Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Hiroshi Shimizu
PDF, PPTX
11,847 views
心理学におけるベイズ統計の流行を整理する
ベイズ塾のベイズ統計モデリングワークショップで発表したスライドです。
Data & Analytics
◦
Read more
7
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 68
2
/ 68
3
/ 68
4
/ 68
5
/ 68
6
/ 68
7
/ 68
8
/ 68
9
/ 68
10
/ 68
11
/ 68
12
/ 68
13
/ 68
14
/ 68
15
/ 68
16
/ 68
17
/ 68
18
/ 68
19
/ 68
20
/ 68
21
/ 68
22
/ 68
Most read
23
/ 68
24
/ 68
25
/ 68
26
/ 68
27
/ 68
28
/ 68
29
/ 68
30
/ 68
31
/ 68
32
/ 68
33
/ 68
34
/ 68
Most read
35
/ 68
36
/ 68
37
/ 68
38
/ 68
39
/ 68
40
/ 68
41
/ 68
42
/ 68
43
/ 68
44
/ 68
45
/ 68
46
/ 68
47
/ 68
48
/ 68
49
/ 68
50
/ 68
51
/ 68
52
/ 68
53
/ 68
54
/ 68
55
/ 68
56
/ 68
57
/ 68
58
/ 68
59
/ 68
60
/ 68
61
/ 68
Most read
62
/ 68
63
/ 68
64
/ 68
65
/ 68
66
/ 68
67
/ 68
68
/ 68
More Related Content
PDF
2 3.GLMの基礎
by
logics-of-blue
PDF
心理学者のためのJASP入門(操作編)[説明文をよんでください]
by
daiki hojo
PDF
一般化線形混合モデル入門の入門
by
Yu Tamura
PDF
社会心理学とGlmm
by
Hiroshi Shimizu
PPT
100614 構造方程式モデリング基本の「き」
by
Shinohara Masahiro
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
PDF
これからの仮説検証・モデル評価
by
daiki hojo
PDF
2012-1110「マルチレベルモデルのはなし」(censored)
by
Mizumoto Atsushi
2 3.GLMの基礎
by
logics-of-blue
心理学者のためのJASP入門(操作編)[説明文をよんでください]
by
daiki hojo
一般化線形混合モデル入門の入門
by
Yu Tamura
社会心理学とGlmm
by
Hiroshi Shimizu
100614 構造方程式モデリング基本の「き」
by
Shinohara Masahiro
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
これからの仮説検証・モデル評価
by
daiki hojo
2012-1110「マルチレベルモデルのはなし」(censored)
by
Mizumoto Atsushi
What's hot
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PDF
StanとRでベイズ統計モデリング読書会 Chapter 7(7.6-7.9) 回帰分析の悩みどころ ~統計の力で歌うまになりたい~
by
nocchi_airport
PDF
Stanの便利な事後処理関数
by
daiki hojo
PPTX
ベイズ統計モデリングと心理学
by
Shushi Namba
PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
PDF
ベイズモデリングと仲良くするために
by
Shushi Namba
PDF
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
PPTX
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
PPTX
ベイズファクターとモデル選択
by
kazutantan
PDF
負の二項分布について
by
Hiroshi Shimizu
PPTX
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
PDF
Stanでガウス過程
by
Hiroshi Shimizu
PDF
Rで階層ベイズモデル
by
Yohei Sato
PDF
2 6.ゼロ切断・過剰モデル
by
logics-of-blue
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
PDF
2 4.devianceと尤度比検定
by
logics-of-blue
PDF
合成変量とアンサンブル:回帰森と加法モデルの要点
by
Ichigaku Takigawa
PDF
Stan超初心者入門
by
Hiroshi Shimizu
階層ベイズとWAIC
by
Hiroshi Shimizu
StanとRでベイズ統計モデリング読書会 Chapter 7(7.6-7.9) 回帰分析の悩みどころ ~統計の力で歌うまになりたい~
by
nocchi_airport
Stanの便利な事後処理関数
by
daiki hojo
ベイズ統計モデリングと心理学
by
Shushi Namba
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
ベイズモデリングと仲良くするために
by
