Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Hiroshi Shimizu
PDF, PPTX
29,425 views
階層ベイズとWAIC
HijiyamaR#3で発表しました。 階層ベイズを使った場合に,最尤法のAICと結果が大きく異なります。その問題についてどのように考えたらいいかについて発表しました。
Data & Analytics
◦
Read more
52
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 80
2
/ 80
3
/ 80
4
/ 80
5
/ 80
6
/ 80
7
/ 80
8
/ 80
9
/ 80
10
/ 80
11
/ 80
12
/ 80
13
/ 80
14
/ 80
15
/ 80
16
/ 80
17
/ 80
18
/ 80
19
/ 80
20
/ 80
21
/ 80
22
/ 80
23
/ 80
24
/ 80
25
/ 80
26
/ 80
27
/ 80
28
/ 80
29
/ 80
30
/ 80
31
/ 80
32
/ 80
33
/ 80
34
/ 80
35
/ 80
36
/ 80
37
/ 80
38
/ 80
39
/ 80
40
/ 80
41
/ 80
42
/ 80
43
/ 80
44
/ 80
45
/ 80
46
/ 80
47
/ 80
48
/ 80
49
/ 80
50
/ 80
51
/ 80
52
/ 80
53
/ 80
54
/ 80
55
/ 80
56
/ 80
57
/ 80
58
/ 80
59
/ 80
60
/ 80
61
/ 80
62
/ 80
63
/ 80
Most read
64
/ 80
Most read
65
/ 80
Most read
66
/ 80
67
/ 80
68
/ 80
69
/ 80
70
/ 80
71
/ 80
72
/ 80
73
/ 80
74
/ 80
75
/ 80
76
/ 80
77
/ 80
78
/ 80
79
/ 80
80
/ 80
More Related Content
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
PPTX
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
階層モデルの分散パラメータの事前分布について
by
hoxo_m
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
Stanコードの書き方 中級編
by
Hiroshi Shimizu
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
What's hot
PDF
Stanの便利な事後処理関数
by
daiki hojo
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PDF
社会心理学とGlmm
by
Hiroshi Shimizu
PDF
pymcとpystanでベイズ推定してみた話
by
Classi.corp
PDF
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
PDF
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
PDF
2 4.devianceと尤度比検定
by
logics-of-blue
PPTX
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
PDF
階層ベイズによるワンToワンマーケティング入門
by
shima o
PPTX
WAICとWBICのご紹介
by
Tomoki Matsumoto
PPTX
ベイズファクターとモデル選択
by
kazutantan
PDF
比例ハザードモデルはとってもtricky!
by
takehikoihayashi
PDF
PRML輪読#1
by
matsuolab
PDF
混合モデルを使って反復測定分散分析をする
by
Masaru Tokuoka
PDF
質的変数の相関・因子分析
by
Mitsuo Shimohata
PDF
StanとRでベイズ統計モデリング読書会 Chapter 7(7.6-7.9) 回帰分析の悩みどころ ~統計の力で歌うまになりたい~
by
nocchi_airport
PDF
2 6.ゼロ切断・過剰モデル
by
logics-of-blue
PDF
ベイズモデリングと仲良くするために
by
Shushi Namba
PDF
20180118 一般化線形モデル(glm)
by
Masakazu Shinoda
PDF
Chapter9 一歩進んだ文法(前半)
by
itoyan110
Stanの便利な事後処理関数
by
daiki hojo
Stan超初心者入門
by
Hiroshi Shimizu
社会心理学とGlmm
by
Hiroshi Shimizu
pymcとpystanでベイズ推定してみた話
by
Classi.corp
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
2 4.devianceと尤度比検定
by
logics-of-blue
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
階層ベイズによるワンToワンマーケティング入門
by
shima o
WAICとWBICのご紹介
by
Tomoki Matsumoto
ベイズファクターとモデル選択
by
kazutantan
比例ハザードモデルはとってもtricky!
by
takehikoihayashi
PRML輪読#1
by
matsuolab
混合モデルを使って反復測定分散分析をする
by
Masaru Tokuoka
質的変数の相関・因子分析
by
Mitsuo Shimohata
StanとRでベイズ統計モデリング読書会 Chapter 7(7.6-7.9) 回帰分析の悩みどころ ~統計の力で歌うまになりたい~
by
nocchi_airport
2 6.ゼロ切断・過剰モデル
by
logics-of-blue
ベイズモデリングと仲良くするために
by
Shushi Namba
20180118 一般化線形モデル(glm)
by
Masakazu Shinoda
Chapter9 一歩進んだ文法(前半)
by
itoyan110
Viewers also liked
PDF
シンギュラリティを知らずに機械学習を語るな
by
hoxo_m
PDF
100人のための統計解析 和食レストラン編
by
. .
