Download to read offline




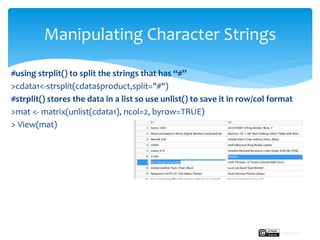
![>charData<-read.csv(“characterData.csv”,header = T) #load the dataset
>View(charData)
#extracting only the important column but remember to convert it with as.data.frame
>cdata<-as.data.frame(charData$Product_Name)
>names(cdata)[1]<- “product” #renaming the column name
#transform product variable to character data type as substr works with char data type
>cdata$product<-as.character(cdata$product)
#using substr
>cdata$substr<-as.data.frame(substr(cdata$product,start = 2,stop = 10))
#transform into Lowercase and Uppercase
>cdata$toUpper<-as.data.frame(toupper(cdata$product))
>cdata$tolower<-as.data.frame(tolower(cdata$product))
Manipulating Character Strings](https://image.slidesharecdn.com/13-220113090528/85/Transpose-and-manipulate-character-strings-5-320.jpg)
![grep() is use to extract/grab the data that matches with the pattern
For example:
>grep(" x",cdata$product)
where x is the pattern and cdata$product is the data object
>grepl(" x",cdata$product)
The only difference between grep() and grepl() is grep() function will give the
positions i.e. the index values of the data that matches with the pattern and
grepl() is a logical indicator (True/False) of the data that matches with the
pattern.
#grab only the rows that has “x” character in it.
For example: Tenex 46" x 60" Computer
>gdata<-cdata[grepl(" x",cdata$product),]
To know more about grep() and grepl() use ?grep
Pattern Matching and Replacement](https://image.slidesharecdn.com/13-220113090528/85/Transpose-and-manipulate-character-strings-7-320.jpg)



This document discusses techniques for manipulating data frames in R, including transposing data between wide and long formats using the reshape() function, extracting and transforming character strings using functions like substr() and grep(), and replacing patterns within strings using sub() and gsub(). Wide format stores variables in columns while long format stores them in rows. The melt() and dcast() functions are used to reshape between these formats.













































![[1062BPY12001] Data analysis with R / week 2](https://cdn.slidesharecdn.com/ss_thumbnails/dataanalyzer01-180307063046-thumbnail.jpg?width=640&height=640&fit=bounds)








































