Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Hiroshi Shimizu
28,753 views
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
「StanとRでベイズ統計モデリング」の読書会発表資料です。 今回の発表は導入編(1章~3章)です。 初回ということもあって,本の内容以外に清水が補足説明を加えているところもあります。
Data & Analytics
◦
Read more
47
Save
Share
Embed
Embed presentation
Download
Downloaded 459 times
1
/ 131
2
/ 131
3
/ 131
4
/ 131
5
/ 131
6
/ 131
7
/ 131
8
/ 131
9
/ 131
10
/ 131
11
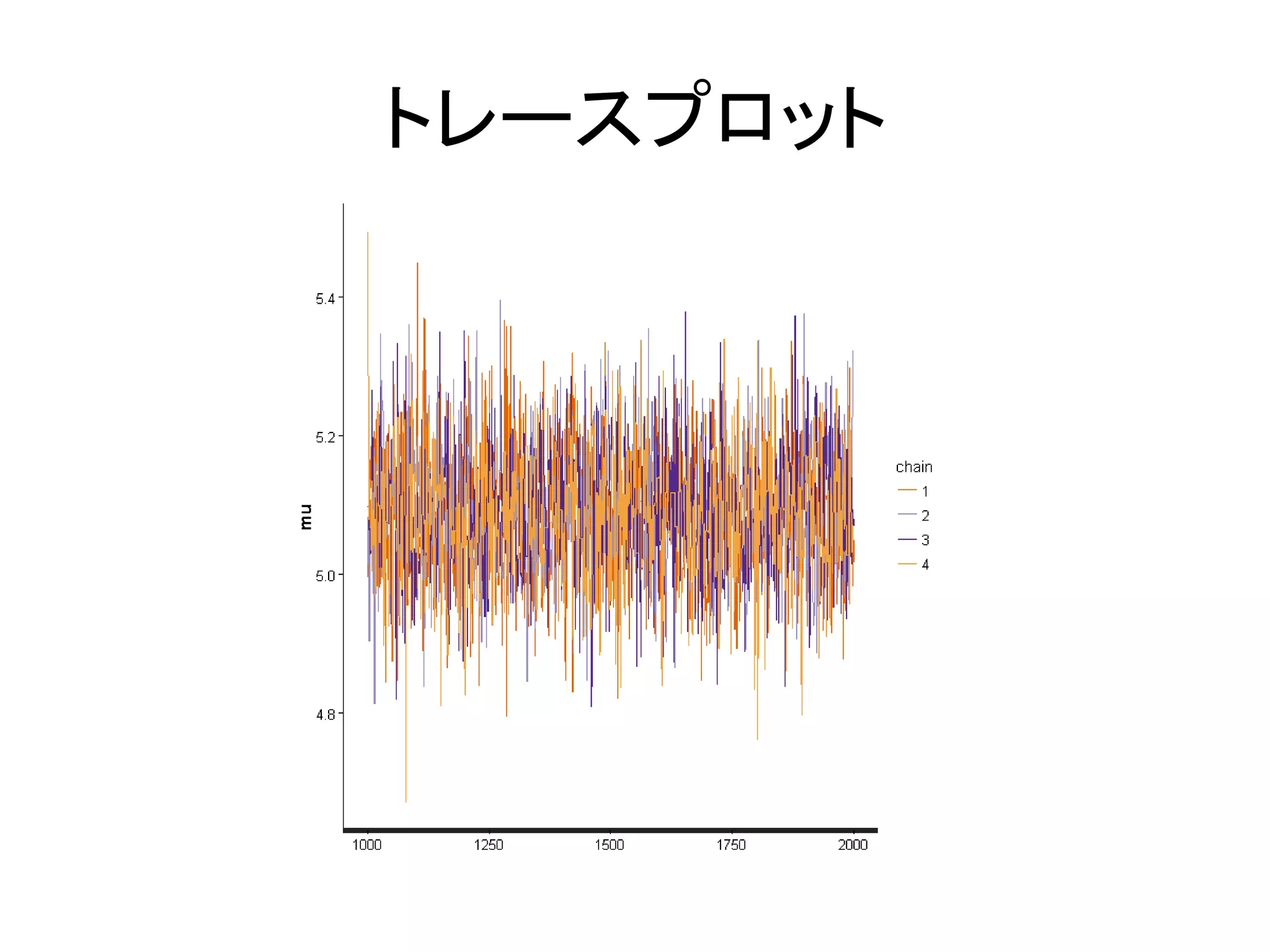
/ 131
12
/ 131
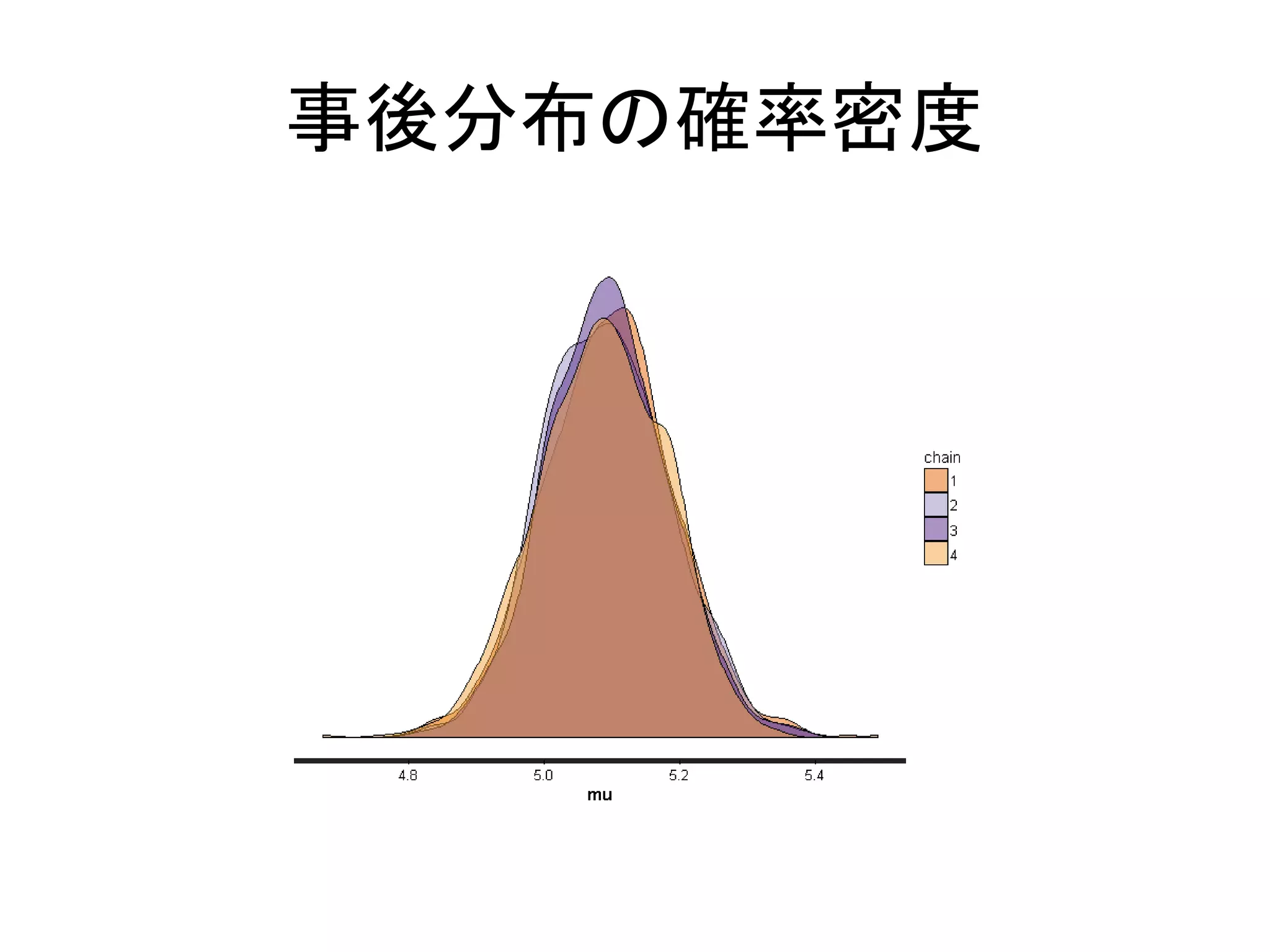
13
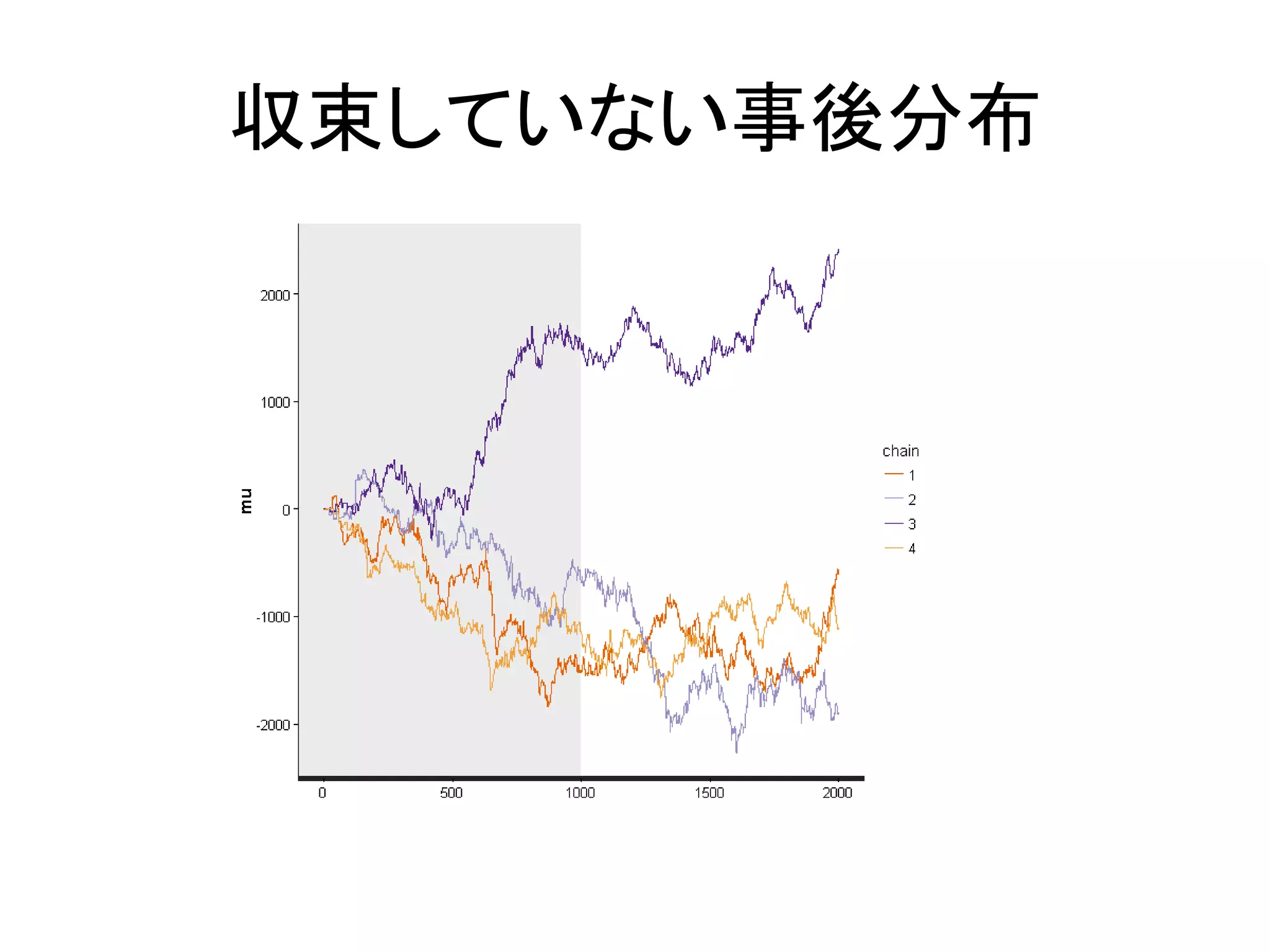
/ 131
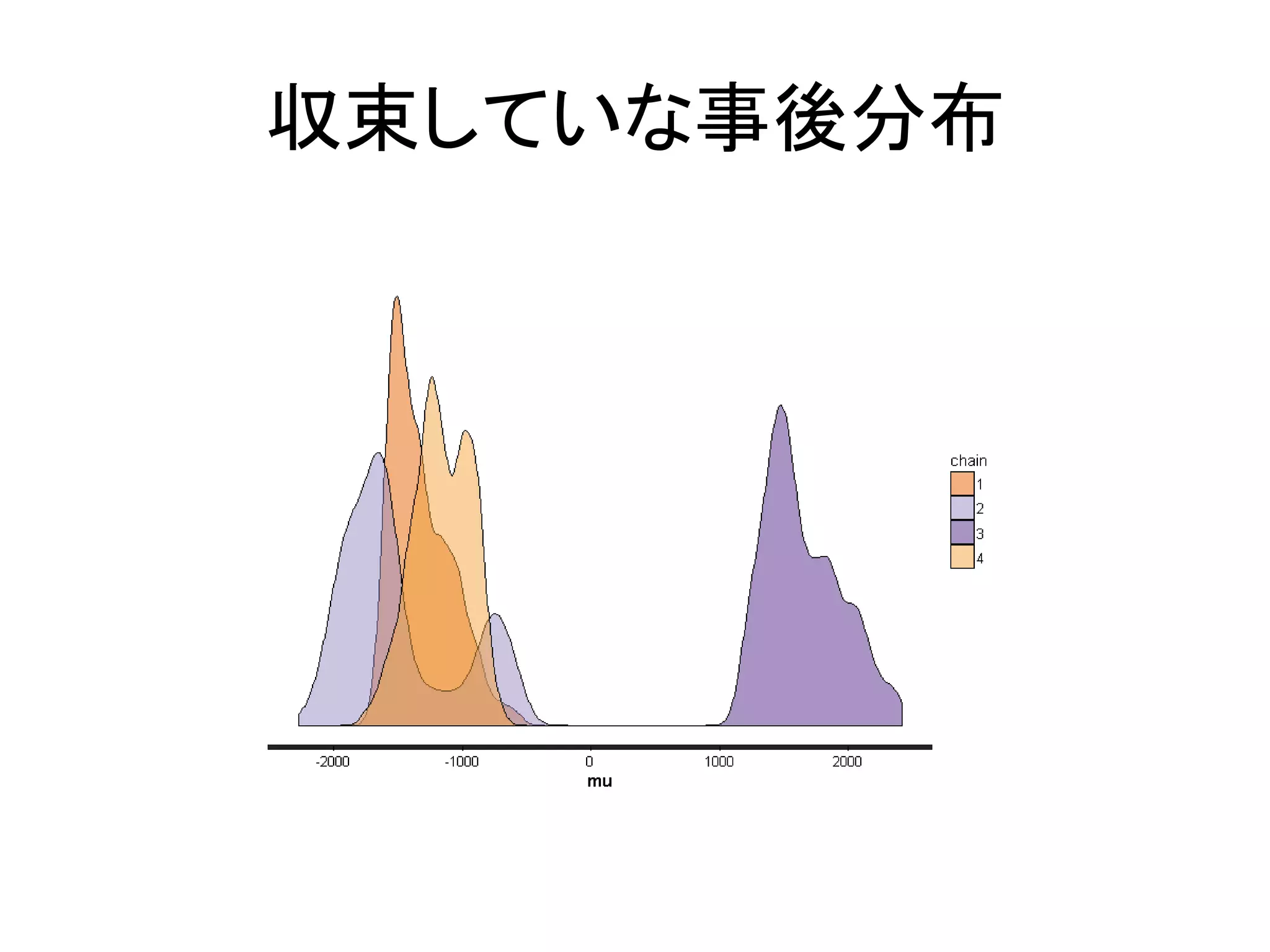
14
/ 131
15
/ 131
16
/ 131
17
/ 131
Most read
18
/ 131
19
/ 131
20
/ 131
21
/ 131
22
/ 131
23
/ 131
24
/ 131
25
/ 131
26
/ 131
27
/ 131
28
/ 131
29
/ 131
30
/ 131
31
/ 131
32
/ 131
33
/ 131
34
/ 131
35
/ 131
36
/ 131
37
/ 131
38
/ 131
39
/ 131
40
/ 131
41
/ 131
42
/ 131
43
/ 131
44
/ 131
45
/ 131
46
/ 131
47
/ 131
48
/ 131
49
/ 131
50
/ 131
51
/ 131
52
/ 131
53
/ 131
54
/ 131
55
/ 131
56
/ 131
57
/ 131
58
/ 131
59
/ 131
60
/ 131
61
/ 131
62
/ 131
63
/ 131
64
/ 131
65
/ 131
66
/ 131
67
/ 131
68
/ 131
69
/ 131
70
/ 131
71
/ 131
72
/ 131
73
/ 131
74
/ 131
75
/ 131
76
/ 131
77
/ 131
78
/ 131
79
/ 131
80
/ 131
81
/ 131
82
/ 131
83
/ 131
84
/ 131
85
/ 131
86
/ 131
87
/ 131
88
/ 131
89
/ 131
90
/ 131
91
/ 131
92
/ 131
93
/ 131
94
/ 131
95
/ 131
96
/ 131
97
/ 131
98
/ 131
99
/ 131
100
/ 131
101
/ 131
102
/ 131
103
/ 131
104
/ 131
105
/ 131
Most read
106
/ 131
107
/ 131
108
/ 131
109
/ 131
110
/ 131
111
/ 131
112
/ 131
113
/ 131
114
/ 131
115
/ 131
116
/ 131
117
/ 131
118
/ 131
119
/ 131
Most read
120
/ 131
121
/ 131
122
/ 131
123
/ 131
124
/ 131
125
/ 131
126
/ 131
127
/ 131
128
/ 131
129
/ 131
130
/ 131
131
/ 131
More Related Content
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
PPTX
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
Stan超初心者入門
by
Hiroshi Shimizu
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
階層ベイズとWAIC
by
Hiroshi Shimizu
Stanコードの書き方 中級編
by
Hiroshi Shimizu
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
階層モデルの分散パラメータの事前分布について
by
hoxo_m
What's hot
PDF
Stanの便利な事後処理関数
by
daiki hojo
PPTX
ベイズファクターとモデル選択
by
kazutantan
PDF
ベイズモデリングと仲良くするために
by
Shushi Namba
PDF
2 3.GLMの基礎
by
logics-of-blue
PDF
これからの仮説検証・モデル評価
by
daiki hojo
PDF
正準相関分析
by
Akisato Kimura
PDF
RStanとShinyStanによるベイズ統計モデリング入門
by
Masaki Tsuda
PDF
2 4.devianceと尤度比検定
by
logics-of-blue
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
MCMCサンプルの使い方 ~見る・決める・探す・発生させる~
by
. .
PPTX
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