PPT
変数選択におけるAICの利用:理論と実装
by
sstat3
PDF
幾何を使った統計のはなし
by
Toru Imai
PDF
『予測にいかす統計モデリングの基本』の売上データの分析をトレースしてみた
by
. .
PDF
1 8.交互作用
by
logics-of-blue
PDF
1 6.変数選択とAIC
by
logics-of-blue
PDF
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
シンギュラリティを知らずに機械学習を語るな
by
hoxo_m
100人のための統計解析 和食レストラン編
by
. .
変数選択におけるAICの利用:理論と実装
by
sstat3
幾何を使った統計のはなし
by
Toru Imai
『予測にいかす統計モデリングの基本』の売上データの分析をトレースしてみた
by
. .
1 8.交互作用
by
logics-of-blue
1 6.変数選択とAIC
by
logics-of-blue
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
Similar to 階層ベイズとWAIC
PDF
ベイズ推定でパラメータリスクを捉える&優れたサンプラーとしてのMCMC
by
基晴 出井
PDF
MCMCサンプルの使い方 ~見る・決める・探す・発生させる~
by
. .
PPTX
ベイズ統計学の概論的紹介-old
by
Naoki Hayashi
PDF
確率統計-機械学習その前に v2.0
by
Hidekatsu Izuno
PDF
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PDF
認知心理学への実践:データ生成メカニズムのベイズモデリング【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
PPT
大森ゼミ新歓
by
T Nakagawa
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PPTX
MCMC法
by
MatsuiRyo
PDF
【輪読】Taking the Human Out of the Loop, section 8
by
Takeru Abe
PDF
ベイズ推論とシミュレーション法の基礎
by
Tomoshige Nakamura
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
RStanとShinyStanによるベイズ統計モデリング入門
by
Masaki Tsuda
PDF
0726
by
RIKEN Center for Integrative Medical Science Center (IMS-RCAI)
PDF
マーク付き点過程
by
Yoshiaki Sakakura
PPTX
変数同士の関連_MIC
by
Shushi Namba
PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
PDF
確率モデルを使ったグラフクラスタリング
by
正志 坪坂
PPTX
論文紹介 Markov chain monte carlo and variational inferences bridging the gap
by
Shuuji Mihara
PDF
glmmstanパッケージを作ってみた
by
Hiroshi Shimizu
ベイズ推定でパラメータリスクを捉える&優れたサンプラーとしてのMCMC
by
基晴 出井
MCMCサンプルの使い方 ~見る・決める・探す・発生させる~
by
. .