Shushi Namba
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
Stanコードの書き方 中級編
by
Hiroshi Shimizu
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
ベイズファクターとモデル選択
by
kazutantan
負の二項分布について
by
Hiroshi Shimizu
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
Stanでガウス過程
by
Hiroshi Shimizu
Rで階層ベイズモデル
by
Yohei Sato
2 6.ゼロ切断・過剰モデル
by
logics-of-blue
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
2 4.devianceと尤度比検定
by
logics-of-blue
合成変量とアンサンブル:回帰森と加法モデルの要点
by
Ichigaku Takigawa
Stan超初心者入門
by
Hiroshi Shimizu
Similar to 心理学におけるベイズ統計の流行を整理する
PDF
認知心理学への実践:データ生成メカニズムのベイズモデリング【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
PPTX
ベイズモデリングで見る因子分析
by
Shushi Namba
PDF
確率統計-機械学習その前に v2.0
by
Hidekatsu Izuno
PDF
階層ベイズによるワンToワンマーケティング入門
by
shima o
PDF
Bayesian Sushistical Modeling
by
daiki hojo
PDF
PRML第3章_3.3-3.4
by
Takashi Tamura
PDF
3.4
by
show you
PDF
ベイズ統計入門
by
Miyoshi Yuya
PDF
20190512 bayes hands-on
by
Yoichi Tokita
PPTX
要因計画データに対するベイズ推定アプローチ
by
Takashi Yamane
PDF
岩波データサイエンス_Vol.5_勉強会資料01
by
goony0101
PDF
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会
by
Shushi Namba
PPTX
日本教育心理学会2016WSスライド
by
考司 小杉
PDF
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PPTX
HCG20181212
by
考司 小杉
PDF
【複雑系/内部勉強会】6章_Psychological Network Models
by
yoshikicis
PPTX
HCGシンポジウム2018;心理学における新しい統計学との付き合い方
by
考司 小杉
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
PDF
ベイズ主義による研究の報告方法
by
Masaru Tokuoka
PDF
Prml3 4
by
K5_sem
認知心理学への実践:データ生成メカニズムのベイズモデリング【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
ベイズモデリングで見る因子分析
by
Shushi Namba
確率統計-機械学習その前に v2.0
by
Hidekatsu Izuno
階層ベイズによるワンToワンマーケティング入門
by
shima o
Bayesian Sushistical Modeling
by
daiki hojo
PRML第3章_3.3-3.4
by
Takashi Tamura
3.4
by
show you
ベイズ統計入門
by
Miyoshi Yuya
20190512 bayes hands-on
by
Yoichi Tokita
要因計画データに対するベイズ推定アプローチ
by
Takashi Yamane
岩波データサイエンス_Vol.5_勉強会資料01
by
goony0101
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会
by
Shushi Namba
日本教育心理学会2016WSスライド
by
考司 小杉
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
HCG20181212
by
考司 小杉
【複雑系/内部勉強会】6章_Psychological Network Models
by
yoshikicis
HCGシンポジウム2018;心理学における新しい統計学との付き合い方
by
考司 小杉
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
ベイズ主義による研究の報告方法
by
Masaru Tokuoka
Prml3 4
by
K5_sem
More from Hiroshi Shimizu
PDF
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
PDF
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
PDF
SapporoR#6 初心者セッションスライド
by
Hiroshi Shimizu
PDF
Tokyo r53
by
Hiroshi Shimizu
PDF
glmmstanパッケージを作ってみた
by
Hiroshi Shimizu
PDF
媒介分析について
by
Hiroshi Shimizu
PPTX
