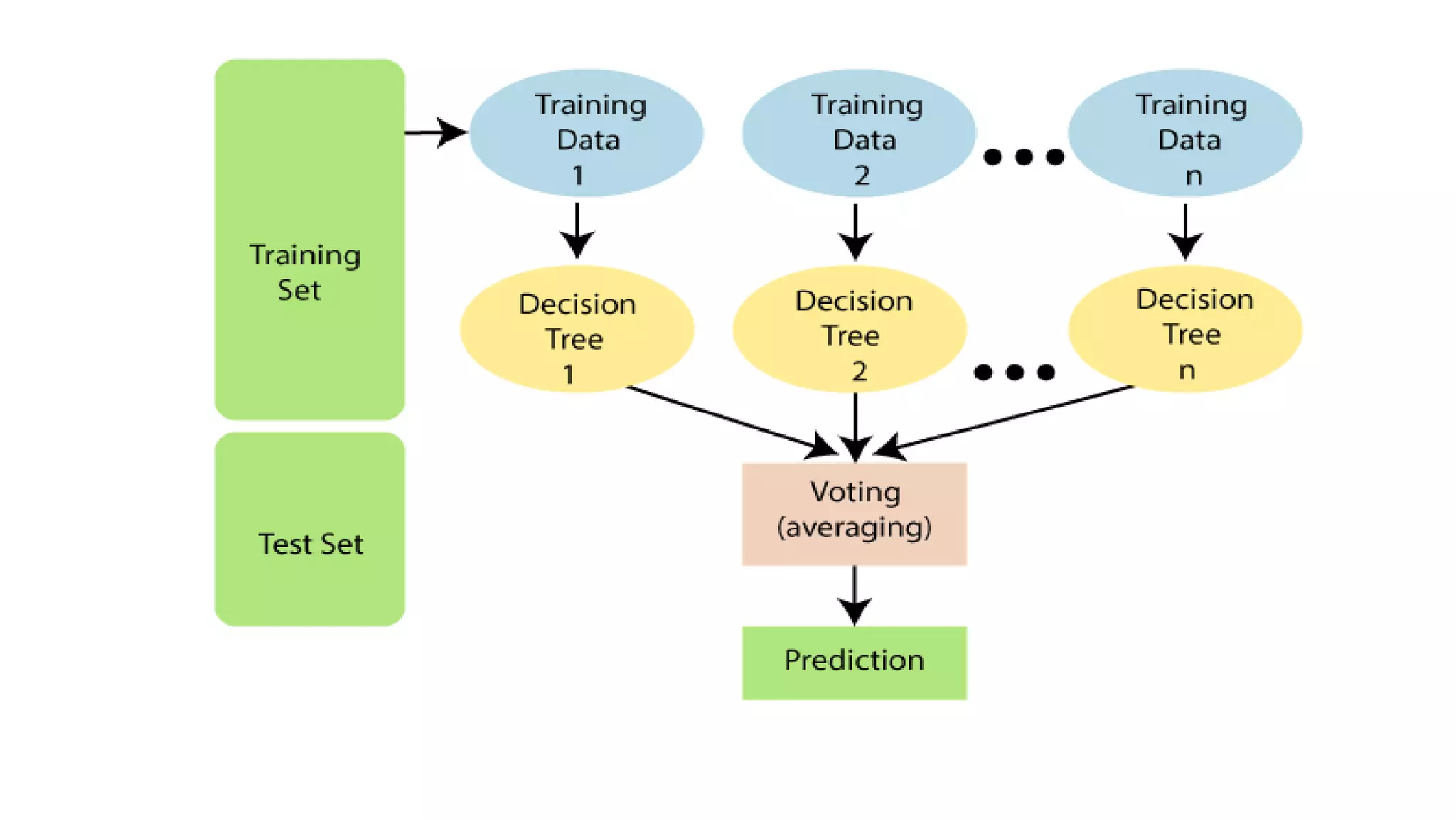
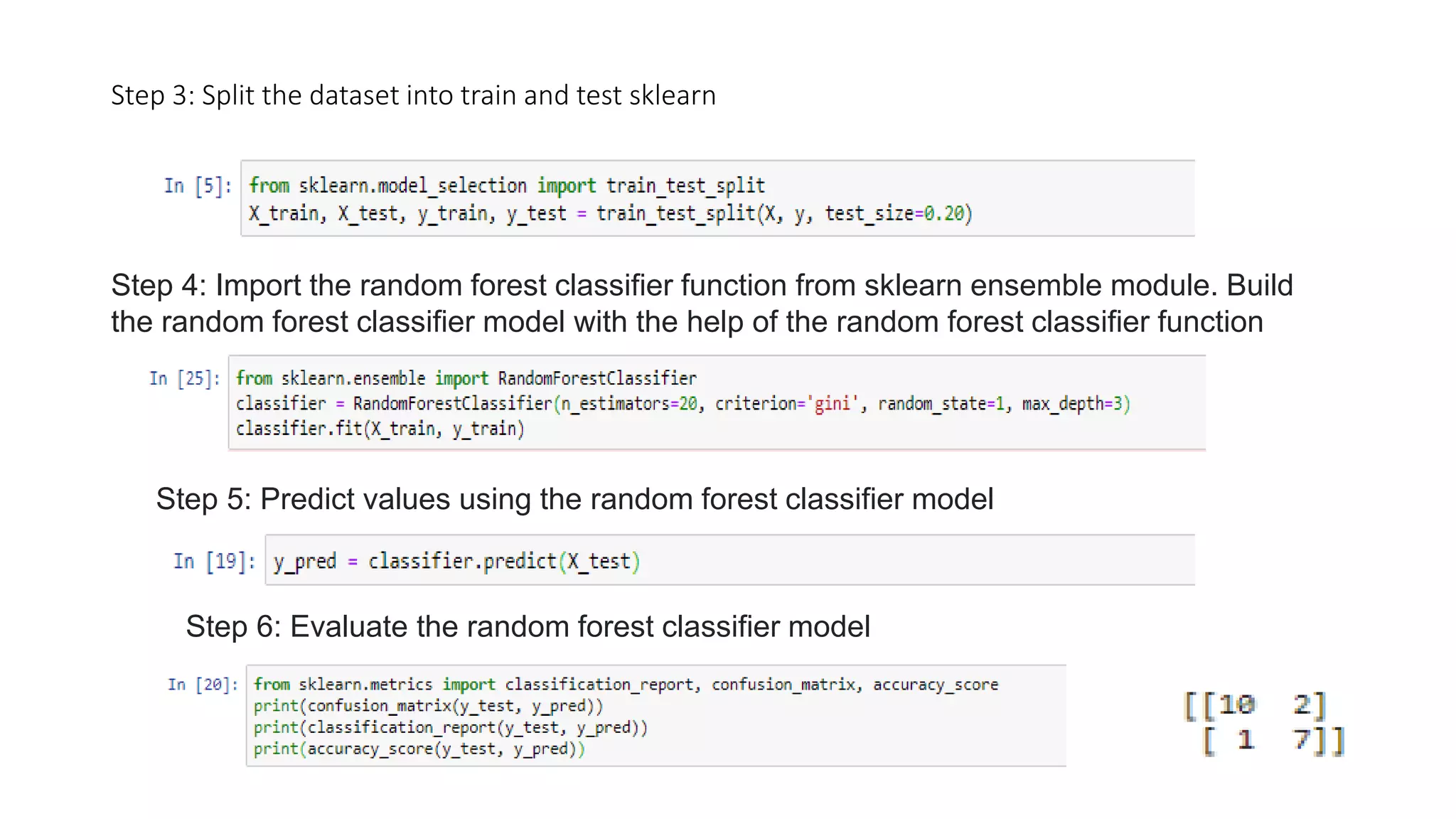
Random forest is an ensemble learning technique that builds multiple decision trees and merges their predictions to improve accuracy. It works by constructing many decision trees during training, then outputting the class that is the mode of the classes of the individual trees. Random forest can handle both classification and regression problems. It performs well even with large, complex datasets and prevents overfitting. Some key advantages are that it is accurate, efficient even with large datasets, and handles missing data well.