ベイズ統計学の概論的紹介-old
by
Naoki Hayashi
確率統計-機械学習その前に v2.0
by
Hidekatsu Izuno
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
認知心理学への実践:データ生成メカニズムのベイズモデリング【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
大森ゼミ新歓
by
T Nakagawa
機械学習のためのベイズ最適化入門
by
hoxo_m
MCMC法
by
MatsuiRyo
【輪読】Taking the Human Out of the Loop, section 8
by
Takeru Abe
ベイズ推論とシミュレーション法の基礎
by
Tomoshige Nakamura
ベイズ統計学の概論的紹介
by
Naoki Hayashi
RStanとShinyStanによるベイズ統計モデリング入門
by
Masaki Tsuda
0726
by
RIKEN Center for Integrative Medical Science Center (IMS-RCAI)
マーク付き点過程
by
Yoshiaki Sakakura
変数同士の関連_MIC
by
Shushi Namba
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
確率モデルを使ったグラフクラスタリング
by
正志 坪坂
論文紹介 Markov chain monte carlo and variational inferences bridging the gap
by
Shuuji Mihara
glmmstanパッケージを作ってみた
by
Hiroshi Shimizu
More from Hiroshi Shimizu
PDF
Stanでガウス過程
by
Hiroshi Shimizu
PDF
SapporoR#6 初心者セッションスライド
by
Hiroshi Shimizu
PDF
Tokyo r53
by
Hiroshi Shimizu
PDF
媒介分析について
by
Hiroshi Shimizu
PDF
負の二項分布について
by
Hiroshi Shimizu
PPTX
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
PDF
Rで潜在ランク分析
by
Hiroshi Shimizu
PDF
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
PPTX
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
PPTX
Latent rank theory
by
Hiroshi Shimizu
PDF
エクセルでテキストマイニング TTM2HADの使い方
by
Hiroshi Shimizu
PPTX
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
PPTX
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
PPTX
Excelでも統計分析 HADについて SappoRo.R#3
by
Hiroshi Shimizu
PDF
エクセルで統計分析2 HADの使い方
by
Hiroshi Shimizu
PDF
エクセルで統計分析4 因子分析のやり方
by
Hiroshi Shimizu
PDF
エクセルで統計分析3 回帰分析のやり方
by
Hiroshi Shimizu
PDF
Mplusの使い方 中級編
by
Hiroshi Shimizu
PDF
Mplusの使い方 初級編
by
Hiroshi Shimizu
Stanでガウス過程
by
Hiroshi Shimizu
SapporoR#6 初心者セッションスライド
by
Hiroshi Shimizu
Tokyo r53
by
Hiroshi Shimizu
媒介分析について
by
Hiroshi Shimizu
負の二項分布について
by
Hiroshi Shimizu
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
Rで潜在ランク分析
by
Hiroshi Shimizu
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
Latent rank theory
by
Hiroshi Shimizu
エクセルでテキストマイニング TTM2HADの使い方
by
Hiroshi Shimizu
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
Excelでも統計分析 HADについて SappoRo.R#3
by
Hiroshi Shimizu
エクセルで統計分析2 HADの使い方
by
Hiroshi Shimizu
エクセルで統計分析4 因子分析のやり方
by
Hiroshi Shimizu
エクセルで統計分析3 回帰分析のやり方
by
Hiroshi Shimizu
Mplusの使い方 中級編
by
Hiroshi Shimizu
Mplusの使い方 初級編
by
Hiroshi Shimizu
階層ベイズとWAIC
1.
階層ベイズのWAICについて @simizu706
2.
自己紹介 • 清水裕士 – 所属:関西学院大学(かんせいがくいんと読む) –
専門:心理学界隈 – Web: norimune.net – Twitter: @simizu706 Kazutan.R
3.
注意 • 発表内容は少しマニアックです – ぶっちゃけ,Rの話ではなく統計学の話です –
ただし,間違えているかもしれません。 – もし間違いがあればご指摘ください。 • 30分で80枚のスライドを疾走します – ちょいちょい飛びます – あとでアップするのでそちらを見てください。 • あまりオーディエンスを意識していないです • 今日は早口ショーだと思って見ておいてください
4.
今日の話 • AICってなんだっけ • 階層ベイズってなんだっけ •
階層ベイズのWAIC,そして問題点 • 情報量規準をもう一回考える
5.
AICってなんだっけ?
6.
AIC • 赤池情報量規準 – モデル比較に使われる指標 –
AICが相対的に小さいモデルは「良い」モデル • どういう意味で「良い」のか – 予測の意味で「良い」 – 将来手に入れるデータをより誤差が小さく予測す ることができるモデルが良いモデルとする
7.
統計モデリング • データ発生メカニズムを知る – データが何らかの分布から発生している –
その発生メカニズムを「確率分布」を使って表現 • 確率分布のパラメータを推測する – 確率分布の形を決める値のこと • 正規分布なら,平均値と分散 – 正規分布以外の確率分布も扱う
8.