PDF
一般化線形混合モデル入門の入門
by
Yu Tamura
PDF
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
PDF
StanとRでベイズ統計モデリング 11章 離散値をとるパラメータ
by
Miki Katsuragi
PPTX
心理学における「再現性」の問題とBayes Factor
by
Shushi Namba
PPTX
5分でわかるベイズ確率
by
hoxo_m
PDF
Stanでガウス過程
by
Hiroshi Shimizu
PDF
PRML輪読#2
by
matsuolab
PPTX
StanとRでベイズ統計モデリング読書会Ch.9
by
考司 小杉
Stanの便利な事後処理関数
by
daiki hojo
ベイズファクターとモデル選択
by
kazutantan
ベイズモデリングと仲良くするために
by
Shushi Namba
2 3.GLMの基礎
by
logics-of-blue
これからの仮説検証・モデル評価
by
daiki hojo
正準相関分析
by
Akisato Kimura
RStanとShinyStanによるベイズ統計モデリング入門
by
Masaki Tsuda
2 4.devianceと尤度比検定
by
logics-of-blue
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
MCMCサンプルの使い方 ~見る・決める・探す・発生させる~
by
. .
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
一般化線形混合モデル入門の入門
by
Yu Tamura
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
StanとRでベイズ統計モデリング 11章 離散値をとるパラメータ
by
Miki Katsuragi
心理学における「再現性」の問題とBayes Factor
by
Shushi Namba
5分でわかるベイズ確率
by
hoxo_m
Stanでガウス過程
by
Hiroshi Shimizu
PRML輪読#2
by
matsuolab
StanとRでベイズ統計モデリング読書会Ch.9
by
考司 小杉
Viewers also liked
PDF
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
PPTX
ベイズ統計モデリングと心理学
by
Shushi Namba
PDF
データ解析のための統計モデリング入門10章前半
by
Shinya Akiba
PDF
2012-1110「マルチレベルモデルのはなし」(censored)
by
Mizumoto Atsushi
PDF
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
by
Takashi J OZAKI
PDF
rstanで個人のパラメーターを推定した話
by
Yuya Matsumura
PDF
Stan勉強会資料(前編)
by
daiki hojo
PDF
階層ベイズモデルで割安mobile PCを探す
by
. .
PDF
とある病んだ院生の体内時計(サーカディアンリズム)
by
. .
PDF
Stanでpsychophysics──階層ベイズモデルで恒常法データを分析する──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
PPTX
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
PPTX
NagoyaStat #5 データ解析のための 統計モデリング入門 第10章
by
nishioka1
PDF
Osaka.Stan #3 Chapter 5-2
by
Takayuki Goto
PDF
Rで階層ベイズモデル
by
Yohei Sato
PDF
StanとRで折れ線回帰──空間的視点取得課題の反応時間データを説明する階層ベイズモデルを例に──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
PPTX
【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル
by
Masashi Komori
PDF
データ解析のための統計モデリング入門 1~2章
by
itoyan110
PPTX
Osaka.stan#2 chap5-1
by
Makoto Hirakawa
PDF
R stan導入公開版
by
考司 小杉
PDF
K meansによるクラスタリングの解説と具体的なクラスタリングの活用方法の紹介
by
Takeshi Mikami
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
ベイズ統計モデリングと心理学
by
Shushi Namba
データ解析のための統計モデリング入門10章前半
by
Shinya Akiba
2012-1110「マルチレベルモデルのはなし」(censored)
by
Mizumoto Atsushi
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
by
Takashi J OZAKI
rstanで個人のパラメーターを推定した話
by
Yuya Matsumura
Stan勉強会資料(前編)
by
daiki hojo
階層ベイズモデルで割安mobile PCを探す
by
. .
とある病んだ院生の体内時計(サーカディアンリズム)
by
. .