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
PDF
Rで潜在ランク分析
by
Hiroshi Shimizu
PDF
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
PPTX
Latent rank theory
by
Hiroshi Shimizu
PDF
エクセルでテキストマイニング TTM2HADの使い方
by
Hiroshi Shimizu
PPTX
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
PPTX
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
PPTX
Excelでも統計分析 HADについて SappoRo.R#3
by
Hiroshi Shimizu
PDF
エクセルで統計分析2 HADの使い方
by
Hiroshi Shimizu
PDF
エクセルで統計分析4 因子分析のやり方
by
Hiroshi Shimizu
PDF
エクセルで統計分析3 回帰分析のやり方
by
Hiroshi Shimizu
PDF
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
PDF
Mplusの使い方 中級編
by
Hiroshi Shimizu
PDF
Mplusの使い方 初級編
by
Hiroshi Shimizu
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
SapporoR#6 初心者セッションスライド
by
Hiroshi Shimizu
Tokyo r53
by
Hiroshi Shimizu
glmmstanパッケージを作ってみた
by
Hiroshi Shimizu
媒介分析について
by
Hiroshi Shimizu
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
Rで潜在ランク分析
by
Hiroshi Shimizu
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
Latent rank theory
by
Hiroshi Shimizu
エクセルでテキストマイニング TTM2HADの使い方
by
Hiroshi Shimizu
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
Excelでも統計分析 HADについて SappoRo.R#3
by
Hiroshi Shimizu
エクセルで統計分析2 HADの使い方
by
Hiroshi Shimizu
エクセルで統計分析4 因子分析のやり方
by
Hiroshi Shimizu
エクセルで統計分析3 回帰分析のやり方
by
Hiroshi Shimizu
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
Mplusの使い方 中級編
by
Hiroshi Shimizu
Mplusの使い方 初級編
by
Hiroshi Shimizu
心理学におけるベイズ統計の流行を整理する
1.
心理学における【ベイズ統計】の 流行を整理する 清水裕士 関西学院大学 社会学部
2.
自己紹介 • 清水裕士 – 関西学院大学社会学部 •
専門 – 社会心理学 • Web – Twitter: @simizu706 – Website: http://norimune.net
3.
ワークショップの流れ • 午前 – ベイズ統計の流行についての交通整理 •
および、ワークショップの趣旨について – 仮説検証・モデル評価についての解説 • JASPの紹介、ベイズファクターについての解説 • 午後 – ベイズモデリングの実践例 • 基礎から臨床まで、さまざまな角度からモデリング例を紹介 – これからモデリングをする人のための学びルート • 実際にモデリングする・論文を書くための知識など
4.
本ワークショップで言いたいこと
5.
本ワークショップで言いたいこと × 頻度主義をやめてベイズ主義でやろうぜ ○ 心理学でモデリングやっていこうぜ
6.
本ワークショップで言いたいこと × p値やめてベイズファクター使おうぜ ○ モデル評価の観点は様々あるぜ
7.
本ワークショップで言いたいこと × t検定とか分散分析やめようぜ ○ モデリングと伝統的手法は共存する
8.
本ワークショップで言いたいこと ○ MCMC最高(*´Д`)ハァハァ ○ モデリングはいいぞ ※効果には個人差があります
9.
ところで最近・・・
10.
ベイズの本めっちゃ出てる
11.
ベイズの本めっちゃ出てる
12.
ベイズの本めっちゃ出てる
13.
今日の僕のお話 • ベイズ統計学についての整理 – なんかいろいろみんなベイズベイズ言っちゃって るけど、いったい何なの? –
どういう流行なの? • ベイズ統計モデリング推し – 統計モデリングって何? – ベイズとどういう関係にあるの? – 伝統的な手法(t検定や分散分析)とどう違うの?
15.
特集号「統計革命」 • 三浦麻子・岡田謙介・清水裕士 企画 –
オープンサイエンス – 仮説評価 – モデリング – 論文書く側だけでなく、査読する側にとってもこれ から必須になる知識を得るための道しるべ
16.
近日公刊!
17.
清水(印刷中)
18.
ベイズ統計学の流行 • ずっと昔からベイズの長所は指摘されてきた – 今に始まった話ではない •
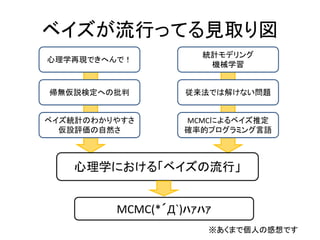
ではなぜ、最近特に、心理学で「ベイズ統計」 という言葉をよく聞くの? • ここでは大きく分けて2つの理由を挙げたい – 心理学の再現性問題 – 統計モデリングとMCMCのコラボがハマった
19.