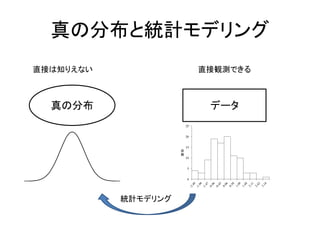
真のモデル≒データ発生メカニズム 真の分布 データ 直接は知りえない 直接観測できる データの発生
9.
真の分布と統計モデリング • 真の分布は完全にはわからない – 真の分布はイデア的存在 –
でも,その分布から生成されたデータのいくつか は手に入っている • 予測の意味で良いモデルを作る – 限られたデータから,最も真の分布から生成され るデータをよりよく予測できるモデルが作りたい
10.
真の分布と統計モデリング 真の分布 データ 直接は知りえない 直接観測できる 統計モデリング
11.
数式的には • 真の分布 q(x) –
なんらかの確率分布であり,それに従ってデータxが生成される • 統計モデル p(x|θ) – パラメータθによってxを予測する • パラメータの分布 p(θ|X) – すでに得たデータXによって推定されたパラメータ • 予測分布 p(x|X) – すでに得たデータXによって将来得られるデータxを予測 – 統計モデルをパラメータの分布で重みづけて平均したもの
12.
データのあてはまりを考える • 真の分布q(x)と予測分布p(x|X)の距離 – カルバックライブラー情報量 –
しかし真の分布はわからないので,とりあえずデータにモデルを近づ けることを考える • 平均予測誤差 – 予測分布から生成されたデータと,真の分布から生成されたデータ の平均的なズレの程度 – 実はKL= H(q) + Gが成り立つ
13.
真の分布はわからない • 平均的な予測誤差は真の分布に依存 – データだけからは,評価することはできない •
そこで尤度で近似的に評価する – 尤度=データとモデルの近さ – 尤度を大きくするモデルは,データを最もうまく説 明できているモデルといえる – ただし,当然バイアスが生じる
14.
データのあてはまりをよくする • モデルの複雑さとデータのあてはまり – モデルを複雑にすればするほど,データとの当てはまり のよさ(尤度)は高くなる –
複雑なモデル=パラメータが多いモデル • オーバーフィッティング – しかし,それはデータの確率的な変動を無視して,過剰に あてはまりを高くしてしまう – これをオーバーフィッティングという – 真の分布の代わりにデータによる推定値を用いることの バイアスは,オーバーフィッティングによって生じる
15.
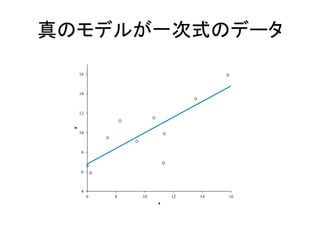
真のモデルが一次式のデータ 4 6 8 10 12 14 16 6 8 10
12 14 16 y x
16.
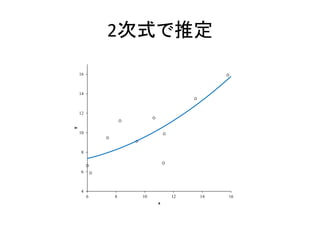
2次式で推定 4 6 8 10 12 14 16 6 8 10
12 14 16 y x
17.
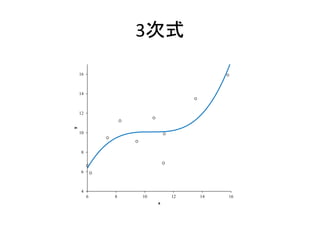
3次式 4 6 8 10 12 14 16 6 8 10
12 14 16 y x
18.
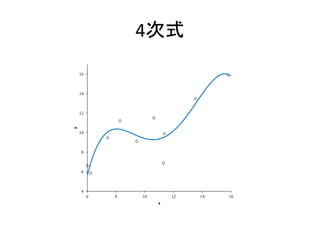
4次式 4 6 8 10 12 14 16 6 8 10
12 14 16 y x
19.
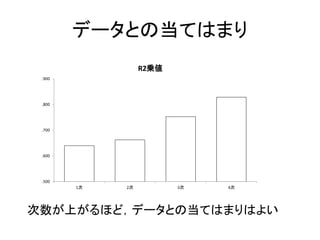
データとの当てはまり .500 .600 .700 .800 .900 1次 2次 3次
4次 R2乗値 次数が上がるほど,データとの当てはまりはよい
20.