Stanでpsychophysics──階層ベイズモデルで恒常法データを分析する──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
NagoyaStat #5 データ解析のための 統計モデリング入門 第10章
by
nishioka1
Osaka.Stan #3 Chapter 5-2
by
Takayuki Goto
Rで階層ベイズモデル
by
Yohei Sato
StanとRで折れ線回帰──空間的視点取得課題の反応時間データを説明する階層ベイズモデルを例に──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル
by
Masashi Komori
データ解析のための統計モデリング入門 1~2章
by
itoyan110
Osaka.stan#2 chap5-1
by
Makoto Hirakawa
R stan導入公開版
by
考司 小杉
K meansによるクラスタリングの解説と具体的なクラスタリングの活用方法の紹介
by
Takeshi Mikami
Similar to StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
PPTX
StanとRでベイズ統計モデリング 1,2章
by
Miki Katsuragi
PDF
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会
by
Shushi Namba
PDF
ベイズ統計入門
by
Miyoshi Yuya
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PDF
統計学における相関分析と仮説検定の基本的な考え方とその実践
by
id774
PDF
PRML_titech 8.1 - 8.2
by
Takafumi Sakakibara
PDF
統計学のための数学
by
Gen Fujita
PDF
【社内勉強会用】統計学超入門
by
Akira Torii
PDF
Introduction to statistics
by
Kohta Ishikawa
PDF
20191117_choco_bayes_pub
by
Yoichi Tokita
PDF
Infer net wk77_110613-1523
by
Wataru Kishimoto
PDF
Draftall
by
Toshiyuki Shimono
PDF
SappoRo.R #2 初心者向けWS資料
by
考司 小杉
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PDF
Oshasta em
by
Naotaka Yamada
PDF
PRML輪講用資料10章(パターン認識と機械学習,近似推論法)
by
Toshiyuki Shimono
PDF
確率・統計の基礎勉強会 (1)
by
Hiroaki Tanaka
PPTX
Rプログラミング01 はじめの一歩
by
wada, kazumi
PDF
Probabilistic Graphical Models 輪読会 #1
by
Takuma Yagi
StanとRでベイズ統計モデリング 1,2章
by
Miki Katsuragi
Rでベイズをやってみよう!(コワい本1章)@BCM勉強会
by
Shushi Namba
ベイズ統計入門
by
Miyoshi Yuya
ベイズ統計学の概論的紹介
by
Naoki Hayashi
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
統計学における相関分析と仮説検定の基本的な考え方とその実践
by
id774
PRML_titech 8.1 - 8.2
by
Takafumi Sakakibara
統計学のための数学
by
Gen Fujita
【社内勉強会用】統計学超入門
by
Akira Torii
Introduction to statistics
by
Kohta Ishikawa
20191117_choco_bayes_pub
by
Yoichi Tokita
Infer net wk77_110613-1523
by
Wataru Kishimoto
Draftall
by
Toshiyuki Shimono
SappoRo.R #2 初心者向けWS資料
by
考司 小杉
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
Oshasta em
by
Naotaka Yamada
PRML輪講用資料10章(パターン認識と機械学習,近似推論法)
by
Toshiyuki Shimono
確率・統計の基礎勉強会 (1)
by
Hiroaki Tanaka
Rプログラミング01 はじめの一歩
by
wada, kazumi
Probabilistic Graphical Models 輪読会 #1
by
Takuma Yagi
More from Hiroshi Shimizu
PDF
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
PDF
SapporoR#6 初心者セッションスライド
by
Hiroshi Shimizu
PDF
Tokyo r53
by
Hiroshi Shimizu
PDF
glmmstanパッケージを作ってみた
by
Hiroshi Shimizu
PDF
媒介分析について
by
Hiroshi Shimizu
PDF
負の二項分布について
by
Hiroshi Shimizu
PPTX
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
PDF
社会心理学とGlmm
by
Hiroshi Shimizu
PDF
Rで潜在ランク分析
by
Hiroshi Shimizu
PDF
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
PPTX
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
PPTX
Latent rank theory
by
Hiroshi Shimizu
PDF
エクセルでテキストマイニング TTM2HADの使い方
by
Hiroshi Shimizu
PPTX
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
PPTX
Excelでも統計分析 HADについて SappoRo.R#3
by
Hiroshi Shimizu
PDF
エクセルで統計分析2 HADの使い方
by
Hiroshi Shimizu
PDF
エクセルで統計分析4 因子分析のやり方
by
Hiroshi Shimizu
PDF
エクセルで統計分析3 回帰分析のやり方
by
Hiroshi Shimizu
PDF
Mplusの使い方 中級編
by
Hiroshi Shimizu
PDF
Mplusの使い方 初級編
by
Hiroshi Shimizu
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
SapporoR#6 初心者セッションスライド
by
Hiroshi Shimizu
Tokyo r53
by
Hiroshi Shimizu
glmmstanパッケージを作ってみた
by
Hiroshi Shimizu
媒介分析について
by
Hiroshi Shimizu
負の二項分布について
by
Hiroshi Shimizu
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
社会心理学とGlmm
by
Hiroshi Shimizu
Rで潜在ランク分析
by
Hiroshi Shimizu
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
Latent rank theory
by
Hiroshi Shimizu
エクセルでテキストマイニング TTM2HADの使い方
by
Hiroshi Shimizu
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
Excelでも統計分析 HADについて SappoRo.R#3
by
Hiroshi Shimizu
エクセルで統計分析2 HADの使い方
by
Hiroshi Shimizu
エクセルで統計分析4 因子分析のやり方
by
Hiroshi Shimizu
エクセルで統計分析3 回帰分析のやり方
by
Hiroshi Shimizu
Mplusの使い方 中級編
by
Hiroshi Shimizu
Mplusの使い方 初級編
by
Hiroshi Shimizu
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
1.
StanとRでベイズ統計モデリング 読書会 導入編(1章~3章) 清水裕士 関西学院大学社会学部
2.
自己紹介 • 清水裕士 – 関西学院大学社会学部 –
社会心理学研究センター研究員 • 専門 – 社会心理学 • 趣味 – Stan • Web – Twitter:@simizu706 – ブログ: http://norimune.net
3.
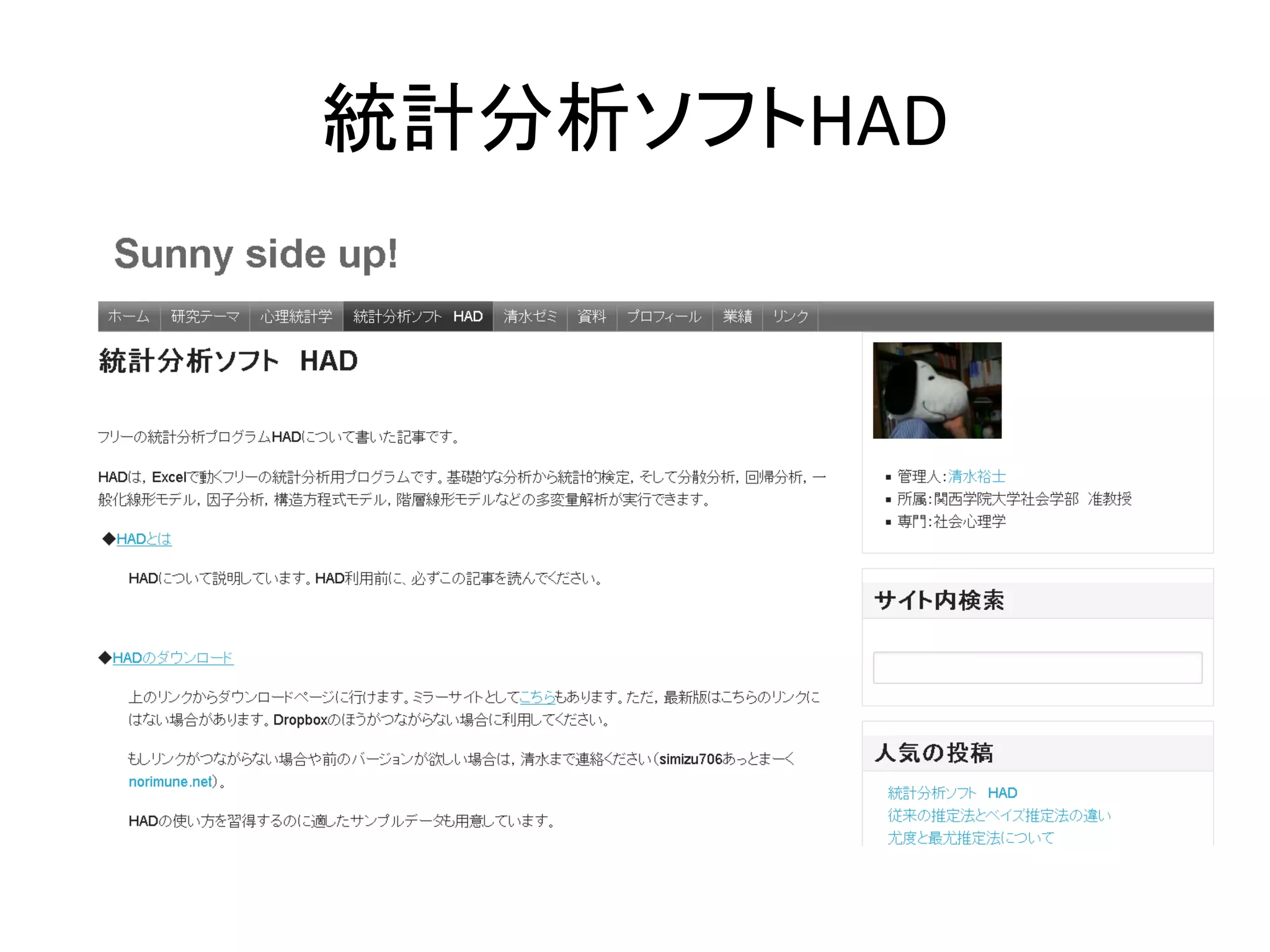
統計分析ソフトHAD
4.
Stan初心者講習の資料 • http://www.slideshare.net/simizu706/stan-62042940
5.
中級編も
6.
この会の目的 • 『StanとRでベイズ統計モデリング』 – 松浦健太郎著
7.
この本の特徴 • Stan神@berobero11さんの本 – おそらく日本で(世界でも)トップレベルでStanに詳しく、 かつ、情報発信をしている人 •
rstanのサイトやマニュアルの日本語翻訳チームをまとめて いる – 統計モデリングや機械学習、伝統的な統計モデルな ど幅広い知識がある • 敷居がとても低い – 簡単なモデルを丁寧に解説 – 数式があまり出てこない
8.
ねらい • ベイズ統計モデリングに興味がある人 – Stanを触ったことない人 –
文系で数式もよく分からない人 – Stanによるモデリングに親しんでもらうことを目的 • Stanの布教 – みんなでMCMC(*´Д`)ハァハァしましょう
9.
読書会の方針 • 月に1回ペースぐらい • 担当者が1章を熟読して発表 –
Stanコードがあれば、それも実行しつつ難しそうなポ イントを紹介 • 全員は当該の章を読んでくる – 発表のあと、質疑応答、議論など • 清水がわかる範囲で解説する
10.
今日の発表 • 清水が担当 • 導入編(1章~3章)について解説 –
本の内容+清水的解説 – とくに、数式の意味、読み方、そして統計モデリン グのことなどについて話します – 今日はStanもRも使いません
11.
はじめに
12.
何について書かれた本? • Stan、とくにrstanについての解説 – Stanは確率的プログラミング言語のソフト名 –
rstanはStanをRで動かすためのパッケージ名 • StanはPythonとかStataなどほかのソフトでも動く • Stanでできること – いろんな統計モデリング – 回帰分析などはもちろん、階層モデル、状態空間モ デルなど高度なモデルも可能 – ユーザーがそれらをカスタマイズすることも可能
13.
1章 統計モデリングとStanの概要
14.
1.1 統計モデリングとは • モデル –
必要なエッセンスだけを取り上げて,不必要な部分を大 胆に切り落としたもの • プラモデルとか。 • 確率モデル – エッセンスに数式を用いて,確率分布を取り入れたもの • 統計モデリング – 確率モデルをデータに当てはめて現象の理解と予測を促 すこと
15.
確率モデル • 確率分布 – 確率変数が取りうる各々の値に対して,その発生の しやすさを確率で表したもの –
二項分布,正規分布などなど • パラメータ – 確率分布を特徴づける値 • 正規分布なら平均値と分散(あるいは標準偏差) – 解析前には未知で,これを知ることが統計モデリング の1つの目的
16.
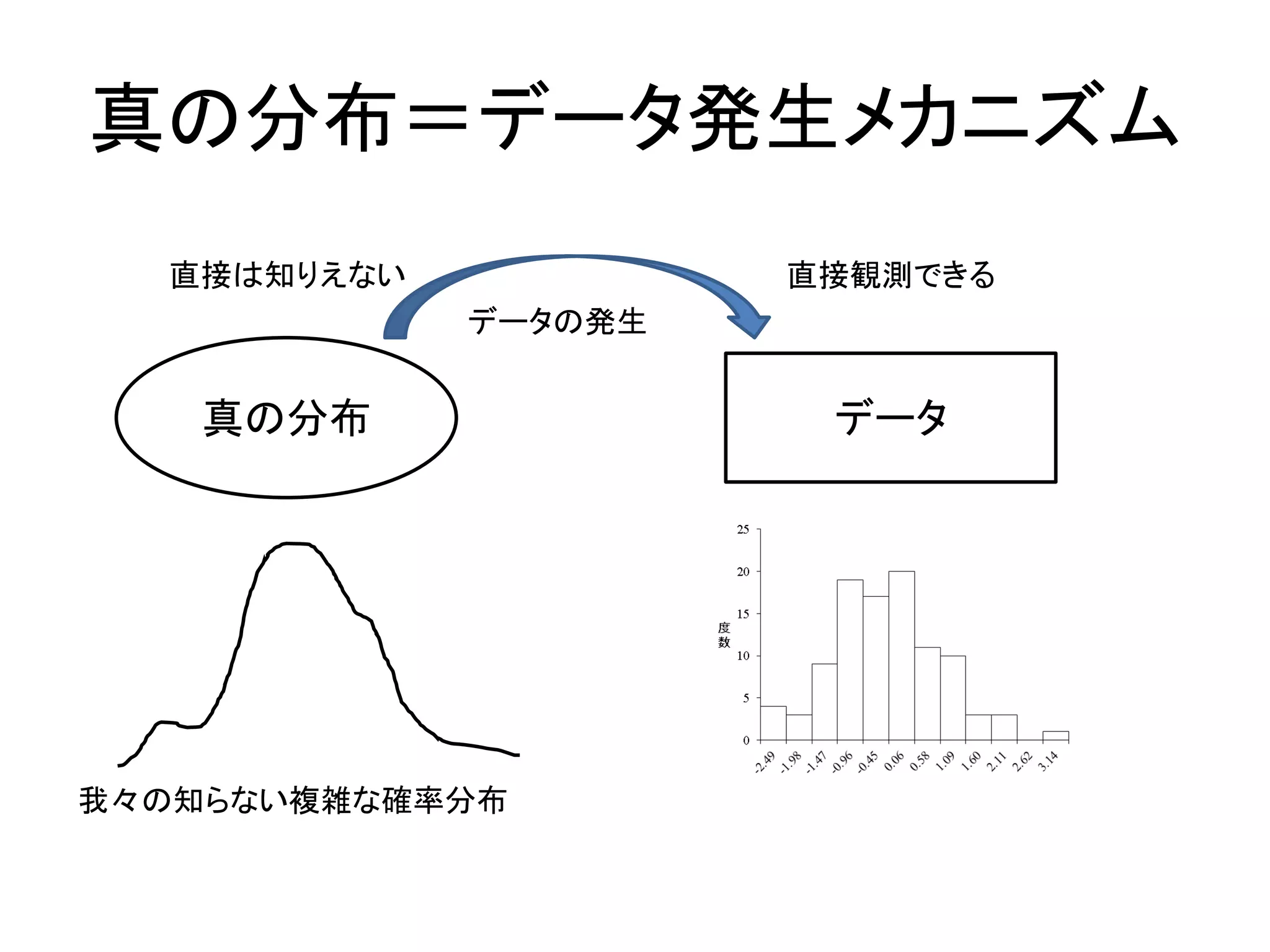
補足:統計モデリングとは • データ発生のメカニズムを知る – データが何らかの分布から発生している –
その発生メカニズムを「確率分布」を使って表現 – データの予測に興味がある • 確率分布のパラメータを推測する – 確率分布の形を決める値のこと • 正規分布なら,平均値と分散 – 正規分布以外の確率分布も扱う
17.
