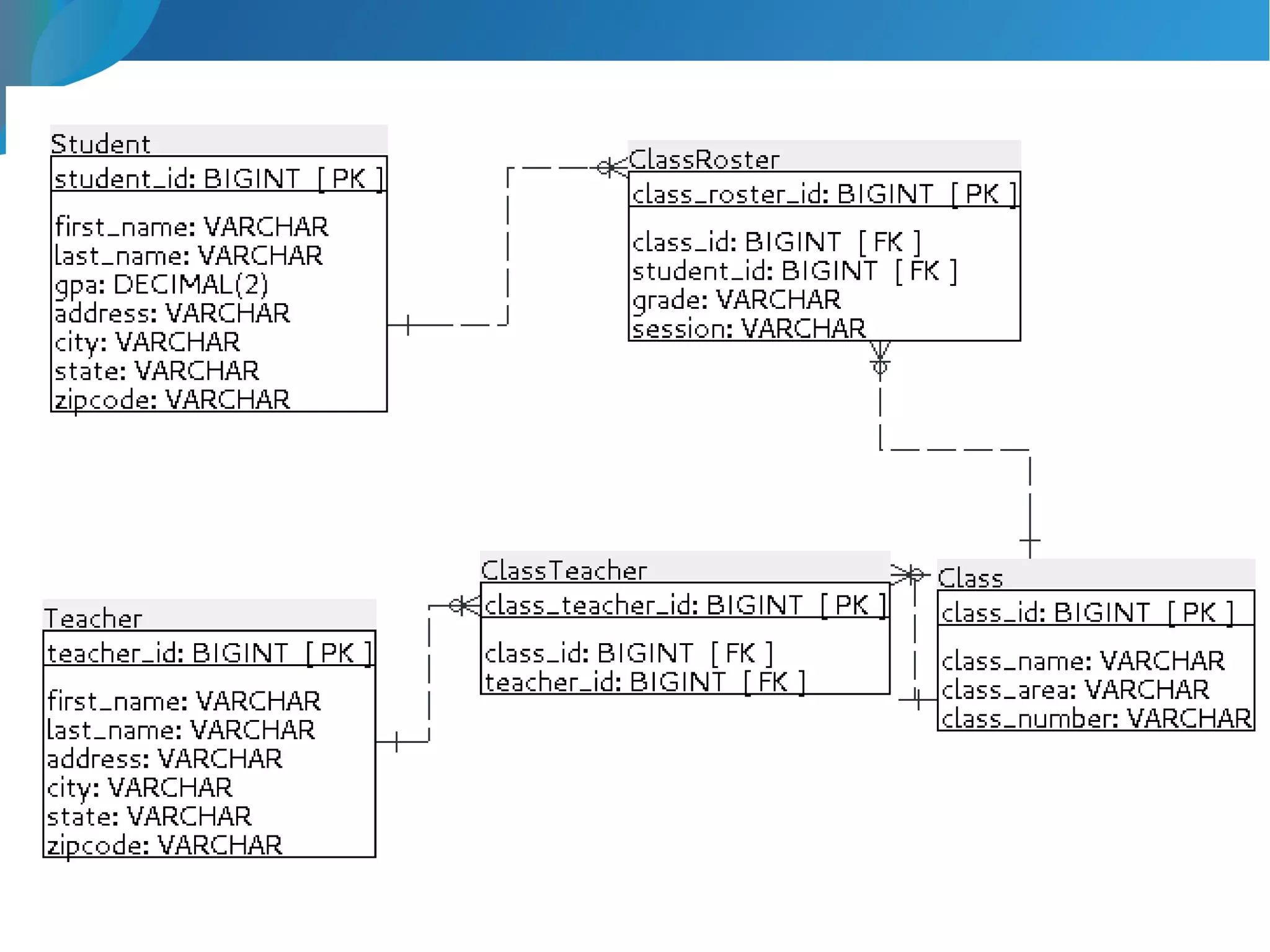

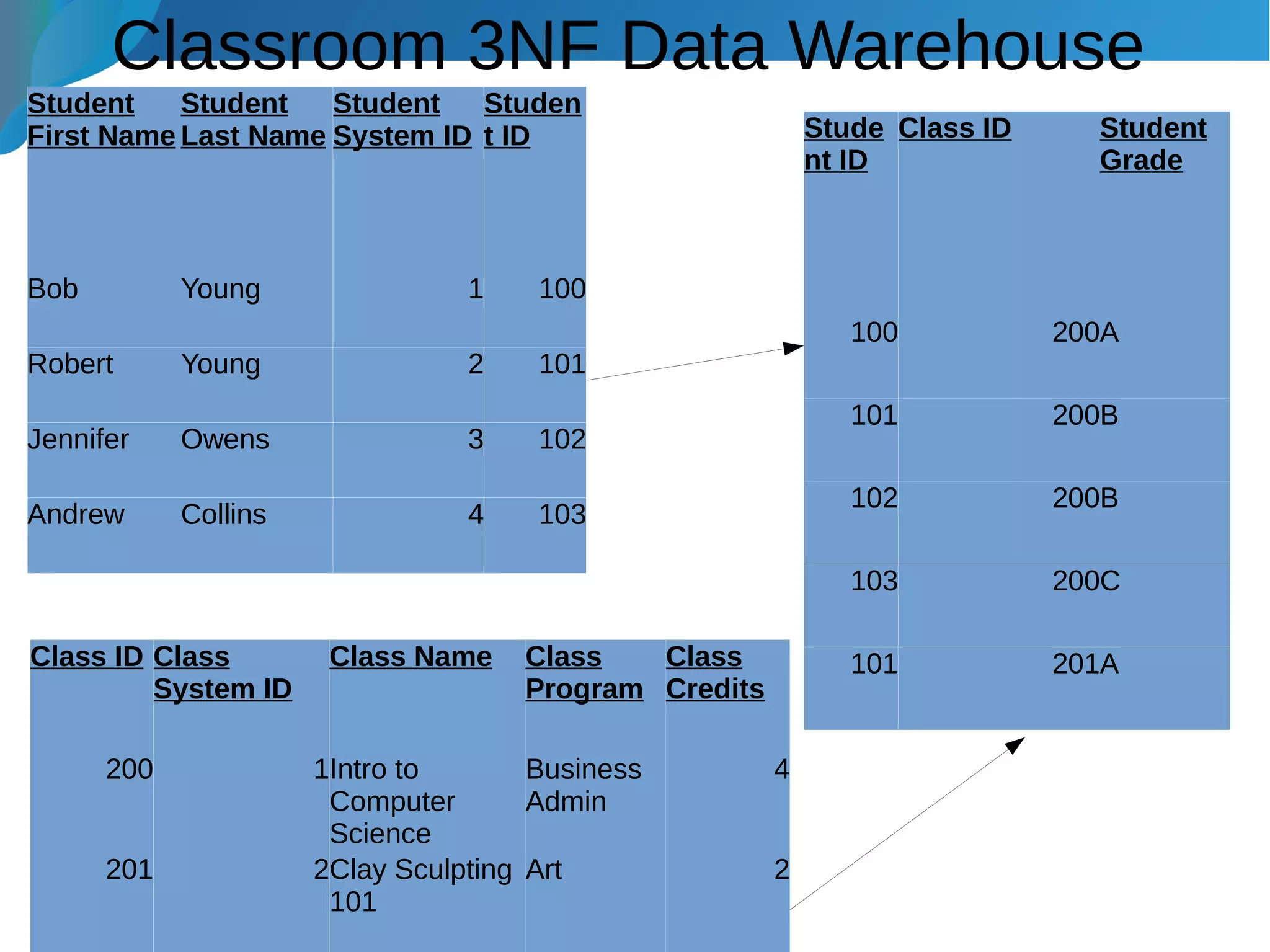
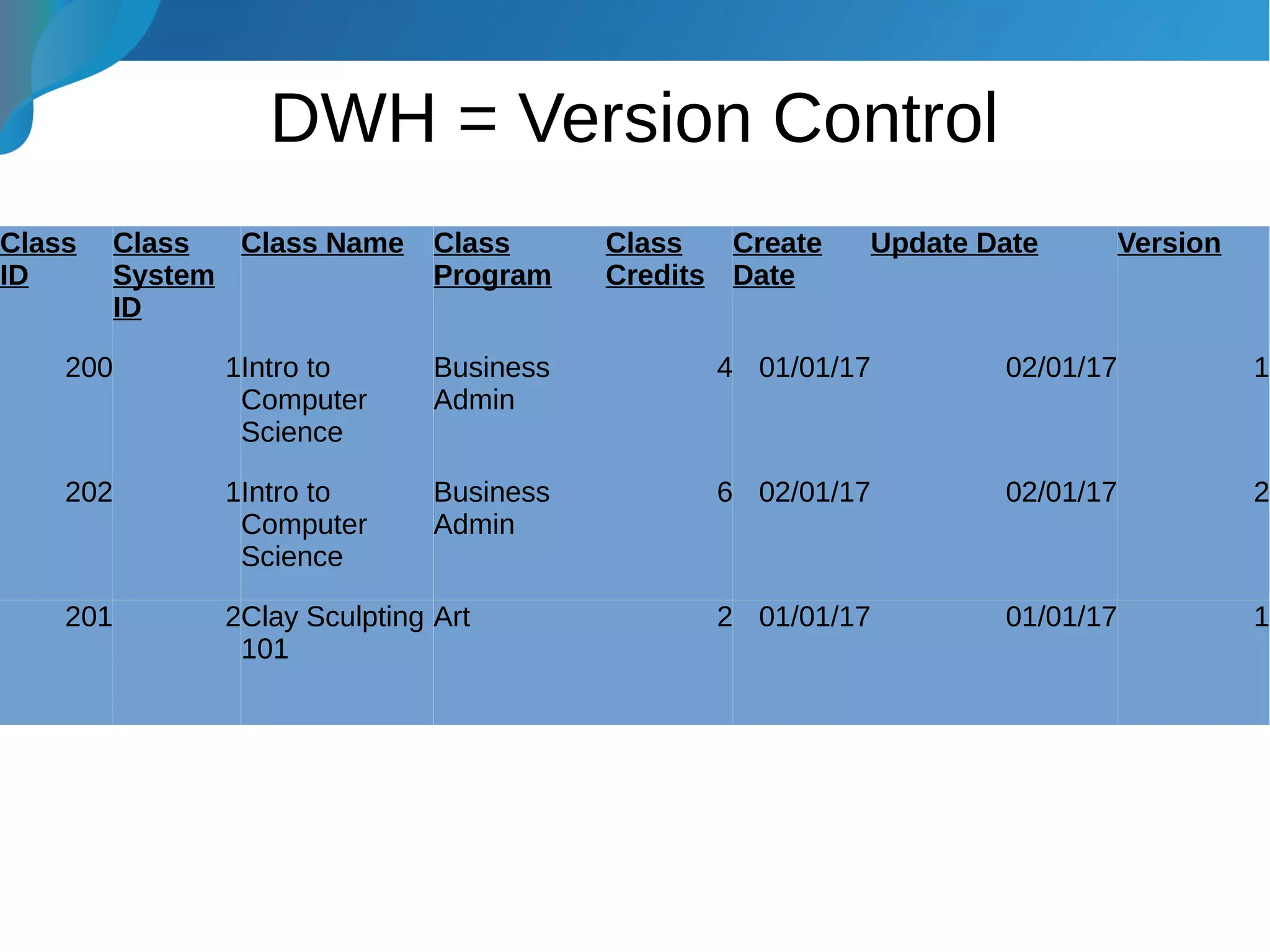
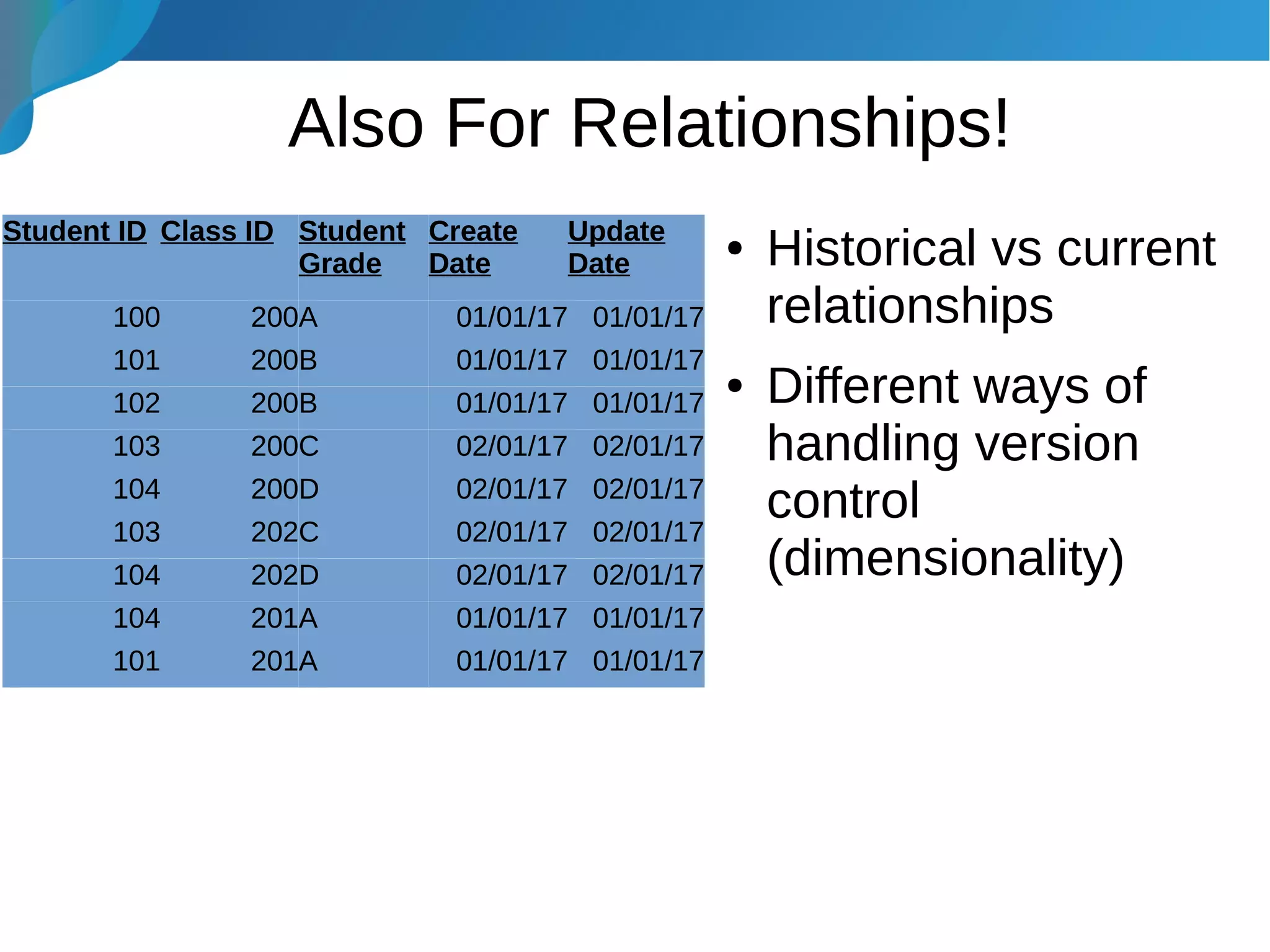