将来のデータを予測したい • 今回のデータ「だけ」に当てはまっても仕方ない – どのデータにも,サンプリングのバイアスがある •
たまたまこういうデータである,という可能性 – 今回のデータだけに当てはまっても,将来の予測が 上手くいくとは限らない • モデルの複雑さをむやみに高くしないこと – パラメータが多いと尤度は高くなる – パラメータが多すぎると予測誤差は大きくなる – ほどほどのバランスが必要
21.
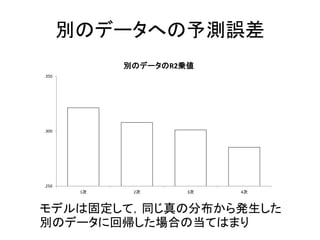
別のデータへの予測誤差 .250 .300 .350 1次 2次 3次
4次 別のデータのR2乗値 モデルは固定して,同じ真の分布から発生した 別のデータに回帰した場合の当てはまり
22.
平均予測誤差を評価する • 赤池情報量規準(AIC) – モデルが最尤法で推定できて,サンプルサイズが十分大 きいとき, –
AIC = -2 * 対数尤度 + 2*パラメータ数 – この値は,平均予測誤差*nの近似値となる • AICの特徴 – AICは,データへのあてはまりの良さ(尤度)と,パラメータ 数で決まる – 対数尤度が高いほど,パラメータ数が少ないほど平均予 測誤差は小さくなる
23.
情報量規準最小のモデルを選ぶ • AICで予測誤差が小さいモデルを選ぶ – モデルごとにAICを計算して,それが最も小さいモ デルが,将来をよりよく予測できるモデルとなる •
AICの制限 – パラメータが正規分布で近似できる – サンプルサイズが大きい – 真の分布をモデルが含んでいる
24.
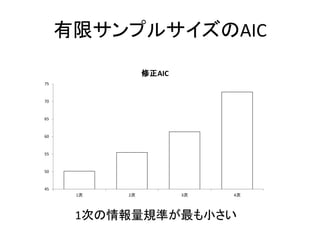
有限サンプルサイズのAIC 45 50 55 60 65 70 75 1次 2次 3次
4次 修正AIC 1次の情報量規準が最も小さい
25.
WAIC • 広く使える情報量規準 – もっと広いモデルにも適用できるように拡張した 情報量規準 •
最尤推定ができないようなモデルでも使うことができる • 真の分布がモデルで実現できなくてもよい • ベイズ統計と相性が良い – MCMC標本から簡単に計算ができる
26.
WAIC • Widely Applicable
Information Criterion – ただし, – 第1項はデータと予測分布の当てはまり,第2項はパ ラメータの分散の和(パラメータの不確実さの和) • WAIC – データと予測分布の距離が小さいほど小さい – パラメータの数が少ないほど小さい – パラメータの分散が小さいほど小さい
27.
階層ベイズってなんだっけ
28.
ベイズ統計 • ベイズの定理による推定 • 事後分布=推定したパラメータの分布 –
データXを得たうえでのパラメータの分布 • 事前分布=データを得る前のパラメータ分布 – P(θ)
29.
統計モデル • P(x|θ) – パラメータθのもとでデータがどのように生成する かを決めるもの •
回帰分析の場合,N(x |βZ,σ) – βは回帰係数,Zは説明変数,σは残差標準偏差 – データが,「平均が予測値βX,σをSD」とする条件 付き正規分布に従うとする確率モデル
30.
階層モデル • パラメータが別のパラメータで予測したい – P(θ|ψ) –
パラメータθがさらに別のパラメータψによってモ デル化できる場合 • 階層線形モデルの場合 N(β|γ,Τ) – グループごとの回帰係数βが,平均γ,共分散行 列Τの多変量正規分布に従う
31.
最尤法の場合 • 直接的に階層モデルを評価するのは難しい – そこで尤度をθで周辺化する(積分消去する) –
ローカルパラメータθについて積分すれば,推定するべき パラメータはグローバルなψのみが残る • 最尤法の困難 – 正規分布以外の場合は,異なる分布を混ぜることになる ので積分が難しい→近似的に尤度を評価する – 分散の推定が不偏推定量ではない
32.