真の分布=データ発生メカニズム 真の分布 データ 直接は知りえない 直接観測できる データの発生 我々の知らない複雑な確率分布
18.
確率モデルを選ぶ • データに合った,よく知っている確率分布 データ 確率モデル 我々の知っている簡単な確率分布 たとえば正規分布を当てはめる パラメータは未知
19.
統計モデリング • パラメータの推測 – 正規分布には平均値と分散,二つのパラメータ –
パラメータが決まれば,確率分布の形が決まる • パラメータの推定原理 – 最小二乗法 – 最尤法 – ベイズ法
20.
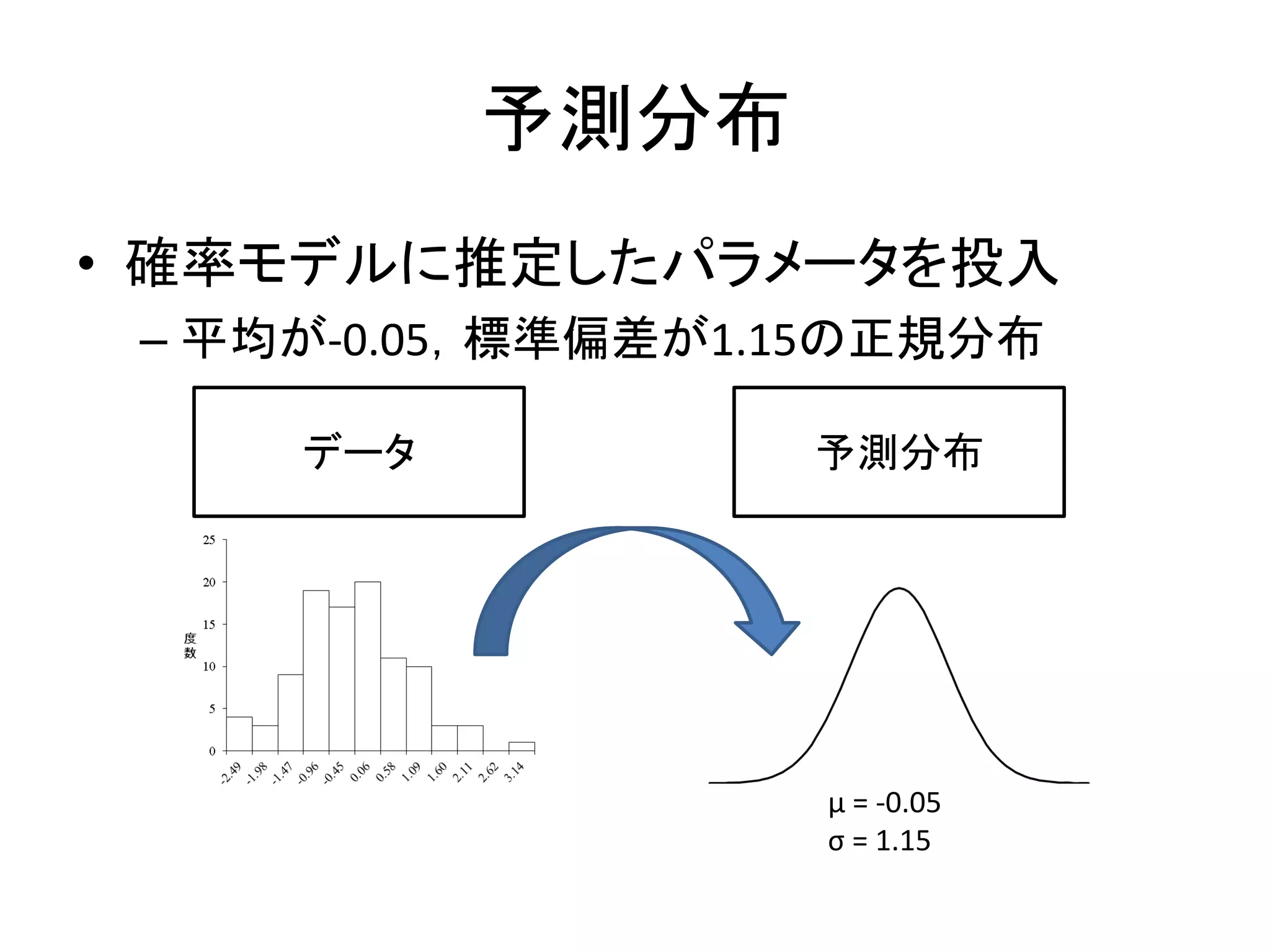
予測分布 • 確率モデルに推定したパラメータを投入 – 平均が-0.05,標準偏差が1.15の正規分布 μ
= -0.05 σ = 1.15 データ 予測分布
21.
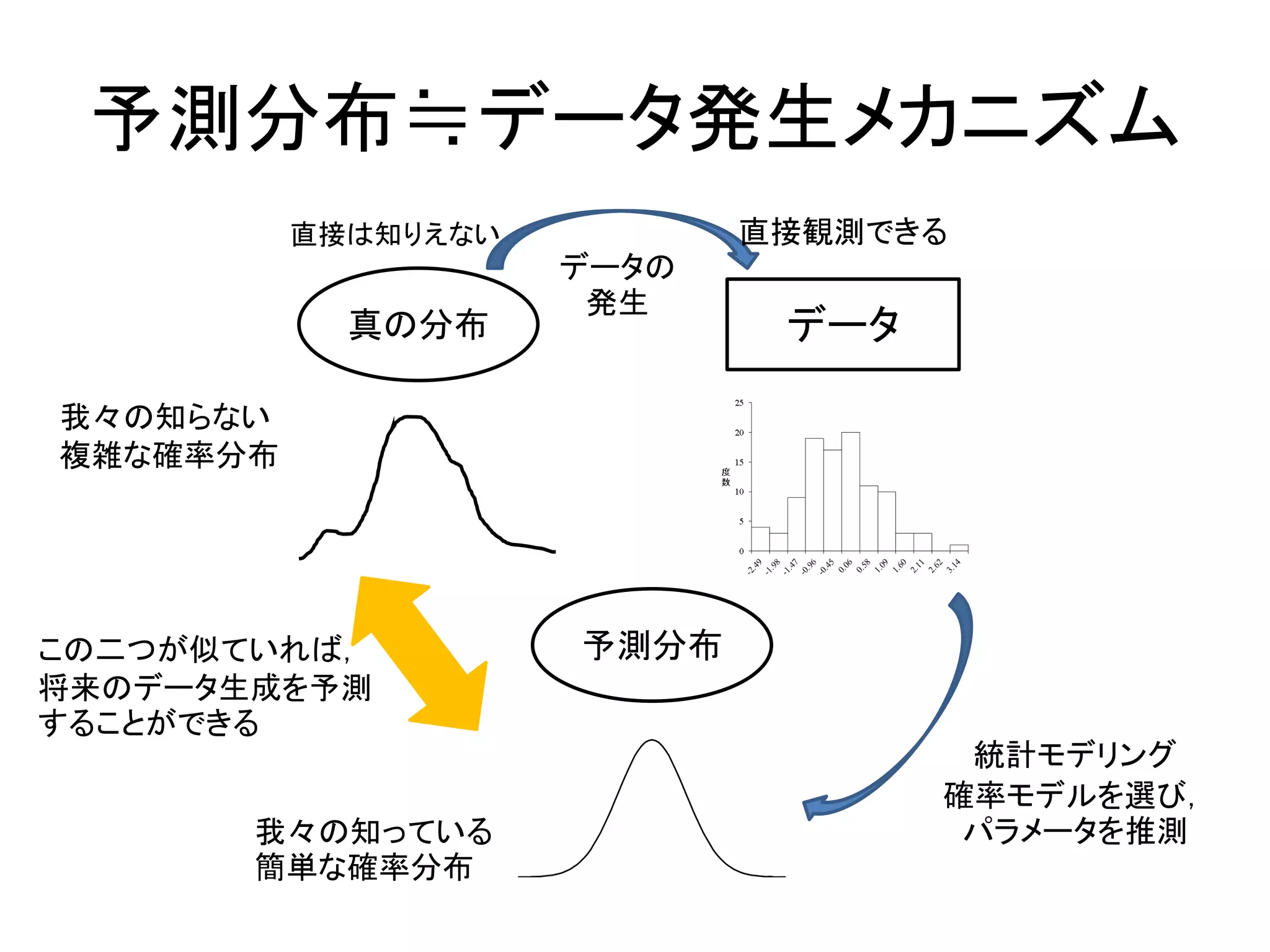
予測分布≒データ発生メカニズム 真の分布 データ 直接は知りえない 直接観測できる データの 発生 予測分布 統計モデリング 確率モデルを選び, パラメータを推測 この二つが似ていれば, 将来のデータ生成を予測 することができる 我々の知らない 複雑な確率分布 我々の知っている 簡単な確率分布
22.
1.2 統計モデリングの目的 • 解釈 –
現象の仕組みを知りたい • データの生成メカニズムを知りたい • 説明しやすい,納得しやすいモデルを作りたい – パラメータの関係式から現象を解釈する • 回帰分析の回帰式なんかがそれにあたる • 予測 – これまで得られたデータから,未来に得られるであろ うデータの振る舞いを知りたい • 予測精度の高いモデルを作りたい
23.
解釈と予測 • 二つは密接に関連している – 背景知識とマッチした納得しやすいモデルは,頑 健性を備えている •
ただし同じものではない – 予測精度だけを上げたいなら,機械学習のような 方法を使えば良い • 中身はブラックボックス(解釈不可能)だが,未来の データは完璧に予測(分類)することができる,とか
24.
解釈と予測から見る手法の違い • 古典的な統計学(分散分析とか) – 解釈重視 •
実験計画にあった解釈が可能 – しかし,強い制約がある • 等分散の仮定,球面性の仮定,正規性の仮定・・・ • 機械学習 – 予測重視 • 次に取るデータの振る舞いを正確に予測・制御可能 – しかし,解釈ができない • ノンパラメトリックな手法 • 将棋ソフトとかは,強くなればなるほど「なぜその手が選ば れたのか」が人間では理解できなくなる
25.
統計モデリング • その二つのバランスをとることが可能 – 予測を重視したい場合は,それに合わせたモデ リングを行う •
パラメータを予測力が上がるように少し複雑に • 過学習が起こらない程度に程よい複雑さを目指す – 解釈を重視したい場合は,わかりやすいモデルを • 実質科学的知見に基づいたモデル構築と変数選択 いいとこどりができるのが統計モデリング!
26.
1.3 確率的プログラミング言語 • これまでの統計モデリング –
モデル構築に,パラメータ推定のためのアルゴリズム 開発がセット • 新しいモデルを作ったら,そのたびに,対数尤度関数の偏 微分をしてそれをプログラミングする – 高度な数学とプログラミング知識が必要 • 確率的プログラミング言語を使うと – 分析者はモデル構築だけをすればいい – パラメータ推定はソフトウェアが勝手にやってくれる
27.