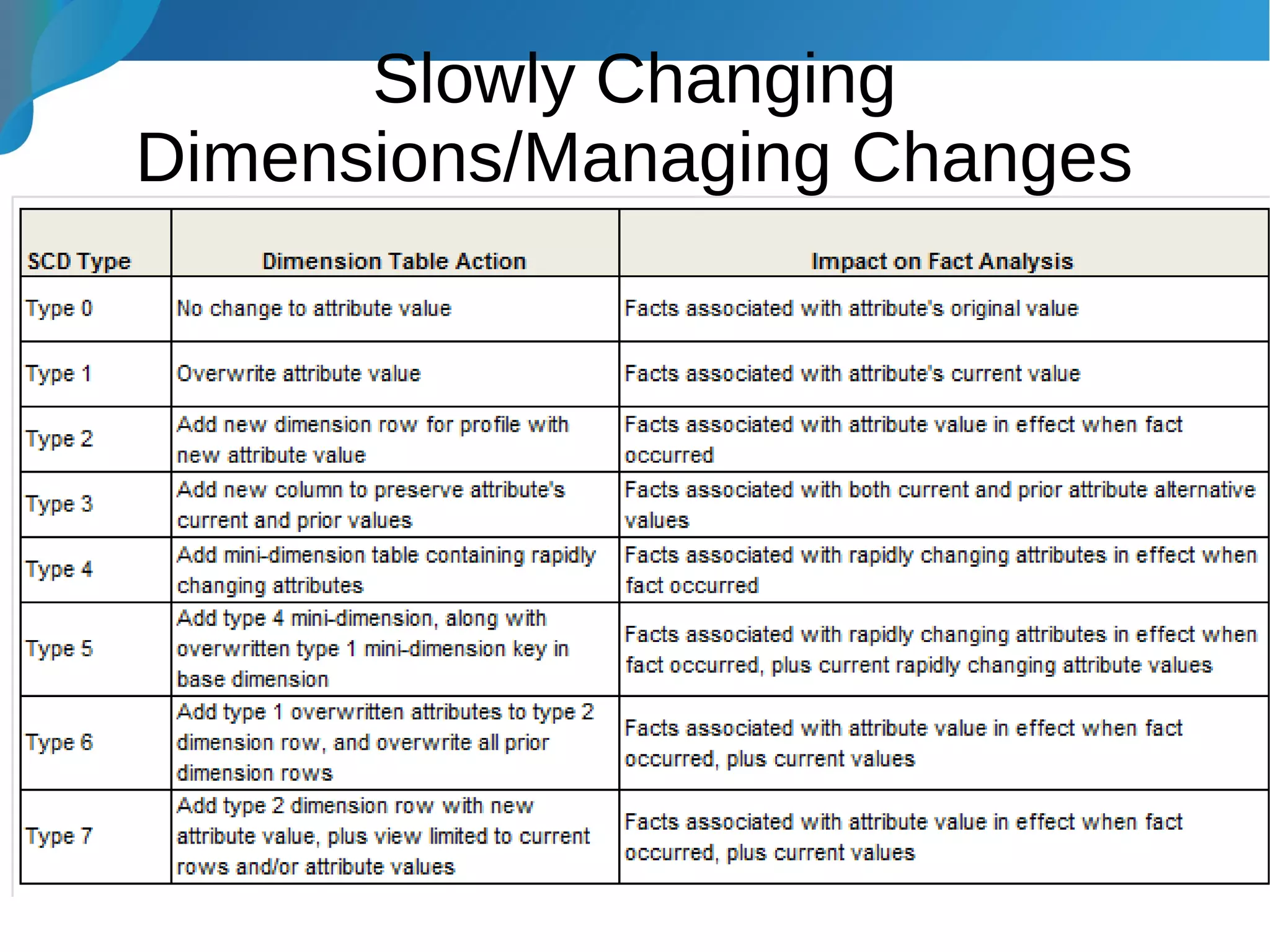
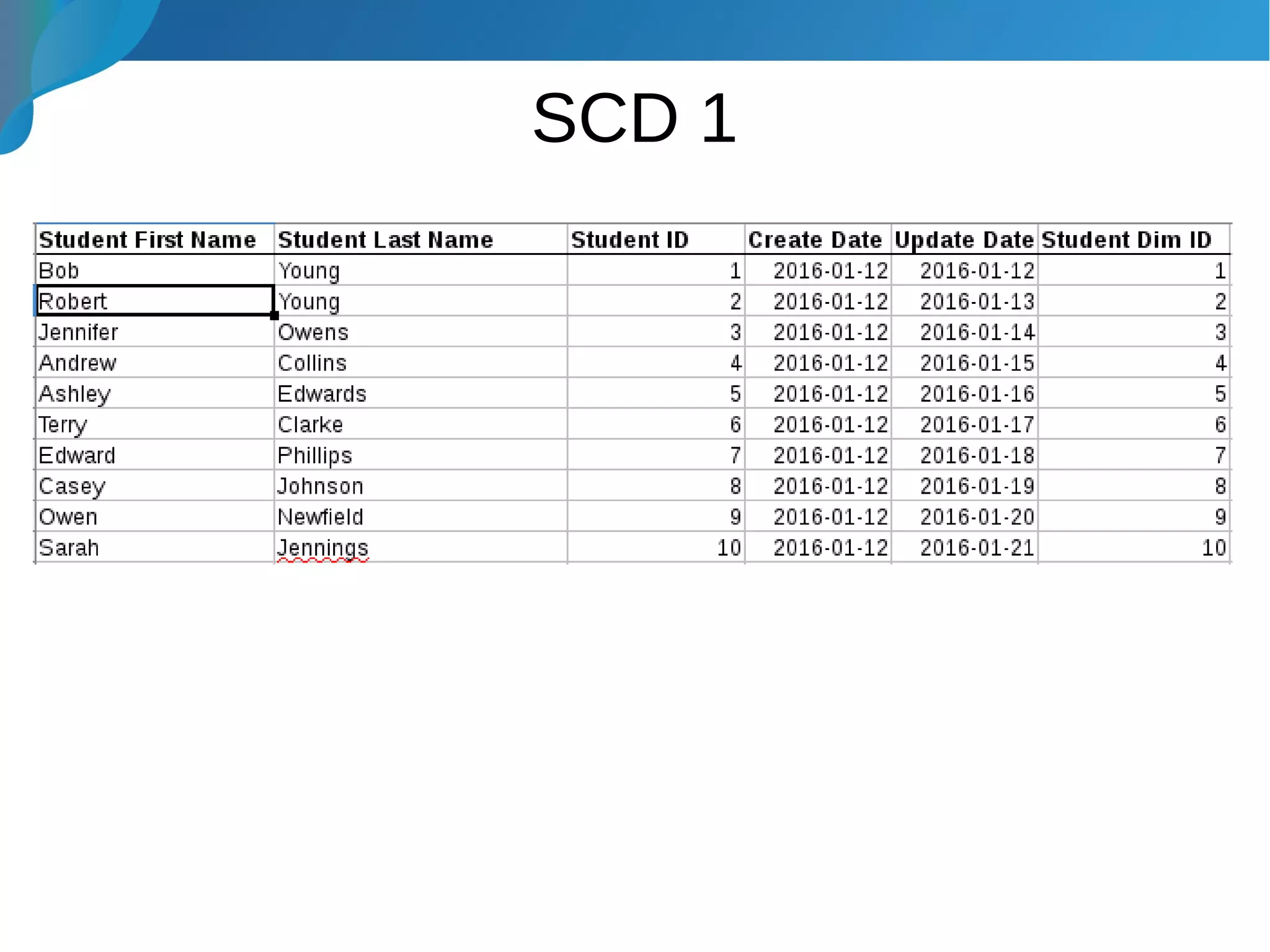
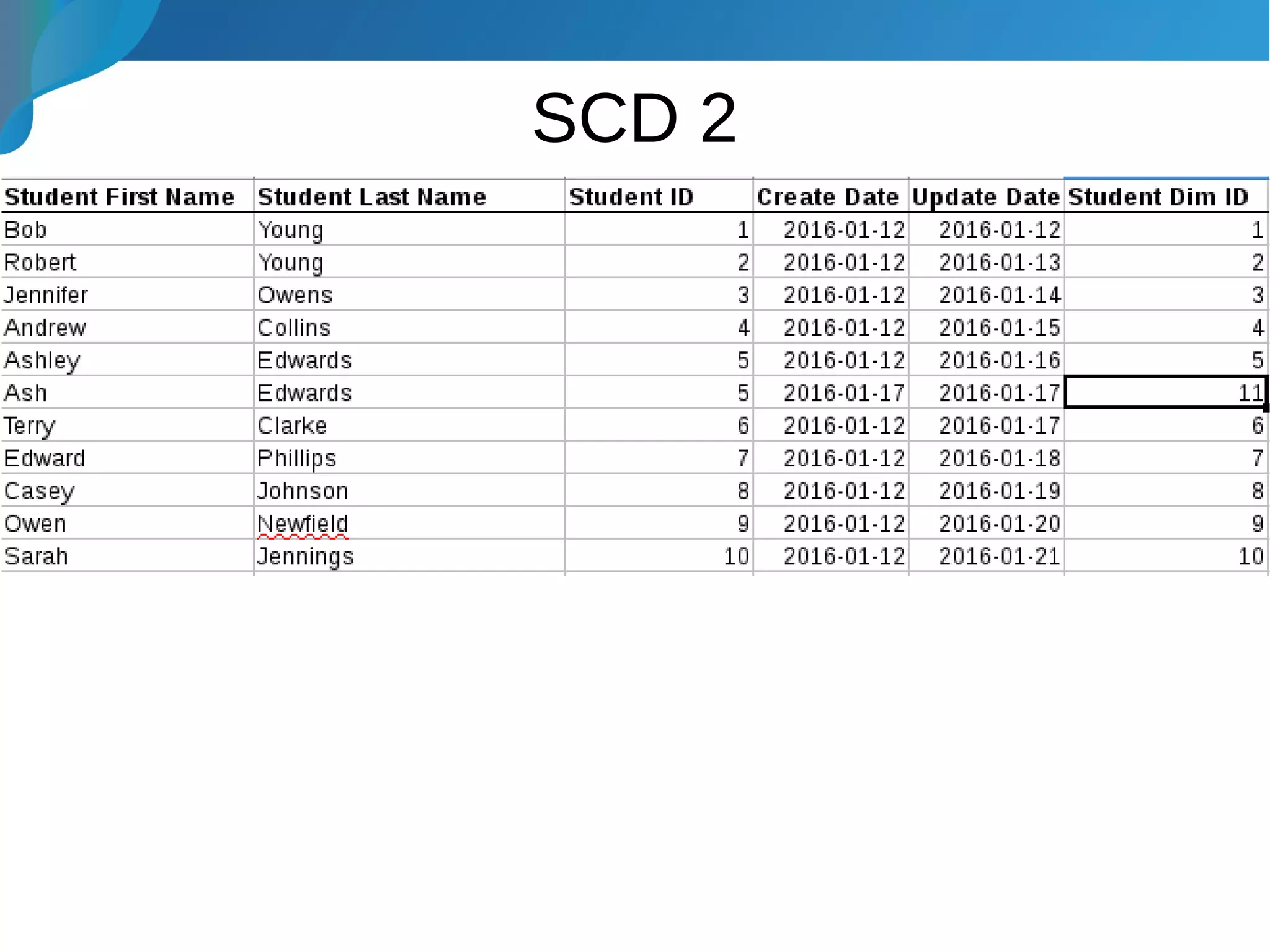
