Download as PDF, PPTX





![Random Forest
We will use the randomForest() function and a couple of
extractor functions to tease out some of the model fitting
diagnostics. We will use the sample() function to
randomly split the data into two parts: training and
testing.
> DSM_table2 <- read.csv("DSM_table2.csv")
> training <- sample(nrow(DSM_table2), 0.7 * nrow(DSM_table2))
> modelF <- randomForest(Value ~ dem + twi + slp + tmpd + tmpn, data =
DSM_table2[training, ],importance = TRUE, ntree = 1000)](https://image.slidesharecdn.com/d5-1-esp-random-forest-171020070148/85/13-Random-forest-5-320.jpg)
![Random Forest
The print function is to quickly assess the model fit.
print(modelF)
Call:
randomForest(formula = Value ~ dem + twi + slp + tmpd + tmpn,
data = DSM_table2[training, ], importance = TRUE, ntree = 1000)
Type of random forest: regression
Number of trees: 1000
No. of variables tried at each split: 1
Mean of squared residuals: 1.801046
% Var explained: 59.35](https://image.slidesharecdn.com/d5-1-esp-random-forest-171020070148/85/13-Random-forest-6-320.jpg)
![Random Forest
Generally, we confront this question by comparing
observed values with their predictions. Some of the more
common “quality” measures are the root mean square
error (RMSE), bias, and the R2 value
> Predicted <- predict(modelF, newdata = DSM_table2[-
training, ])
> RMSE <- sqrt(mean((DSM_table2$Value[-training] - Predicted)^2))
> RMSE
[1] 1.249491
> lm <- lm(Predicted~ DSM_table2$Value[-training])
> summary(lm)[["r.squared"]]
[1] 0.6079515
> bias <- mean(Predicted) - mean(DSM_table2$Value[-training])
> bias
[1] 0.01450241](https://image.slidesharecdn.com/d5-1-esp-random-forest-171020070148/85/13-Random-forest-7-320.jpg)
![Random Forest
plot(DSM_table2$Value[-training],Predicted)
abline(a=0,b=1,lty=2, col="red")
abline(lm, col="blue")](https://image.slidesharecdn.com/d5-1-esp-random-forest-171020070148/85/13-Random-forest-8-320.jpg)
![Random Forest
plot(DSM_table2$Value[-training],Predicted)
abline(a=0,b=1,lty=2, col="red")
abline(lm, col="blue")
regression on predicted and observed values - blue
1:1 comparison - red](https://image.slidesharecdn.com/d5-1-esp-random-forest-171020070148/85/13-Random-forest-9-320.jpg)

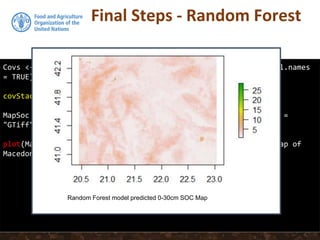

The document discusses the use of the Random Forest algorithm in digital soil mapping (DSM) and modeling, particularly its application in regression and classification tasks. It provides examples of how to implement the model in R using the randomForest package, including data splitting, model fitting, and diagnostics. The final output includes predicting soil organic carbon maps for Macedonia, demonstrating the model's practical application.





















































