ベイズ統計学の流行 • 理由1:伝統的な仮説検定の限界 – 再現性問題 –
QRPに、伝統的統計学のわかりづらさも原因 – 仮説検定の代替手段としてのベイズ統計 • 理由2:統計モデリングの発展 – 実験系・社会科学系でモデリング手法が発展 – GLMM以降は最尤法では限界 – 確率的プログラミング言語でより柔軟なモデル – ベイズ統計モデリングが注目を得ている
20.
ベイズが流行ってる見取り図 心理学再現できへんで! 帰無仮説検定への批判 ベイズ統計のわかりやすさ 仮設評価の自然さ 統計モデリング 機械学習 従来法では解けない問題 MCMCによるベイズ推定 確率的プログラミング言語 MCMC(*´Д`)ハァハァ 心理学における「ベイズの流行」 ※あくまで個人の感想です
21.
伝統的な仮説検定の限界
22.
• 経験科学における大前提 –同じ条件・同じ手続きで実験を行えば,同じ 結果が得られる • 心理学における再現性の保証 –統計的検定の利用 実験結果の再現性 p値
23.
心理学実験再現できへんで?
24.
心理学の再現性問題 • 実験結果が再現されない – 疑わしい研究実践:QRP •
有意になるまでデータを足す • いろんな指標で検定を試す • データを見た後で仮説を設定する:HARKing • 有意性検定に対する過度な信頼と圧力 – 統計的に有意な結果なら大丈夫 – とりあえず有意にならないと論文にならない
25.
仮説検定からもう一歩 • p値「だけ」からの脱却 – 効果量に注目しよう –
信頼区間に注目しよう • 仮説検定からの脱却 – ベイズ統計の可能性 – より自由な仮説設定へ – 予測に使いやすい
27.
頻度主義からベイズ統計へ • 仮説検定がどうも変な理屈である – 帰無仮説を設定して,それが間違えていることをデー タで示す –
95%信頼区間は,同じサンプルサイズのデータをたく さんとったときに,その範囲に真値が95%の確率で含 まれる区間のこと • ベイズのほうが直感に合う? – 研究仮説が正しい確率がわかる – パラメータの確率的範囲が直接わかる
28.
ベイズファクター • ベイズ統計学における仮説評価の基準 – 仮説Aと仮説Bのどちらが確からしいかを比率で 表す –
仮説AがBより何倍確からしい • みたいな • モデル比較・仮説評価は北條さんの発表で 触れますのでお楽しみに
29.
本ワークショップで言いたいこと × 頻度主義をやめてベイズ主義でやろうぜ ○ 心理学でモデリングやっていこうぜ
30.
ベイズ統計モデリング • 心理学で流行りつつある方法論 – 特に、ベイズ認知モデリング
31.
統計モデリングとは? • 確率モデルをデータに当てはめて現象の理 解と予測を促す営み – 松浦(2016) •
伝統的な手法も含まれる? – そのとおり – しかし、強調点が少し違う
32.
たとえば回帰分析 • 𝑌𝑖 =
𝛼 + 𝛽 𝑋𝑖 + 𝑟𝑖 • 𝑟𝑖~ 𝑁𝑜𝑟𝑚𝑎𝑙 0, 𝜎 – 切片𝛼、回帰係数𝛽 – 残差が正規分布に従う • 平均0、残差分散𝜎2 • データ生成についての確率モデル – 𝑌𝑖 ~ 𝑁𝑜𝑟𝑚𝑎𝑙 𝜇𝑖, 𝜎 :確率的関係 – 𝜇𝑖 = 𝛼 + 𝛽𝑋𝑖 :確定的関係 • 上と同じモデル
33.
平均𝜇𝑖 = 𝛼
+ 𝛽𝑋𝑖の正規分布 青い破線は95%予測区間
34.
データ生成メカニズムを考える? • データがどういう確率的+確定的な法則で得 られるのかを考える • 心理学的なデータ生成の発想 –
母集団に特定の確率分布を仮定して、そこから サンプリングされたものがデータ • つまりは、母集団分布の想定がデータ生成メカニズム のスタート – あるいは、行動生起確率を考えて、その確率が どういうメカニズムで説明できるか
35.