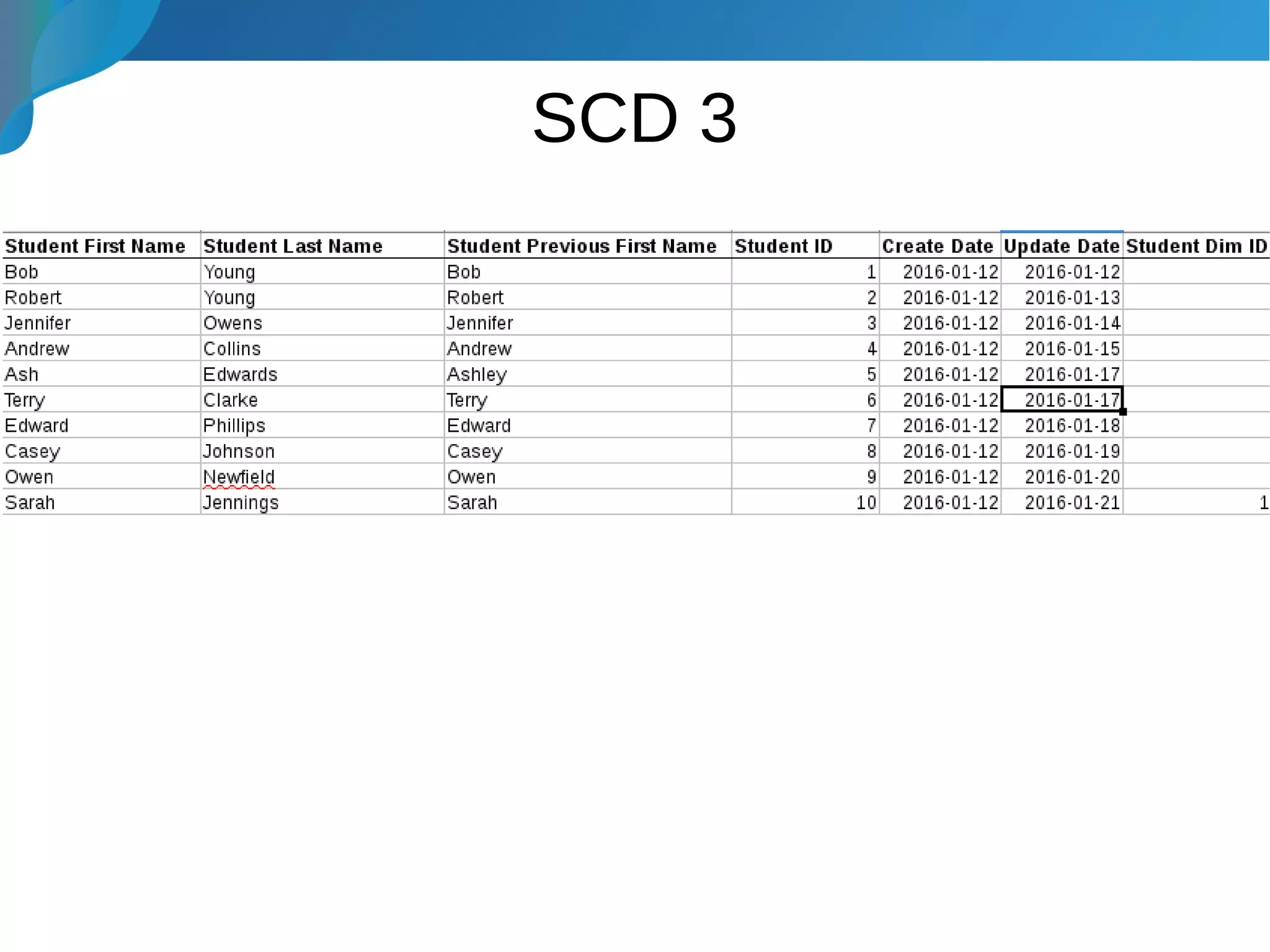


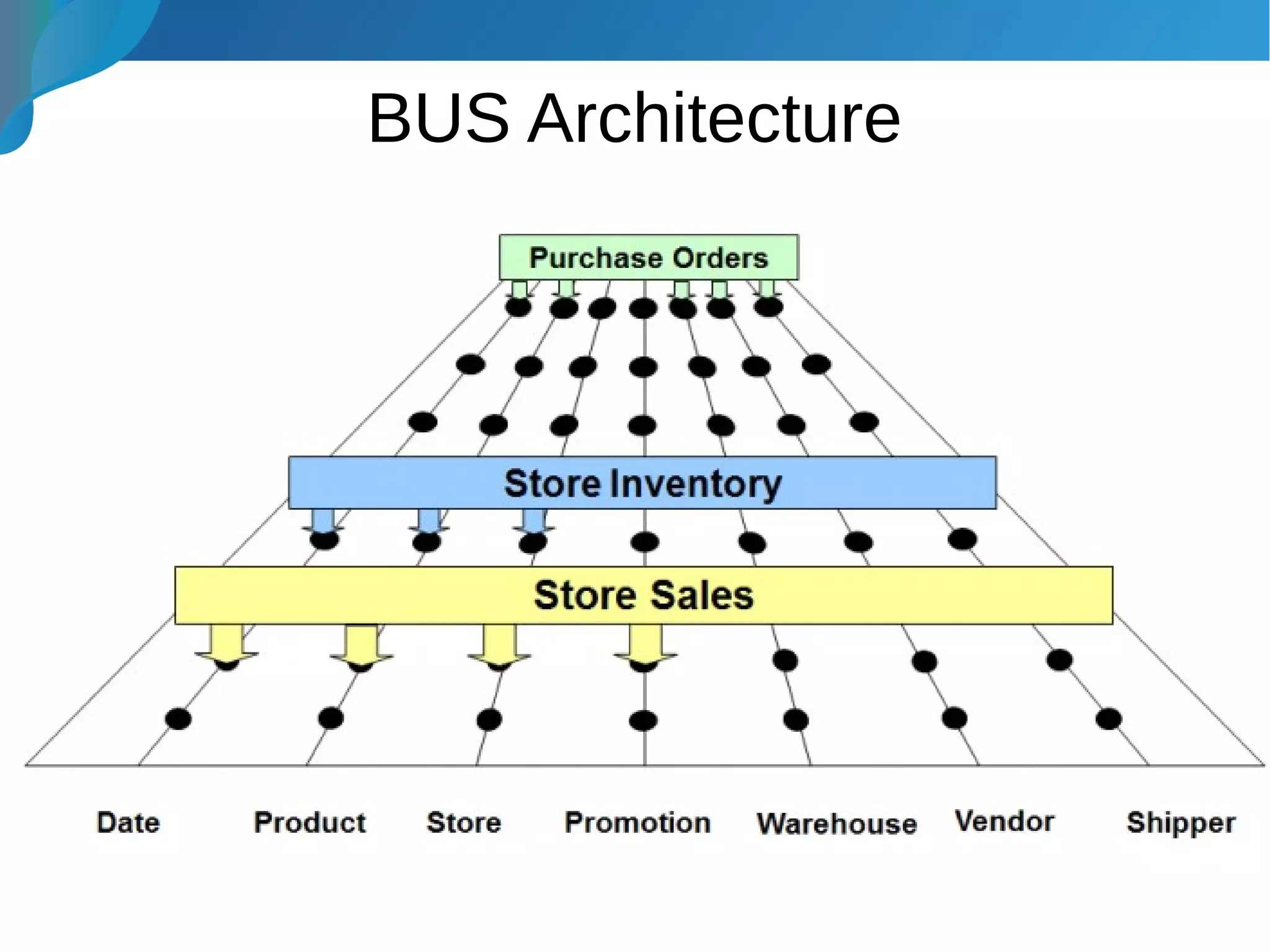
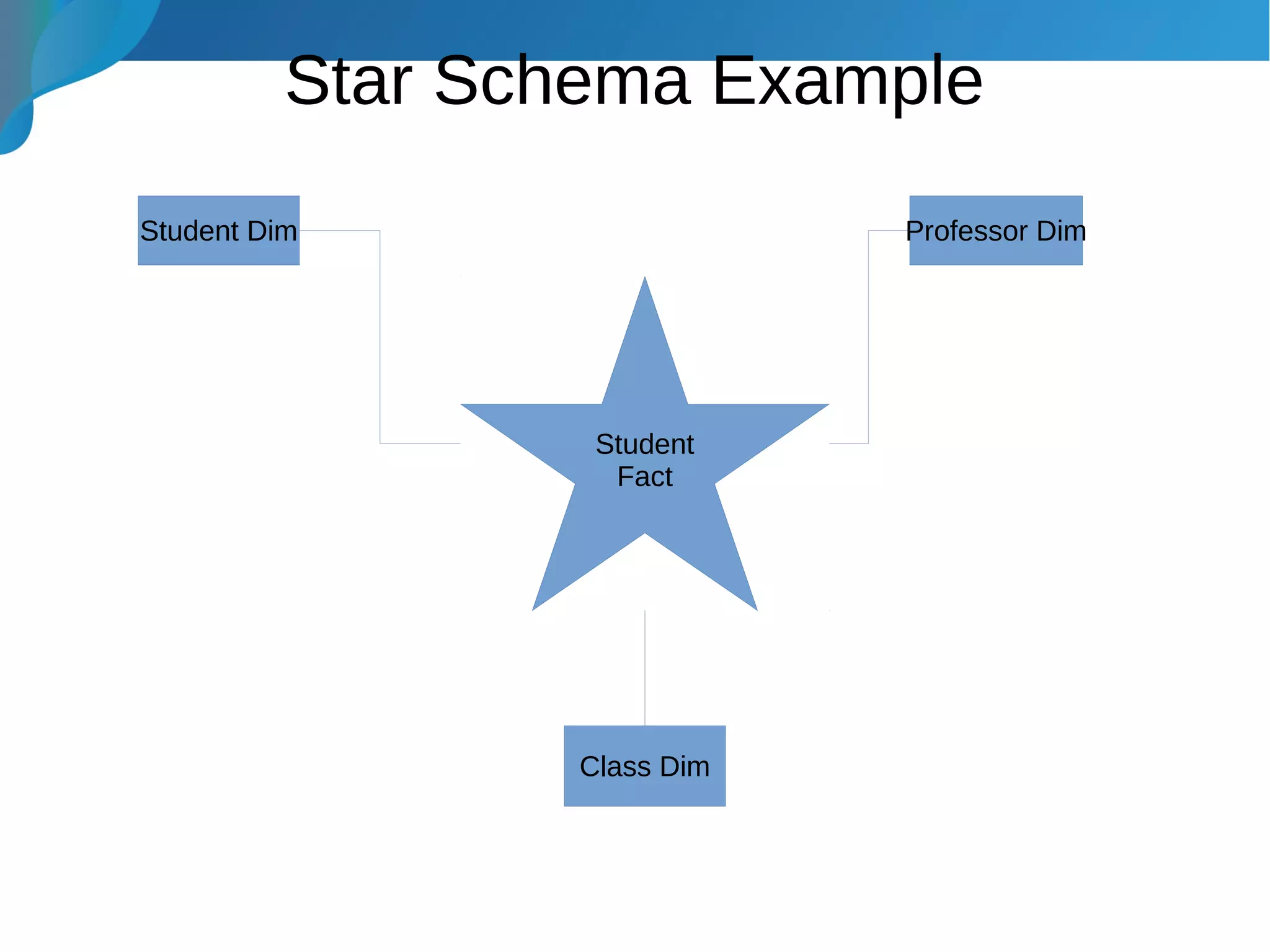
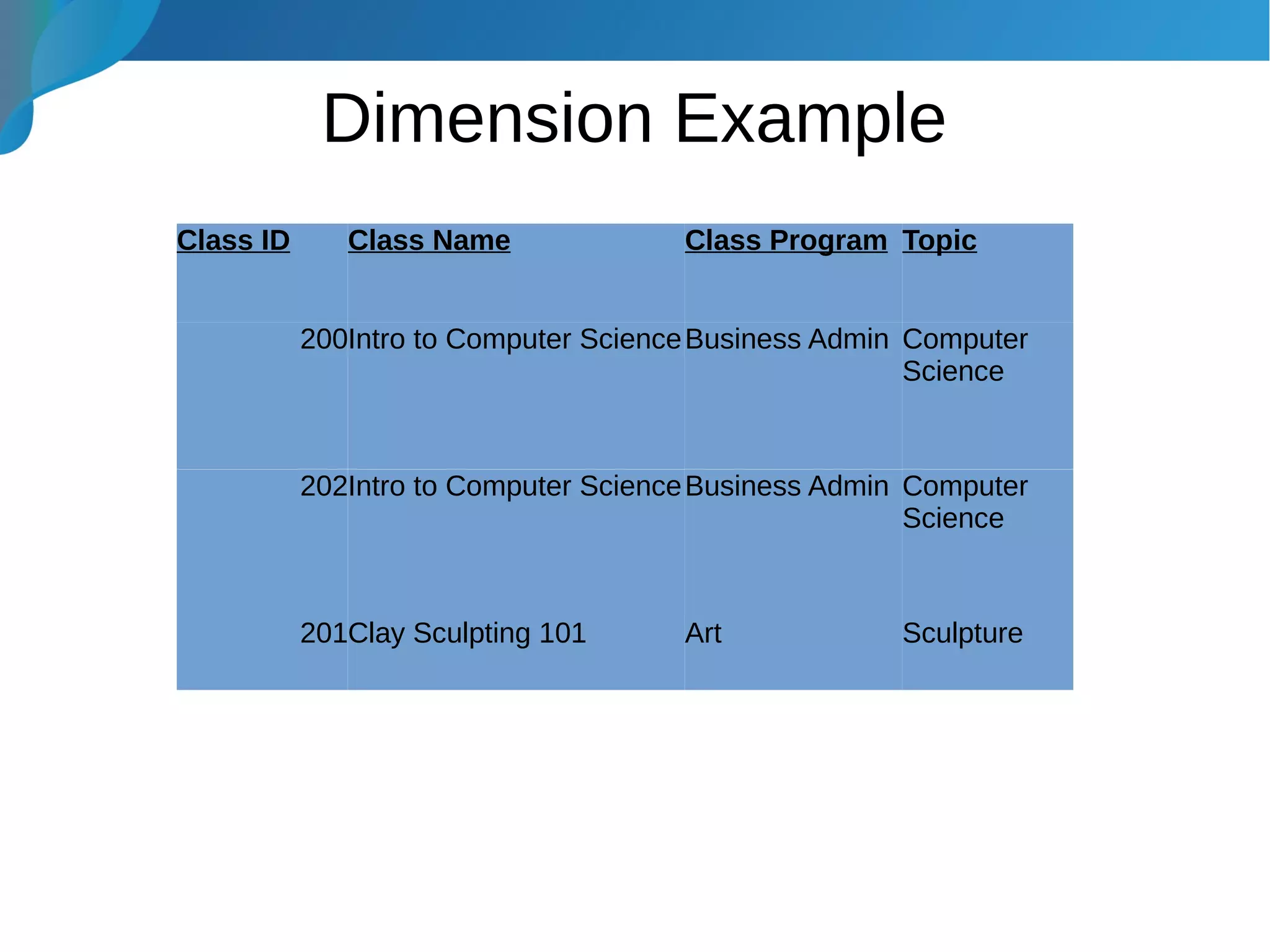