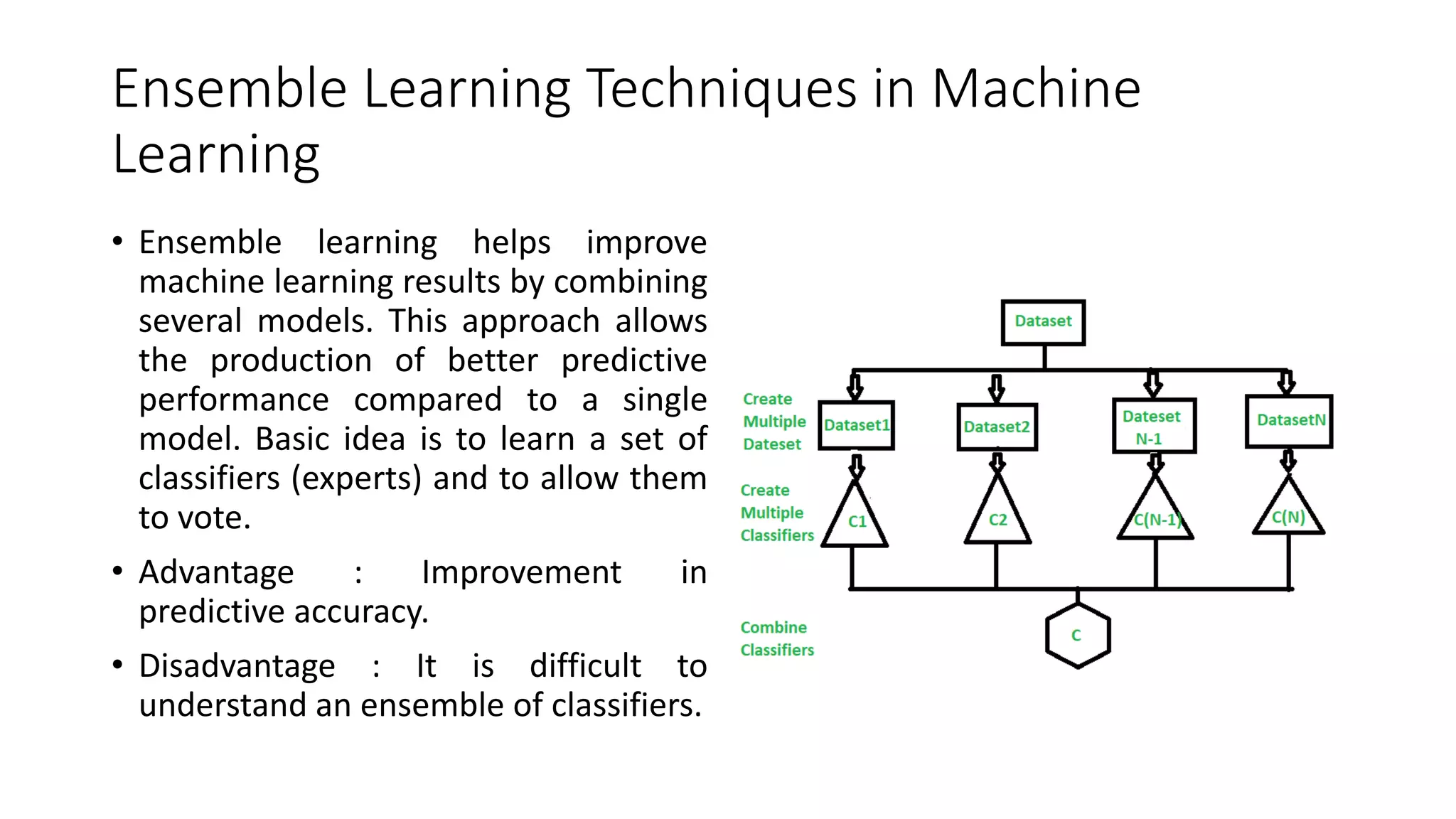









































































































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)