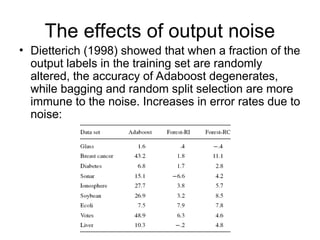
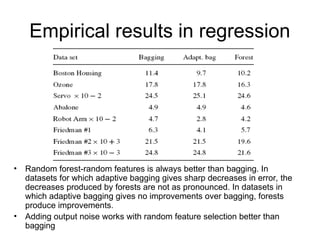
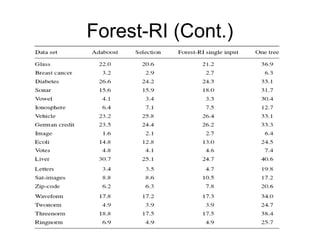
The document presents a presentation on random forests by Leo Breiman, highlighting their effectiveness as ensemble classifiers through the use of random feature selection. It discusses the advantages of random forests over other methods like adaboost, including robustness to noise, speed, and the ability to provide internal estimates of error and variable importance. Empirical results demonstrate that random forests are effective in classification tasks, often outperforming other methods in terms of accuracy and generalization error.














![Random forests using linear
combinations of inputs (Forest-RC)
• Defining more features by taking random linear
combinations of a number of the input variables.
That is, a feature is generated by specifying L, the
number of variables to be combined. At a given
node, L variables are randomly selected and added
together with coefficients that are uniform random
numbers on [-1,1]. F linear combinations are
generated, and then a search is made over these
for the best split. This procedure is called Forest-
RC.
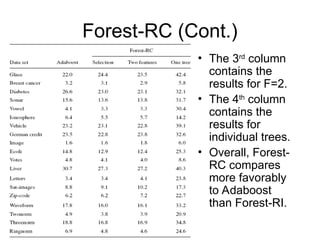
• We use L=3 and F=2,8 with the choice for F being
decided on by the out-of-bag estimate.](https://image.slidesharecdn.com/randomforests-241008073541-9974bb0f/85/RandomForests-Bootstrapping-BAgging-Aggregation-15-320.jpg)