伝統的なデータ分析手法との違い • t検定や分散分析との違いは? – 数理的には統計モデリングの範疇 •
なんだけども、目的がちょっと違う – 実験計画法とセットになった手法である – 因果効果の推定が主眼である – 効果の差から、心理メカニズムを推論
36.
例:ストループ課題 • 統制群と実験群 – 統制群:色パッチの色を答える –
実験群:色文字の色を答える • 色と文字の意味内容が不一致な場合に、回答時間が 遅れる • 認知的葛藤を反応時間の差で取り出す – 群間の「差」から、その背後にある心理的なメカニ ズムを推論・検証する 黄 緑
37.
統計モデリングは? • データ生成を確率分布で表現する – 𝑌𝑖
~ 𝑁𝑜𝑟𝑚𝑎𝑙 𝜇𝑖, 𝜎 • 確率分布のパラメータに構造を想定する – 𝜇𝑖 = 𝛼 + 𝛽𝑋𝑖 • 現象の説明や予測を行う – 推定されたパラメータや、確率モデルそのものを 使って現象の説明や予測を行う
38.
例:遅延価値割引 • 今すぐもらえる5000円 • 1年後にもらえる5000円 –
どっちがほしい? • 多くの人は今すぐの5000円がほしい – では、1年後の5000円は、今すぐでいえばどれぐ らいの価値と同じぐらいになるのか? – 1年後の1万円と比較したらどうなる?
39.
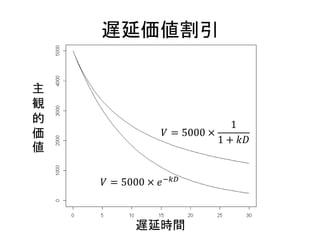
遅延価値割引 • 指数割引(複利計算モデル) – 𝑉
= 元の価値 × 𝑒−𝑘𝐷 – 𝑉は主観的価値、𝑘は割引率、𝐷は遅延時間 – 時間によって主観的価値の減少率が一定 • 双曲割引(単利計算モデル) – 𝑉 = 元の価値 × 1 1+𝑘𝐷 – 時間が経つと主観的価値の減少率が小さくなる
40.
遅延価値割引 𝑉 = 5000
× 1 1 + 𝑘𝐷 𝑉 = 5000 × 𝑒−𝑘𝐷 遅延時間 主 観 的 価 値
41.
行動生起メカニズム • 即時報酬と遅延報酬、どちらを選択するか – 即時報酬:いますぐ5000円 –
遅延報酬:1年後の1万円 • 選択が行動データ – 二値データ – 即時報酬を選択する確率𝜃を推定したい
42.
行動生起メカニズム • 𝑌~𝐵𝑒𝑟𝑛𝑜𝑢𝑙𝑙𝑖(𝜃) – ベルヌーイ分布(二値データの確率分布) –
𝑌:いますぐ5千円か、12か月後に1万円かの選択 • 選択確率𝜃の心理メカニズムを想定する – 𝑉𝑖 = 5000: 即時報酬の主観的価値 – 𝑉𝑑 = 10000 1+𝑘∗12 : 遅延報酬の主観的価値 – 𝜃 = 1 1+exp 𝛽 𝑉 𝑖−𝑉 𝑑 • ロジスティックモデル • 𝛽は主観的価値に従って行動選択する程度(逆温度) もしk=0.1なら、𝑉𝑑 = 4545
43.
どのモデルが妥当なの? • 双曲割引と指数割引どっちが正しい? – 本当のところどれが正しいのかはわからない –
しかし、手元にあるデータから考えてどっちが 合ってるのか、どっちが予測力がありそうかは検 討できるかもしれない • モデル評価・モデル比較 – 次の北條さんのトークを待て!
44.
ここまでのまとめ • 統計モデリング – 行動の生成メカニズムを確率分布で表現 –
パラメータに構造(確定的関係)を想定して、心理 メカニズムを数理的に表現する – 必要に応じてモデル比較 • 伝統的な心理学の分析手法 – 実験計画と因果推論の枠組み – 群間の「差」から心理メカニズムを推論
45.