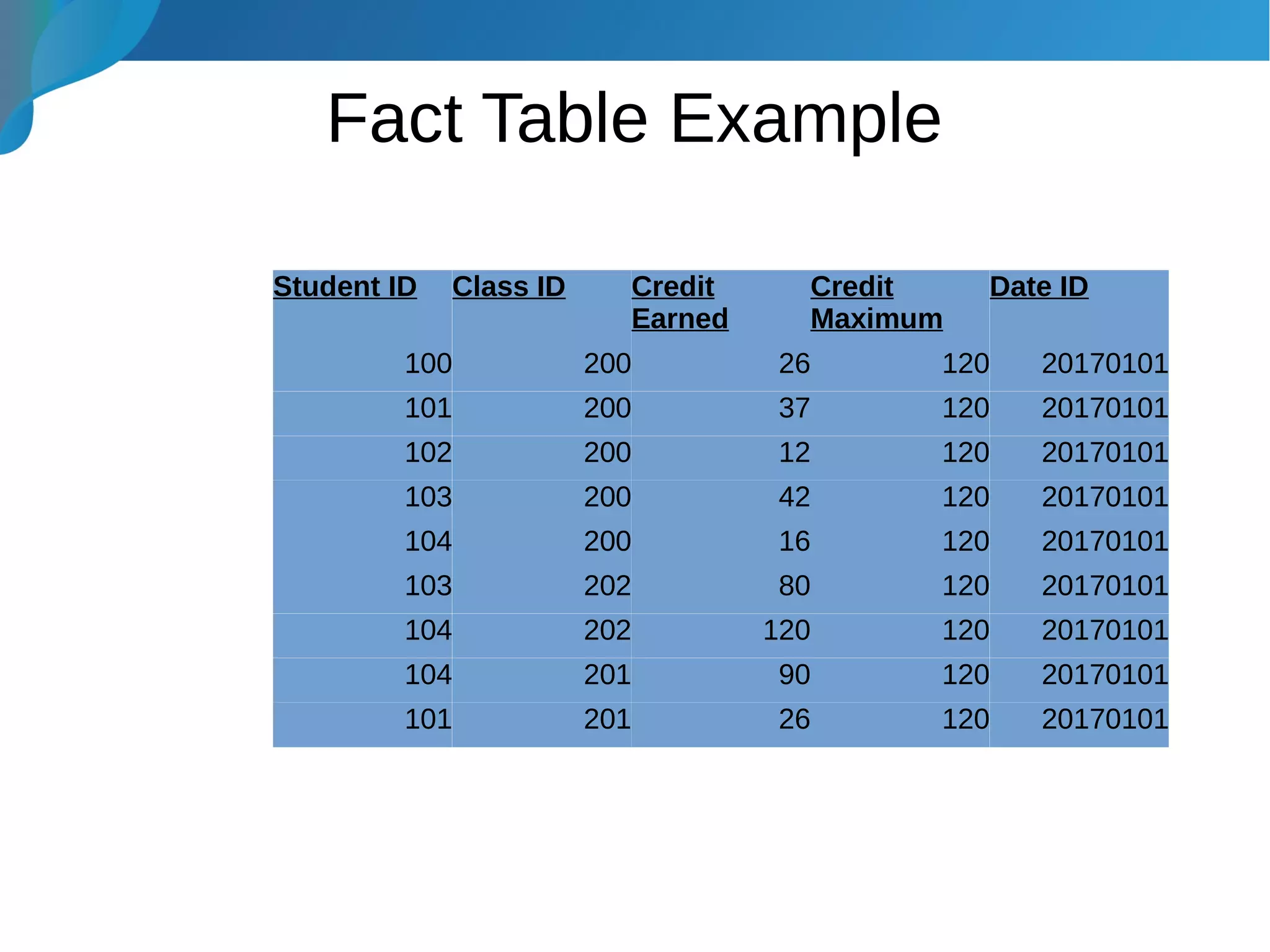

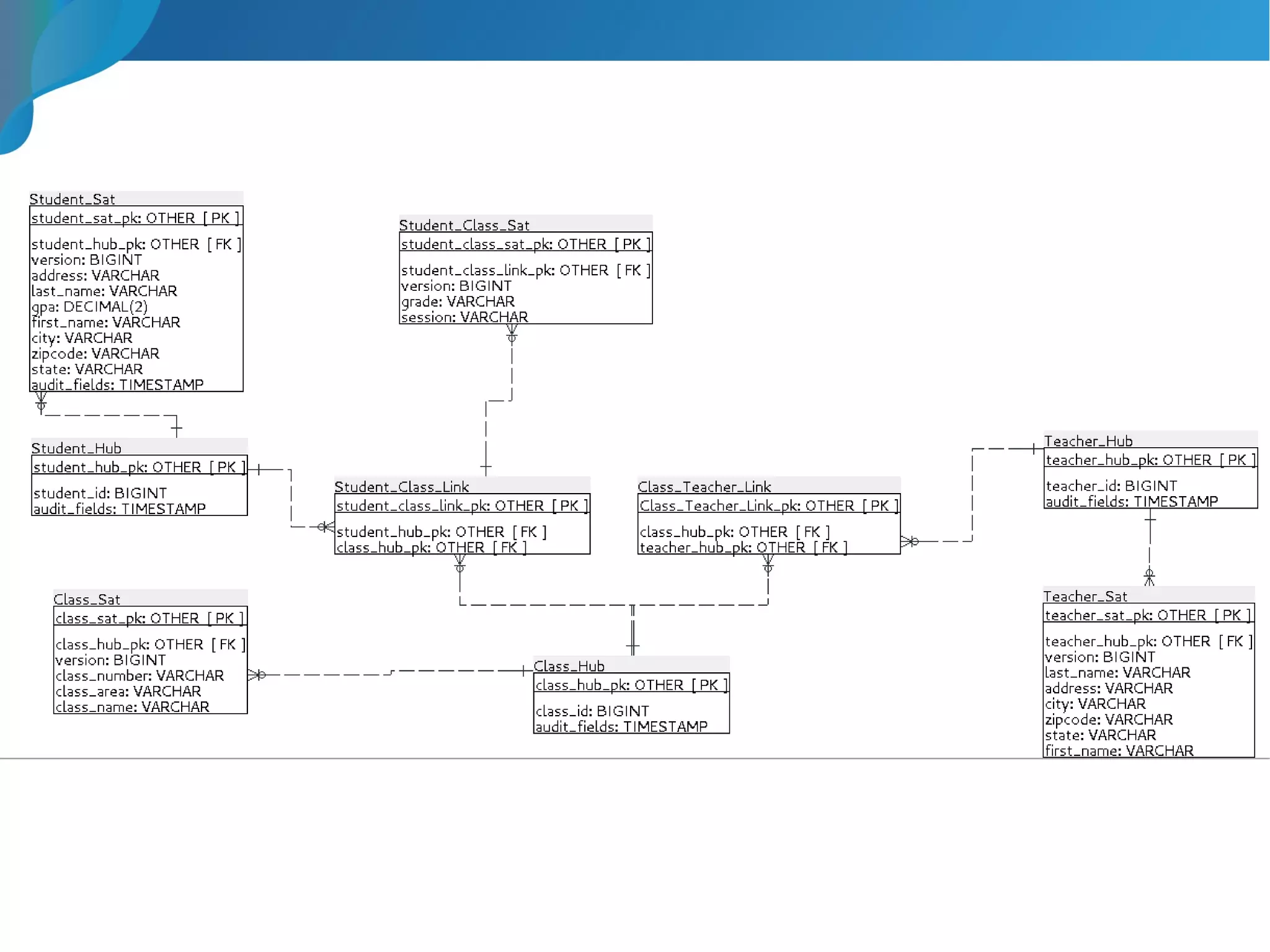






This document provides an introduction to data warehousing. It discusses why data warehouses are used, as they allow organizations to store historical data and perform complex analytics across multiple data sources. The document outlines common use cases and decisions in building a data warehouse, such as normalization, dimension modeling, and handling changes over time. It also notes some potential issues like performance bottlenecks and discusses strategies for addressing them, such as indexing and considering alternative data storage options.


















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