階層ベイズ • ベイズでは階層モデルは自然に推定可能 – パラメータの事前分布としてより高次なパラメータ の分布を想定すればいい –
ローカルパラメータを推定しつつ,グローバルな パラメータの分布制約を置くことが可能 – x ~ P(θ) θによってデータがモデル化 – θ ~ P(ψ) Ψによってθがモデル化
33.
MCMCで階層ベイズも簡単推定! • マルコフ連鎖モンテカルロ法 – 推定値をたくさんサンプリングして事後分布を推定 –
複雑な階層モデルでも,比較的安定してベイズ推定 することができる • MCMCを実行できるソフト – stan・・・今日使うのはこれ! – BUGS – JAGS
34.
階層ベイズでWAIC
35.
階層ベイズでWAIC • 階層モデルは最尤法で難しい場合がある – 階層ベイズ
with MCMCで解いたほうが,自然に モデリングできる(気がする) • MCMCならWAICが使える – MCMCの結果から簡単に計算可能 – これからの時代はWAICによるモデル選択時代が 来る!確実に来る!これで勝つる!
36.
今日使うデータ • 野球のデータ – 2014年のプロ野球野手140名の打撃成績と翌年 の年俸 –
プロ野球Freakからダウンロードできる • http://baseball-freak.com/ • (ただし,年俸のデータはWikipediaから集めた) • glmmstanパッケージに入っている data(baseball)
37.
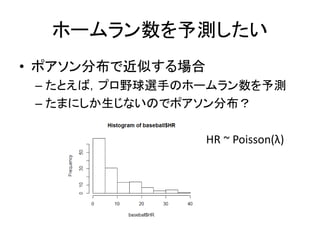
ホームラン数を予測したい • ポアソン分布で近似する場合 – たとえば,プロ野球選手のホームラン数を予測 –
たまにしか生じないのでポアソン分布? HR ~ Poisson(λ)
38.
ポアソン分布を最尤推定 • 最尤推定でλを推定する • 予測分布を生成してみる じぇんじぇん形が違う!
39.
過分散の推定 • 選手ごとの打力を考慮に入れよう – ポアソン分布に従うとして,さらにλがガンマ分布 に従うと考えてみよう –
ガンマ分布ってこんなの • λ~ gamma(θ,θ/μ) – θは形状パラメータ – μは平均値
40.
• ポアソンのλがガンマ分布に従うと仮定した混 合分布 • 選手ごとの個人差を推定できる –
μが平均,θが過分散を表す 負の二項分布
41.
最尤法で負の二項分布 • λとθを推定する
42.
AICを比較してみる • ポアソン – AIC(fit.p) –
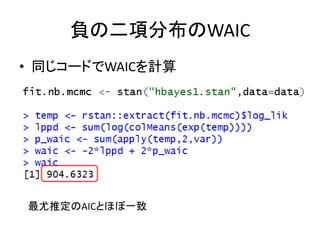
1522.482 • 負の二項分布 – AIC(fit.nb) – 904.9061 – やっぱり,個人差を考慮に入れたほうがいい
43.
階層ベイズで過分散を推定 • 直接,負の二項分布を使ったが・・・ – せっかくなので,ポアソン分布のλが,ガンマ分布 に従うような階層ベイズを組みたい •
ベイズ推定で解く – glmerなどは,対数λが正規分布に従うことを仮定 するが,ガンマ分布などでは推定できない – MCMCで解いてみる
44.
stanにご登場いただく
45.
stanの結果 • 次のコードを走らせる data <-
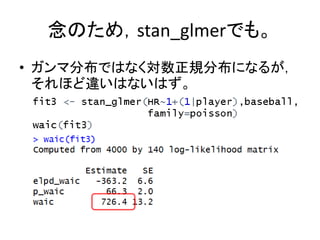
list(y=baseball$HR) fit1 <- stan("hbayes2.stan",data=data, iter=600,warmup=100,chains=2) print(fit1,digits=3,pars=c("m","s")) パラメータを取り出す mu <- mean(rstan::extract(fit1)$m) theta <- mean(rstan::extract(fit1)$s) 負の二項分布と一致
46.