伝統的な分析手法との考え方の違い • 伝統的な手法 – 「差」を出すことに焦点があたっている –
緻密に設計された実験計画法と、有意な「差」か ら、その背後にある心理メカニズムを一つずつ確 かめていくというパラダイム • 線形モデル+有意性検定という枠組み – 有意性検定の結果が正しければ、データがどう いう分布なのかはあまり気にならない
46.
伝統的な分析手法との考え方の違い • 正規分布に近づけるためのデータ変換 – 対数変換などを施して正規分布に近づける –
→統計モデリングでは極力得られたデータそのもの の生成メカニズムを考えたい • 標準誤差や自由度の補正 – モデルにデータが合わない場合(不均一分散や系列 相関など)に補正を行う – →補正をするのではなく、モデルそのものを構築しな おしたい
47.
ちょっと待って
48.
ベイズどこいったの?
49.
ベイズ推定と統計モデリング • ベイズはどう関わるの? – 統計モデリングにおいてベイズは「本質的な」要 素ではない –
しかし、ベイズ統計ととても相性がよい • ベイズと相性がいい理由 – 階層モデルが容易に構築可能 – MCMC+確率的プログラミング言語の利用
50.
階層モデルが容易に構築可能 • 階層モデルとは – 確率分布のパラメータに、確率分布を仮定するモデル –
マルチレベルモデルなどがそれに該当 • 階層線形モデル – 個人を𝑖,集団をjで表現 – 𝑌𝑖𝑗 ~ 𝑁𝑜𝑟𝑚𝑎𝑙 𝜇𝑖𝑗, 𝜎 – 𝜇𝑖𝑗 = 𝛼𝑗 + 𝛽𝑋𝑖 – 𝛼𝑗 ~ 𝑁𝑜𝑟𝑚𝑎𝑙(𝛾, 𝜏):𝛼に確率分布が仮定される • 切片が集団ごとで異なり、それが正規分布に従うというモデル
51.
ベイズと階層モデル • 最尤法の場合 – 頻度主義ではパラメータは固定値 –
パラメータに確率分布の想定ができない – よって、階層モデルを解くには階層化したいパラメー タを積分して尤度関数からなくす必要がある • これは、多くの場合、困難 • ベイズの場合 – パラメータに確率分布を想定可能 – よって、ごく自然に階層モデルを表現可能
52.
階層モデルの利点 • 想定したモデルの個人差を考える – 遅延価値割引の例 •
双曲割引の割引率kに個人差を考える • 全員が同じ割引率であると考えるのは仮定が強すぎる – しかし、個人ごとに別々のモデルを想定すると、推定の精 度は悪くなる • 割引率に確率分布を仮定する – 𝑉𝑖 = 1 1+𝑘 𝑖 𝐷 – 𝑘𝑖 ~ 𝑁𝑜𝑟𝑚𝑎𝑙 𝜇 𝑘, 𝜎 𝑘 • 割引率𝑘がさらに正規分布に従うモデル • 割引率の個人差に緩い制約を置くことで、推定を安定化
53.
MCMCによるベイズ推定 • マルコフ連鎖モンテカルロ法 – 詳しくはたくさん書籍が出てるのでご覧ください •
MCMCの何がいいのか – 汎用的な推定アルゴリズム • 大抵のモデルを解くことができる – パラメータの分布情報がすべて手に入る • 推定精度が正確に評価できる • 予測分布の計算などが容易にできる
54.
確率的プログラミング言語 • 松浦(2016)による定義 – 様々な確率分布の関数や尤度の計算に特化した関 数が豊富に用意されており,確率モデルをデータに あてはめることを主な目的としたプログラミング言語 –
Probabilistic Programming Language : PPL • ざっくりいえば – 用意された豊富な確率分布によって確率モデルを記 述するだけで、パラメータが推定可能 – MCMCなどの汎用的な解法アルゴリズムによって可 能になった
55.
PPLにはどんなものがあるの? • WinBUGS – 結構昔からあるやつ –
今使ってる人は少ないかも • JAGS – WinBUGSと同じような文法で動く – 比較的使いやすいが、開発スピードは遅め • Stan – Gelmanのチームが作ってる – 開発がまだまだ進んでいて、機能も多様 • 他にもいろいろある
56.