確率的プログラミング言語とは • probabilistic programming
language – 「様々な分布の関数や尤度の計算に特化しかし た関数が豊富に用意されており,確率モデルを データに当てはめることを主な目的としたプログ ラミング言語」 • 確率モデルを書けば勝手に解いてくれる – 確率モデルを書いてデータを入れたら,ほぼ自動 的にパラメータを推定してくれる
28.
確率的プログラミング言語の利点 • モデル開発に専念できる – モデル記述と難しい推定計算を分離 –
分析者は前者だけやって,後者はソフトに任せる • 数学的な素養があまりいらない(清水補足) – 自分で微分とかして解く必要がない • プログラミングの知識もあまりいらない(清水補足) – モデル構築だけをすればよい – アルゴリズムをプログラミング化しなくていいので,バグも 減り,可読性も高い
29.
Rの関数との違いは? • Rにも多様な関数がある – lm(),
glm(),などなど – パッケージも豊富 • それぞれの関数は1つのモデルのみ対応 – 新しいモデルをやるたびにパッケージを探す必要 – 探しても見つからない場合は,そこで行き詰まる • 確率的プログラミング言語があれば! – ちょっとしたモデルの修正は手間がかからない – 最初の「習得コスト」は大きくても,できることは非常に多 いので,総合的には利益が大きい
30.
1.4 なぜStanなのか • WinBUGS –
一番最初に作られた確率的プログラミング言語 – エラーがわかりにくい – 2007年から開発が停滞 • JAGS – BUGSの思想を受け継いだ確率的プログラミング言語 – 一人が開発をしているのであまり更新されず,マニュ アルも整備されていない
31.
Stan • 最新の手法が実装 – ハミルトミアンモンテカルロ法 •
あるいはそれを改良したNUTSと呼ばれる方法 • BUGSやJAGSのアルゴリズムより性能がいい – 100分の1ぐらいの計算回数で収束する – 変分ベイズを行う自動微分変分ベイズ法 • 近似法だが,MCMCよりもずっと早い • 開発が活発 – マニュアルが充実 • モデルの用例も豊富 – エラーメッセージもわかりやすい – 新しい手法の実装や,バグの修正も早い
32.
なぜrstanなのか • rstanとは – StanをR上で動かすためのパッケージ –
StanはR以外にもPythonやStataなど,いろんな統計ソ フトで動かすことができる • Rのメリット – 作図機能が優秀 – データハンドリング機能が充実 – 使える確率分布も豊富でシミュレーションしやすい – 統計モデリングをするのにはいい環境
33.
Stanコードの例 • データから正規分布のパラメータを推定 – パラメータは平均μと標準偏差σ
34.
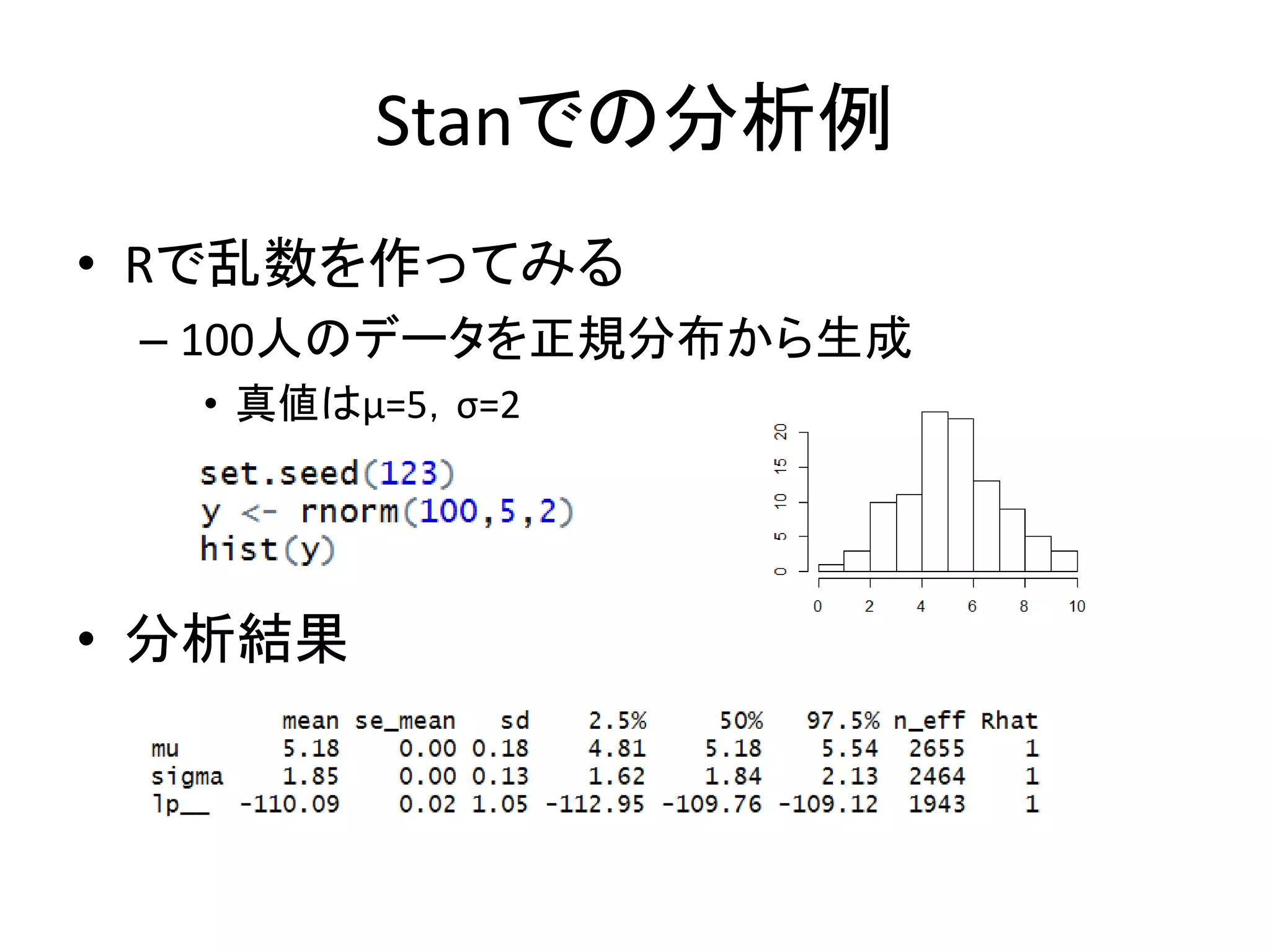
Stanでの分析例 • Rで乱数を作ってみる – 100人のデータを正規分布から生成 •
真値はμ=5,σ=2 • 分析結果
35.
2章 ベイズ推定の復習
36.
2.1 基本用語と記法 • 2章は本書を読む上で重要な情報満載 –
理系の人にとっては基礎的な内容 – しかし,文系にとっては難しい話が多い • 可能な限り具体的に説明します – ただ,本書を読む上で必要ない部分はざっくり 削ってたりします – 参考文献も読みつつ理解していくとよい
37.
確率分布 • 変数の各々の値についての発生しやすさ – 単に分布とも呼ぶ –
二項分布とか正規分布とか – 変数𝑎についての確率は𝑃(𝑎)と表記する • 確率分布の性質 – 総和あるいは積分すると1になる • 例:サイコロで1~6が出る確率は1 • 1にならないものは確率分布とは呼ばない
38.
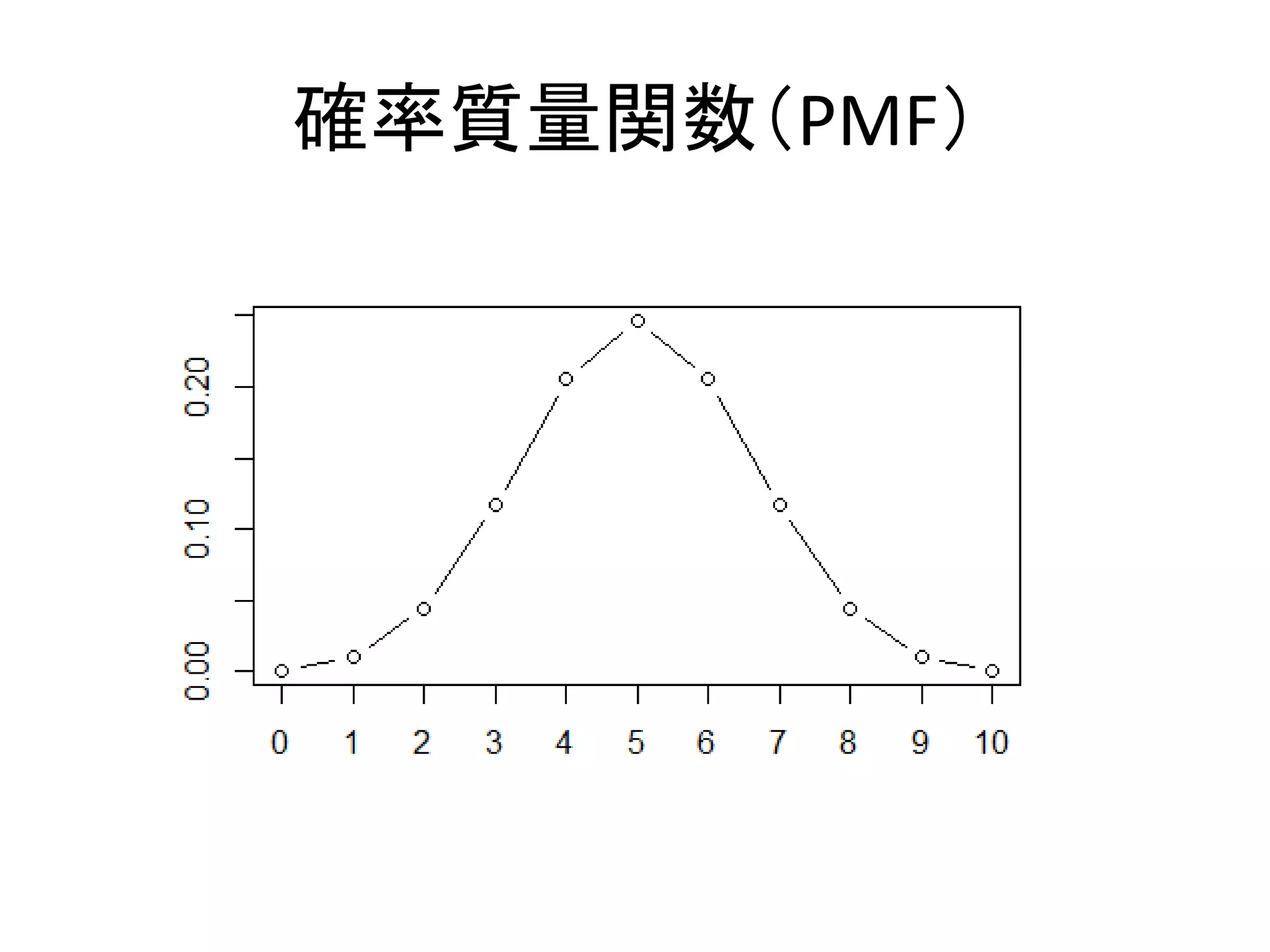
確率質量関数 • 離散的な確率分布の関数 – probability
mass function: PMF – サイコロなど,値がとびとびのもの – 二項分布,ポアソン分布,負の二項分布など • PMFの特徴 – 値と確率が一対一対応する • 1の目がでる確率は1/6 • 成功率0.5,試行数10の二項分布で5回成功する確率は 0.246,など – 総和が1になる
39.
確率質量関数(PMF)
40.