ガンマとポアソンの混合分布 • 先に混合分布の関数を作って・・・ • 予測分布を生成 当たり前だけど負の二項分布と同じ
47.
WAICを計算する
48.
WAICを計算する • WAICはMCMCから簡単に計算できる • WAICは・・・ –
720.3164 – ・・・・んん?低すぎない? – 負の二項分布は904だったが・・・ – 数学的には負の二項分布と同じ分布のはず・・・?
49.
念のため,stan_glmerでも。 • ガンマ分布ではなく対数正規分布になるが, それほど違いはないはず。
50.
blmsパッケージでも • rstanのラッパー
51.
では負の二項分布をベイズ推定
52.
負の二項分布のWAIC • 同じコードでWAICを計算 最尤推定のAICとほぼ一致
53.
なぜだろう? • 予測分布の定義に問題がありそう – 階層ベイズの場合,ローカルパラメータを予測分 布に組み込むことができる •
さらに,ローカルパラメータに分布の制約を置く – これは階層ベイズの長所だが,情報量規準を考 えるときには実は注意が必要になる・・・?
54.
情報量規準をもう一回考える
55.
WAICの二つの計算 • 負の二項分布 • ポアソン+ガンマの階層ベイズ
56.
WAICの二つの計算 • 負の二項分布 • ポアソン+ガンマ分布の階層ベイズ ←対数尤度 ←有効パラメータ数 ←対数尤度 ←有効パラメータ数
57.
周辺化したWAICを計算 • 個々の選手ではなくグローバルな推定をする
58.
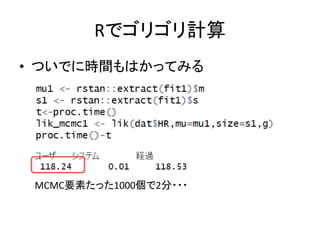
Rでゴリゴリ計算 • ついでに時間もはかってみる MCMC要素たった1000個で2分・・・
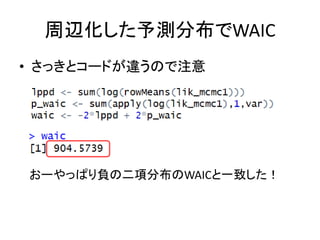
59.
周辺化した予測分布でWAIC • さっきとコードが違うので注意 おーやっぱり負の二項分布のWAICと一致した!
60.
階層ベイズの尤度 • 階層モデルを周辺化せずにモデリングできる – 積分の評価が難しいモデルでも解くことができる •
周辺化してもしなくても推定値は一緒 – 負の二項分布とポアソン×ガンマは,平均や分散パ ラメータの推定値は全く同じ • 予測分布が変わってくる – 周辺化せずローカルパラメータで予測分布を構築す るか,ローカルパラメータを消して,グローバルパラ メータだけで構築するかどうかが違う
61.
情報量規準とパラメータ • 平均的な予測誤差を推定 – 将来得られるデータが,統計モデルとパラメータ によってどれくらい正確に予測できるか –
パラメータに何を使うかによって,当然予測の精 度は変わってくる • WAICにローカルパラメータを使う,使わない – グローバルなパラメータのみを使って予測分布を 構築するか,ローカルパラメータも使うかで情報 量規準は意味が変わる
62.
ホームランの場合 • ポアソン分布 – 140人の打力が全員等しいと過程 •
負の二項分布 – 140人の平均的な打力と,その個人差を分散パラメータで 「グローバルにモデル化」 – 「一般的に,これぐらいばらつく」を推定 • ポアソン分布+ガンマ分布の階層ベイズ – 140人の平均的な打力をポアソンで,打力の個人差を ローカルパラメータとして個々に推定 – 「それぞれの選手の打力はこれぐらい」を推定
63.
予測の意味が違う? • 選手の個人ごとの打力に基づくWAIC – 「今回と同じ選手を対象」にデータをとった場合の予 測誤差を評価している •
今回の選手はそれぞれこれぐらいの打力だから,来年も ホームランの分布はこんな感じになるでしょう • グローバルパラメータに基づくWAIC – 「プロ野球選手一般」からデータをとった場合の予測 誤差を評価している • プロ野球選手の打力はこれぐらいばらついてるから,ホー ムラン分布の形はこんな感じになるでしょう
64.
