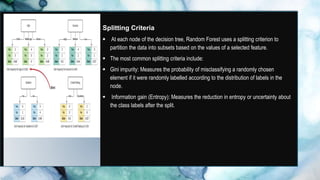
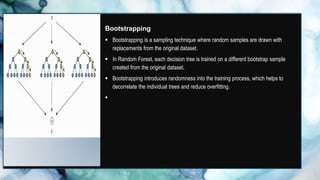
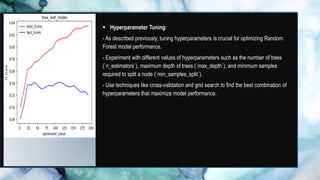
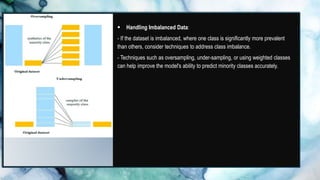
This document discusses machine learning, with a focus on the random forest and linear regression algorithms. It highlights the concepts of decision trees, the advantages and applications of random forests in various fields, and compares them with other machine learning techniques. Additionally, it addresses the implementation tools, performance improvement methods, limitations of these algorithms, and their significance in real-world scenarios.