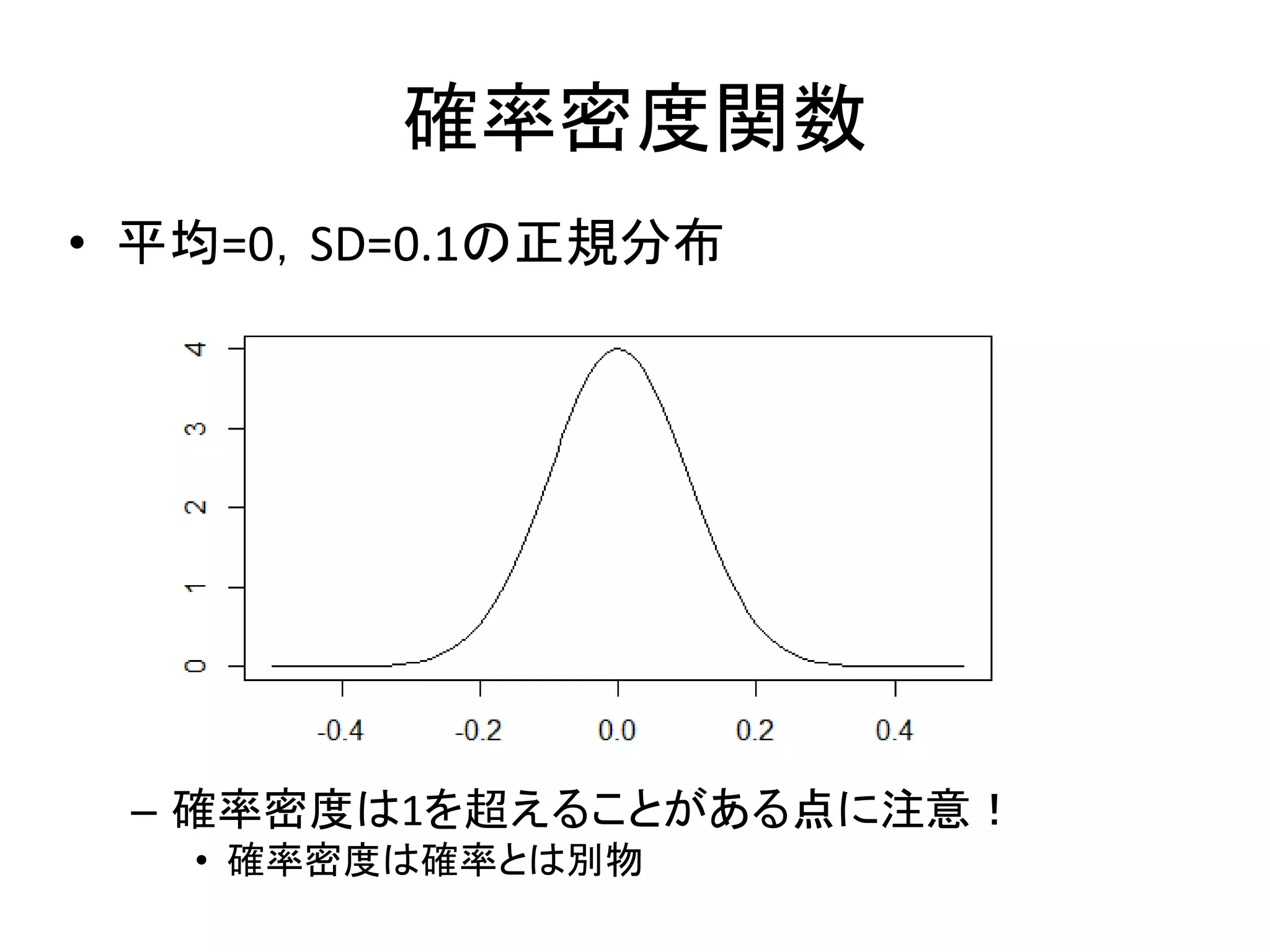
確率密度関数 • 連続的な確率分布の関数 – probability
density function: PDF – 値が連続的で∞までの範囲がある(ない場合も) – 正規分布,ガンマ分布,ベータ分布 • PDFの特徴 – ある一点の値と確率が対応しない • 確率ではなく,確率密度と呼ばれる – 確率は,値の範囲に対応する • (定)積分した値が確率 – 積分したら1になる
41.
確率密度関数 • 平均=0,SD=0.1の正規分布 – 確率密度は1を超えることがある点に注意! •
確率密度は確率とは別物
42.
同時分布 • 複数の変数についての確率分布 – の中で,値の組が同時の生じる確率を表す –
変数𝑎, 𝑏の二つの場合,𝑃 𝑎, 𝑏 と書く • 周辺化 – 同時分布のうち,特定の変数について総和ある いは積分した分布 – 𝑝(𝑎, 𝑏)で𝑎について総和・積分をすると,𝑎が変数 でなくなるので消える → 𝑝(𝑏)になる
43.
例 • 性別と回答,二つの変数のクロス表 • 同時分布 –
総和は1になる 男性 女性 合計 はい 8 4 12 いいえ 2 6 8 合計 10 10 20 男性 女性 はい 0.4 0.2 いいえ 0.1 0.3
44.
同時分布と周辺化 • 周辺化 – 性別について総和をとると・・・ –
はいの確率は0.4 + 0.2=0.6 – いいえの確率は0.1 + 0.3 = 0.4 男性 女性 はい 0.4 0.2 いいえ 0.1 0.3 はい 0.6 いいえ 0.4 周辺分布
45.
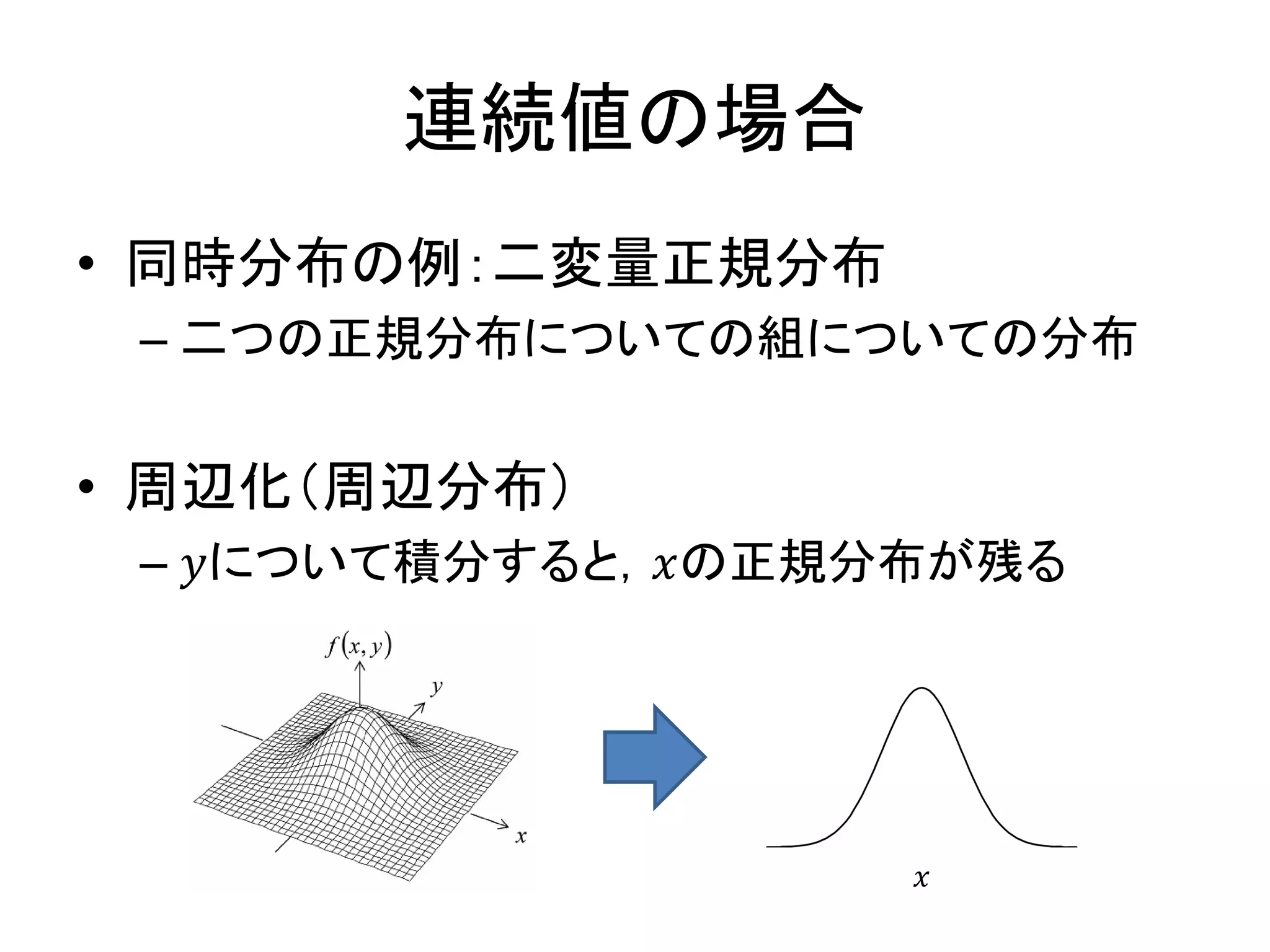
連続値の場合 • 同時分布の例:二変量正規分布 – 二つの正規分布についての組についての分布 •
周辺化(周辺分布) – 𝑦について積分すると,𝑥の正規分布が残る 𝑥
46.
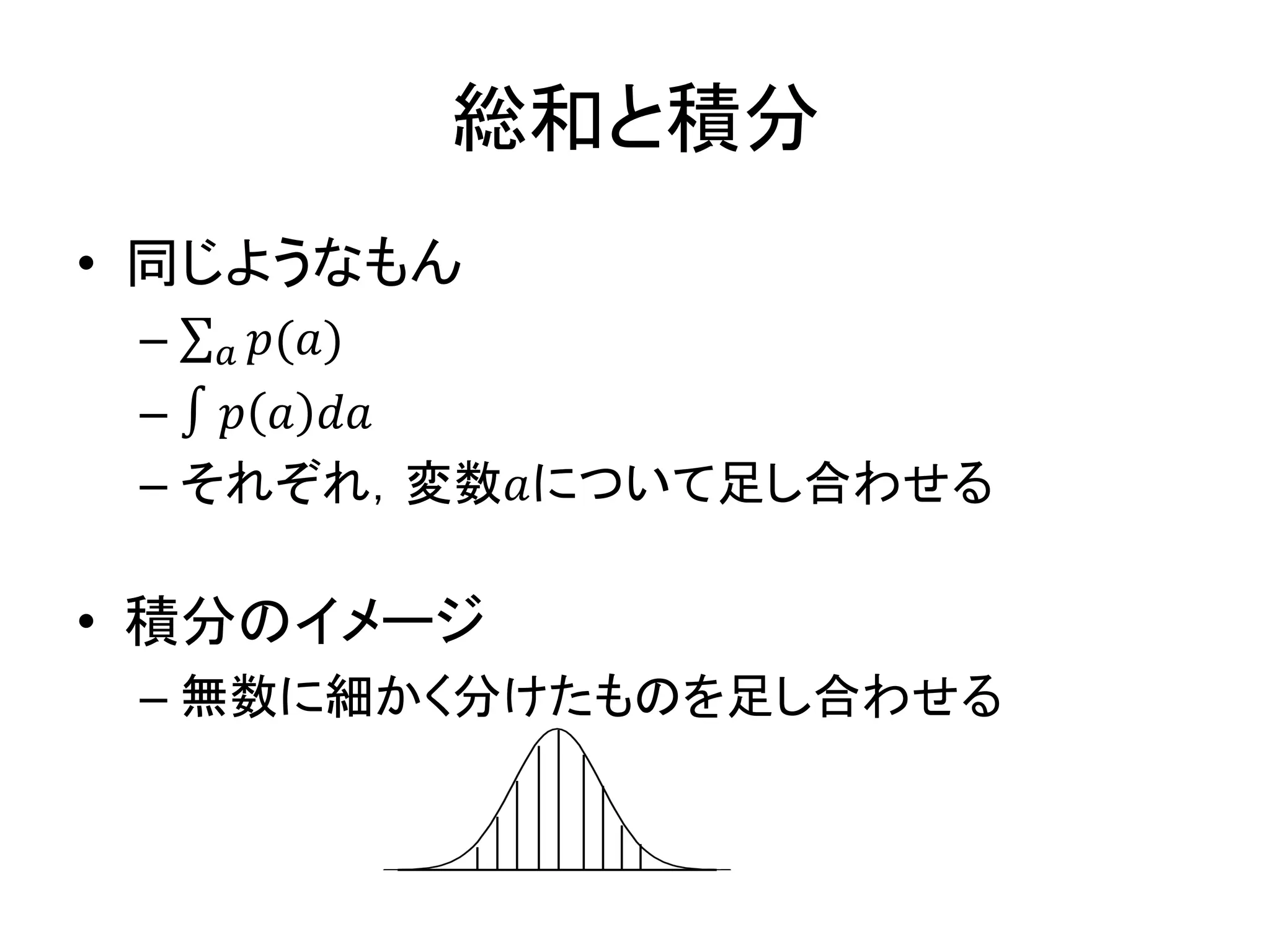
総和と積分 • 同じようなもん – 𝑝(𝑎)𝑎 –
∫ 𝑝 𝑎 𝑑𝑎 – それぞれ,変数𝑎について足し合わせる • 積分のイメージ – 無数に細かく分けたものを足し合わせる
47.