PPL(Stan)で回帰分析 • 読み込むデータ – サンプルサイズ:
𝑁 – 目的変数:𝑌 – 説明変数:X • 推定したいパラメータ – 切片:𝛼 – 係数:𝛽 – 残差SD:𝜎 • 推定したいモデル – 𝜇𝑖 = 𝛼 + 𝛽𝑋𝑖 – 𝑌𝑖 ~ 𝑁𝑜𝑟𝑚𝑎𝑙 𝜇𝑖, 𝜎
57.
遅延価値割引の例 • 𝑉𝑑 =
5000 × 1 1+𝑘𝐷 𝑠 – 双曲線に指数sをつけたモデル – これを最尤法で自力で解こうとすると結構大変 • PPLならこのモデルの式を書くだけでOK
58.
MCMC+PPLのパワー • これまでの統計ソフト – 新しい分析法に対応するのは時間がかかる •
Rであっても、パッケージが出るまでラグがある – 自分で新しいモデルを作ったら・・・? • 自分で解くためのアルゴリズムを用意する必要 • MCMC+PPL – モデルの数式を書くだけで勝手に解いてくれる – 先行研究をベースに、自分なりのアレンジを加えたい 場合でも、すぐに対応することができる
59.
ベイズ統計モデリングによって • Carlin and
Chib (1995) – 「どんなモデルを利用するかどうかは,ユーザーの想 像力によってのみ制限される」 – 「解けない」という制約によって心理学のモデル構築 に制限がかけられることはかなり減る • 逆に言えば, – 研究者側にその自由に答えるための知識や洞察力, 数学的な素養などが求められる・・・。
60.
ベイズ統計モデリングと 伝統的な手法の共存
61.
なぜ心理学で統計モデリングなのか • 理論に基づいた行動生起メカニズムを表現 – これまでは理論で想定された心理指標の推定を簡便 的にしか推定できないものも多かった •
例:信号検出理論、遅延価値割引・・・ – モデルを数学的に表現できるようになる • 強いモデルへのシフト • 分析の透明性・再生可能性が高くなる – PPLによってどういうモデルを作ったか一目瞭然 – 誰でも、いつでも同じ分析ができる – プレレジストレーションで先に公開するのもアリ
62.
分散分析「僕はもういらない子なの?」
63.
本ワークショップで言いたいこと × t検定とか分散分析やめようぜ ○ モデリングと伝統的手法は共存する
64.
いらない子じゃない • モデリングと排他的な存在ではない – なぜなら目的が違うから •
分散分析など実験計画法とセットの手法 – 因果推論に対して強い武器を持っている • 統計モデリング – 心理メカニズムを数理的に表現し、パラメータを推定 する – モデル構築に対して強い武器
65.
共存も可能 • 遅延価値割引の例 – 階層モデルによって推定された割引率 –
個人差を表すパラメータ • 衝動性などの心理的な特徴を示すといわれている • 割引率と別の変数の相関、群間の「差」 – 推定されたパラメータ+伝統的な統計手法 – 他の変数との相関・因果効果を見ることも可能 – もちろん、どの割引率のモデルが有効かも検討する
66.
あえて言うなら・・ • ある一部に見られる – 「やみくも」に正規分布を仮定した線形モデルに データを当てはめて, –
有意性「だけ」を確認するような分析手法 • いわゆる「ブラックボックス統計学」 – 久保(2012) – 統計モデリングの登場によって影を潜めていく可 能性はある・・・。
67.
本ワークショップで言いたいこと ○ MCMC最高(*´Д`)ハァハァ ○ モデリングはいいぞ ※効果には個人差があります
68.
ご清聴ありがとうございました
Download




































































![心理学者のためのJASP入門(操作編)[説明文をよんでください]](https://cdn.slidesharecdn.com/ss_thumbnails/test-180307053956-thumbnail.jpg?width=640&height=640&fit=bounds)

































