過分散判断における注意 • 過分散とAIC – 過分散を変量効果として推定するほうがいいか は,最尤法の場合AICで判断できる •
階層ベイズでWAICを使って判断は・・・? – 階層ベイズでそのままWAICを計算すると,予測 の意味が変わって比較できない • 同じ対象からデータをとると仮定できるならOKだがあ まりそういうことは想定しにくい – 負の二項分布からのWAICなら比較OKだと思う
65.
過分散判断には既存の分布で • ポアソンの場合 – 負の二項分布で,過分散をグローバルパラメータ として推定できる •
二項分布の場合 – ベータ二項分布を使えば分散をベータ分布で推 定できる
66.
階層線形モデルの場合 • HLMにおける変量効果の評価 – 正規分布が仮定できるモデルの場合は,周辺化 した尤度を評価することができる –
なのでグローバルパラメータに基づくWAICは計算 可能
67.
Gはグループ数 Qは変量効果の数 yは従属変数 xは説明変数 betaは固定効果 scaleは残差分散 rは変量効果
68.
自力で計算ができないわけではない • Rで数値積分すれば計算できる – ただし,MCMC1000回,次元が1次元,パラメータ 数が2で2分 –
二次元になると,飛躍的に計算時間が増える – 元のモデル推定よりも情報量規準のほうが時間 がかかるとか笑える(いや,笑えない)
69.
ローカルパラメータを活用できる場合 • 都道府県,国などを変量効果にする場合 – 都道府県や国は多分来年でも変わらない –
推定したパラメータは予測に使える • 固定効果だけを選択する場合 – 推定したローカルパラメータによる予測誤差のバ イアスは,モデル間では(たぶん)変わらない – 固定効果を増やすことで相対的にWAICが下がる なら,それは増やしたモデルのほうがたぶんいい
70.
階層ベイズが問題なわけではない • 推定値は正しいし,ローカルパラメータの推 定も正しい – ガンガン,階層ベイズ使っていこう •
変量効果のグローバルパラメータに対する WAICによる評価に注意
71.
glmmstanパッケージ ver1.30 • しみづが作ったパッケージ –
library(devtools) – install_github("norimune/glmmstan") • 負の二項分布,ベータ二項分布に対応 – 過分散評価にはこちらのWAICを見るといいと思う • 階層線形モデルのグローバルなWAICに対応 – 普通のWAICとWAIC_gの両方が出力される – ただし,変量効果の組が一つの場合のみ
72.
ベータ二項分布 • 打率がリーグで違う? – 二項分布を仮定して,かつ,打力の分散を推定
73.
HLMのWAIC • 年俸の対数は正規分布に従う – ホームランを打つと年俸はいくら増えるか –
また,その効果は球団によって違う? • 最尤法の結果 両方のタイプの WAICを参照できる
74.
おまけ
75.
階層ベイズに限った話ではない • 因子分析も隠れパラメータがある – 因子得点 •
ベイズを使えば因子得点を推定しながら因子 分析ができる
76.
因子得点を推定しないバージョン • 共分散行列と多変量正規分布を使う – 要は項目の相関をどうモデル化するかの違い
77.
WAICは両者で違う • 因子得点を推定して,WAICを計算 – 個々の項目ごとに正規分布を仮定 •
因子得点を推定せずにWAICを計算 – 全部の項目に多変量正規分布を過程
78.
WAICは両者で違う • 因子得点を推定した場合 • 因子得点を推定しない場合
79.
まとめ • 階層モデルをベイズで – 最尤法では近似計算しかできないし,分散の推定も 不偏推定量にならない –
ベイズを使えば,自然に階層モデルを推定できる • 階層ベイズでモデル選択 – WAICで,ベイズ推定でもモデル選択ができる – ただ,ローカルパラメータを既知として扱ってしまう。 – グローバルパラメータのみのWAICの推定も可能だが, 場合によっては大変。
80.
Enjoy stan! @simizu706
Download