条件付き確率 • ある変数が特定の値のときの別の変数が発 生する確率を表したもの – 𝑝(𝑎|𝑏) –
変数𝑏が与えられたときの変数𝑎の条件付き確率 • 同時確率においてbが特定の値を取る場合 の確率 – 𝑝 𝑎 𝑏 = 0 = 𝑝 𝑎,𝑏=0 𝑝 𝑏=0
48.
条件付き確率分布 • 性別=男性のときの条件付き確率分布 – 男性場合だけなので,8/10と2/10が条件付き確率に なる •
同時分布との関係 – 男性の確率𝑝(男性)は0.5なので, – 𝑝(はい|男性) = 0.4/0.5=0.8と計算することもできる 男性 はい 0.8 いいえ 0.2 男性 女性 合計 はい 8 4 12 いいえ 2 6 8 合計 10 10 20
49.
確率モデルと条件付き確率分布 • データ𝑦が二項分布から生成する確率 – 𝐵𝑖𝑛𝑜𝑚𝑖𝑎𝑙(𝑦)と書く •
パラメータを入れるときは条件付き確率 – データ𝑦が成功率𝜃,試行数Nの二項分布から生 成される確率 – 𝐵𝑖𝑛𝑜𝑚𝑖𝑎𝑙(𝑦 | 𝜃, 𝑁) – 統計モデリングではよく出てくる表現方法
50.
𝑦 ~ 𝑝(𝑦) •
確率変数𝑦が確率分布𝑃(𝑦)に従う – ~(チルダ)は確率的な関係性を表す • データ𝑦が正規分布に従う場合 – 平均𝜇,SD=𝜎の正規分布 – 𝑦 ~ 𝑁𝑜𝑟𝑚𝑎𝑙 𝑦 𝜇, 𝜎) – 単に,𝑦 ~ 𝑁𝑜𝑟𝑚𝑎𝑙(𝜇, 𝜎)と書くこともある
51.
正規化 • 関数の総和や積分が1になるようにすること – 確率分布の定義を満たすようにすること •
正規化定数 – 正規化するために,ある関数に定数をかけたり 割ったりする – その値を正規化定数という – これを知っているとベイズの定理が理解しやすく なるが,わからなくても本書の大半は理解できる
52.
偏微分 • 特定の変数についてのみ微分すること – 2変数𝑎,
𝑏の関数がある場合,𝑎を定数とみなして bのみで微分するような場合,偏微分という • 尤度関数を最適化するときに使う – 尤度については後述 – 本書の大半の理解には必須ではない
53.
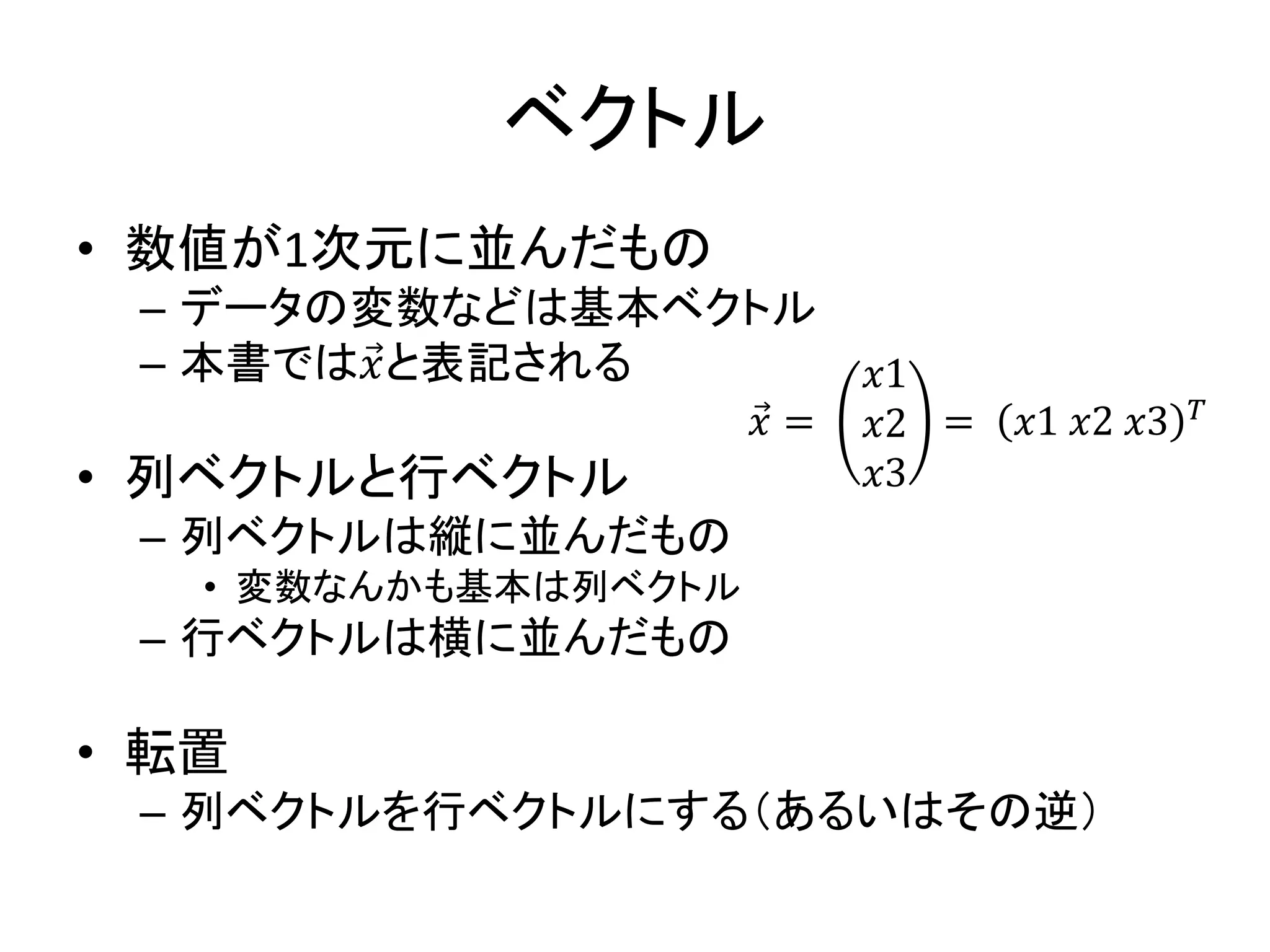
ベクトル • 数値が1次元に並んだもの – データの変数などは基本ベクトル –
本書では𝑥と表記される • 列ベクトルと行ベクトル – 列ベクトルは縦に並んだもの • 変数なんかも基本は列ベクトル – 行ベクトルは横に並んだもの • 転置 – 列ベクトルを行ベクトルにする(あるいはその逆) 𝑥 = 𝑥1 𝑥2 𝑥3 = 𝑥1 𝑥2 𝑥3 𝑇
54.
行列 • 数値が多次元に並んだもの – ベクトルが集まったものも行列 –
データセットなんかも行列 – 本書では𝒙と太文字で表記される 𝒙 = 𝑥11, 𝑥12, 𝑥13 𝑥21, 𝑥22, 𝑥23 𝑥31, 𝑥32, 𝑥33
55.
本書の記法 • データを表す場合 – 最初を大文字にする –
統計モデリングでは,観測されたものは大文字で表 記されることが多い • 添字には二種類の意味 – パラメータの場合と,ベクトルの場合 – 𝜎 𝑌は変数Yの標準偏差であることを意味する – 𝜃 𝑘はベクトル𝜃のk番目の要素であることを意味する
56.
ベクトルの要素の表記 • 添字のバージョン – 𝑌𝑛 –
データ𝑌の𝑛番目の値 – 数学ではこっちを使う • 大カッコバージョン – 𝑌[𝑛] – データ𝑌の𝑛番目の値 – Stanの場合はこっちのほうがわかりやすいかも
57.
2.2 伝統的な統計学の問題点 • ベイズ統計学と伝統的な統計学 –
おそらく本書では頻度主義統計学のことを「伝統 的な統計学」と呼んでいる・・・と思う – その二つの違いは,結局はパラメータを定数と考 えるか確率変数と考えるかの違い • 本書に合わせて「ベイズ」と「伝統」と表記 – 頻度と書くとたぶんいろいろややこしいことが・・・ あるのかないのか
58.
パラメータの扱い • パラメータ – 確率分布を特徴づける値 •
正規分布なら平均値と分散(あるいは標準偏差) – 解析前には未知で,これを知ることが統計モデリングの1 つの目的 • パラメータをどう考えるか – 伝統:真の値があって,それは定数であると考える • 平均値は170だ!とか – ベイズ:確率的に変動するものと考える • 平均値は170が最も確率が高そうだが,165である確率もそれなり にはあるな・・・
59.
伝統的な考え方の問題 • パラメータを定数と考える – 確率的に変動するのはデータだけになる –
確率の解釈をデータの変動を中心にする必要 • 検定のロジック – 𝑝値は,帰無仮説が正しいという仮定のものとで, データ以上に極端な結果が得られる確率 – パラメータについては確率的なことは何も言えな いのでこんな周りくどい言い方になる
60.
伝統的な考え方の問題 • 信頼区間の考え方 – パラメータは定数なので,95%信頼区間も「この 範囲にパラメータが含まれる確率が95%」という 言い方ができない –
仮にデータをたくさんとったとき,この方法で設定 した範囲にパラメータが含まれることが95%あると いう面倒な言い方になる
61.
伝統的な考え方の問題 • 予測区間 – 将来のデータが散らばると予想される範囲のこと –
予測分布の95%の範囲だと考えればOK • 「伝統」だと予測区間の定義が難しい – そもそも「伝統」では将来のデータを,現在のデータ で推論したモデルで予測するという考え方に合ってい ない – 結果が再現されるかどうかについても「伝統」からは 主張が難しい
62.
「ベイズ」的な考え方 • パラメータを確率変数と考える – データが有限である以上,パラメータの推論は確率 的な幅があって然り –
その幅も含めて推論できるのがベイズの長所 • 検定のロジック – 帰無仮説を設定せずとも,パラメータについての仮説 が正しい確率が直接わかる – たとえば差が0以上の確率は,差のパラメータの分布 を0以上で積分すればOK
63.
2.3 尤度と最尤推定 • 最尤推定 –
「伝統」で使われる推定方法 – 尤度を最大にするパラメータを求める方法 • 尤度って何 – データと(ある分布の)パラメータの当てはまり具 合を表す量 – 尤度が高いほうが,データに合ったパラメータに なっている,ということ
64.
確率モデルと尤度関数 • 確率モデル – データ𝑦がSD=1の正規分布に従うとする •
ここでは説明しやすいようにSDは固定しておく – 𝑦 ~ 𝑁𝑜𝑟𝑚𝑎𝑙(𝜇, 𝜎 = 1) • 𝜇は未知数 𝜇を知りたい • 正規分布の式 – 𝑁𝑜𝑟𝑚𝑎𝑙 𝑦|𝜇, 𝜎 = 1 2 𝜋 𝜎2 exp − 𝑦−𝜇 2 2𝜎2 – 𝜎 = 1の場合, 1 2 𝜋 exp − 𝑦−𝜇 2 2
65.
確率モデルと尤度関数 • 1人のデータ𝑌をとったとする – 𝑁𝑜𝑟𝑚𝑎𝑙
𝑌 𝜇 = 1 2 𝜋 exp − 𝑌−𝜇 2 2 • この場合,𝑌はすでにわかっている値なので定数 • わからないのはパラメータ𝜇 • 尤度関数 – 確率モデルについて,データを定数,パラメータを変 数とした関数を尤度関数と呼ぶ – 確率分布と違うのは,積分しても1にならない – 特定のデータが得られたときのパラメータの尤もらし さ
66.
尤度関数のプロット • Y[1]が3の場合 – 𝑁𝑜𝑟𝑚𝑎𝑙
𝑌 = 3 𝜇 = 1 2 𝜋 exp − 3−𝜇 2 2 – 𝜇は3が一番尤もらしい
67.
尤度関数のプロット • Yが(1,2,3,4,5)の場合 5人のデータ –
𝑁𝑜𝑟𝑚𝑎𝑙 𝑌 𝜇 = 1 2 𝜋 exp − 𝑌[𝑛]−𝜇 2 2 5 𝑛=1 – 1人より5人のほうが尤度の分散は小さい Πは繰り返し「かける」 ことを意味する Σは繰り返す「たす」の を思い出そう
68.
尤度は小さい値になりやすい • データが100人だと100人分かけあわせる – 確率密度はたいていは1より小さいので,100人分かけあ わせると,とても小さい値になる –
そこで,対数尤度を使うことが多い • 対数 – log2 8 = 3 • 8が2の何乗かを計算するもの – 対数をとると,積が和になり,また0~1の値は負でそれな りに絶対値が大きくなるので計算もしやすい • 8 × 8 = 64 • log2(23 × 23) = log2(23+3) = 3 + 3 = 6 = log2(64) – 統計モデリングでは自然対数を使う
69.
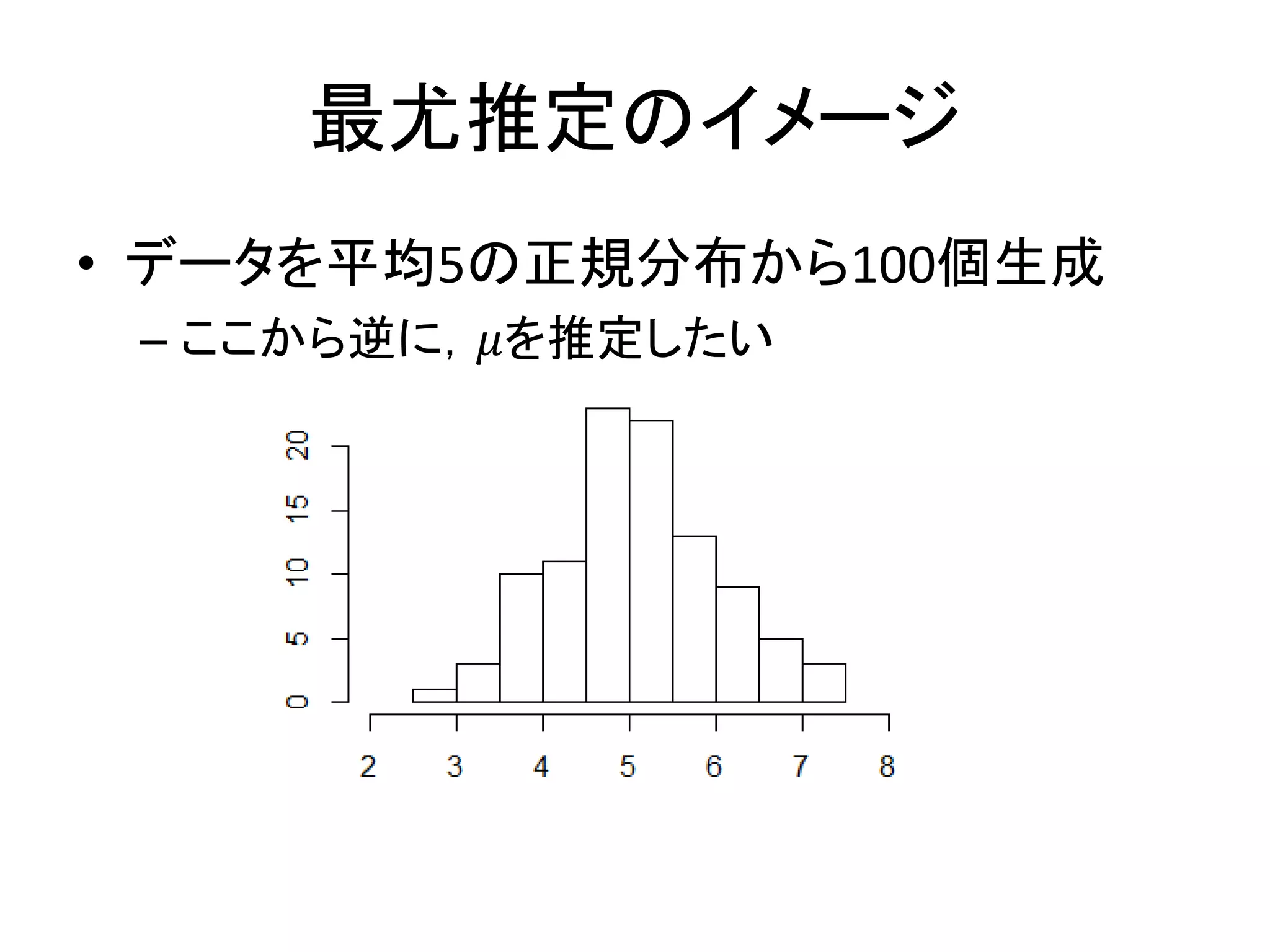
最尤推定のイメージ • データを平均5の正規分布から100個生成 – ここから逆に,𝜇を推定したい
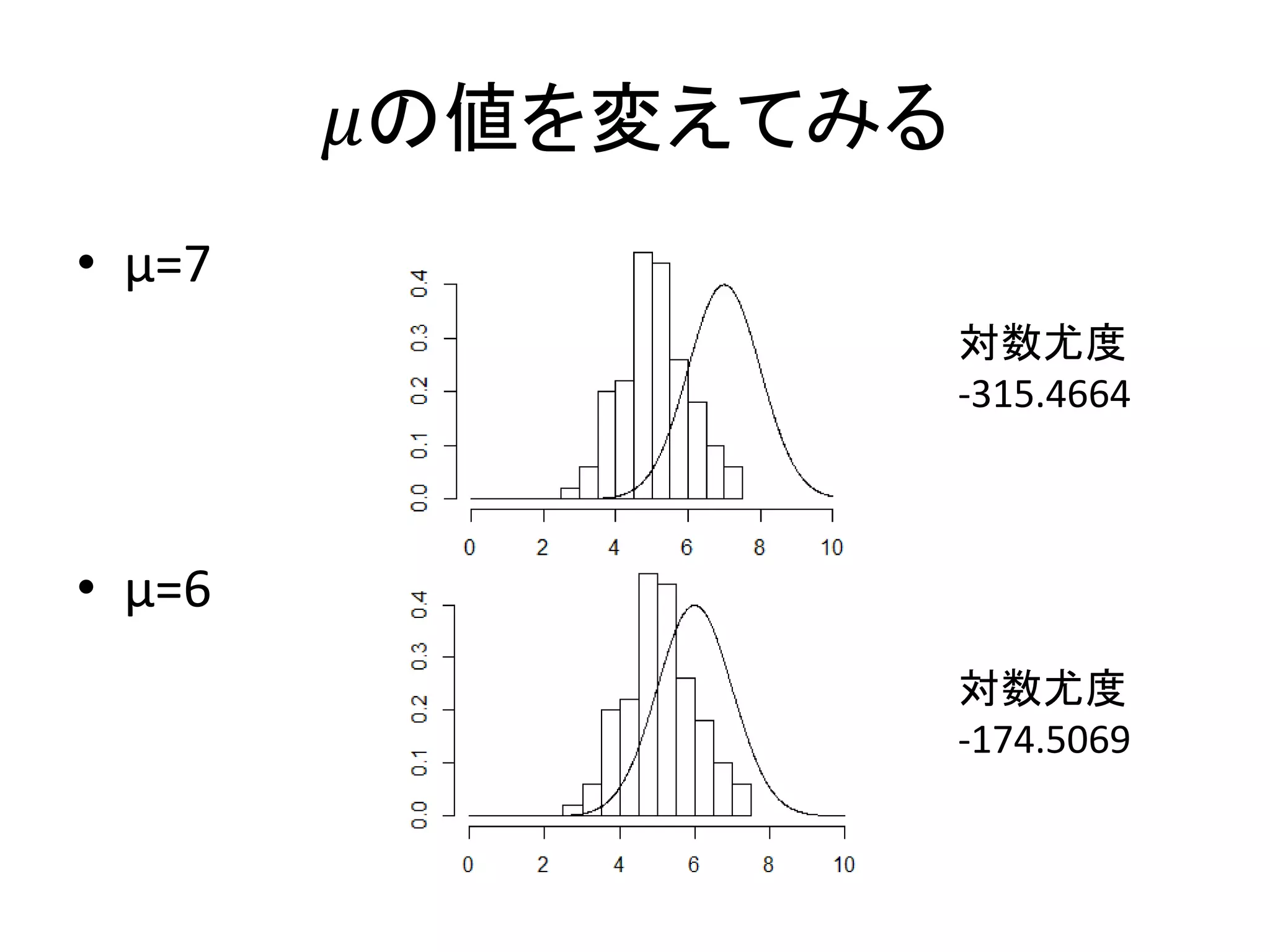
70.
𝜇の値を変えてみる • μ=7 • μ=6 対数尤度 -315.4664 対数尤度 -174.5069
71.
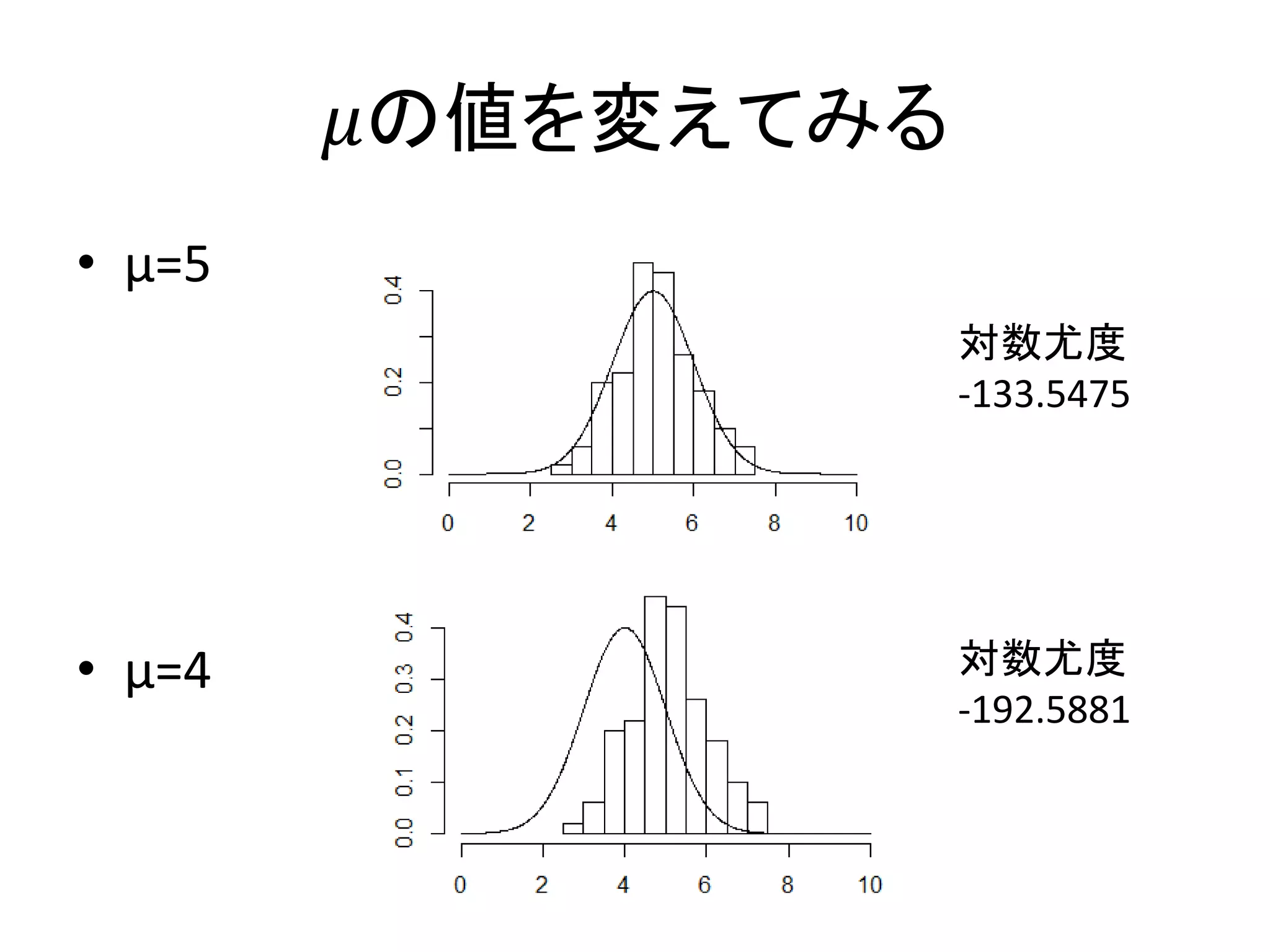
𝜇の値を変えてみる • μ=5 • μ=4 対数尤度 -133.5475 対数尤度 -192.5881
72.
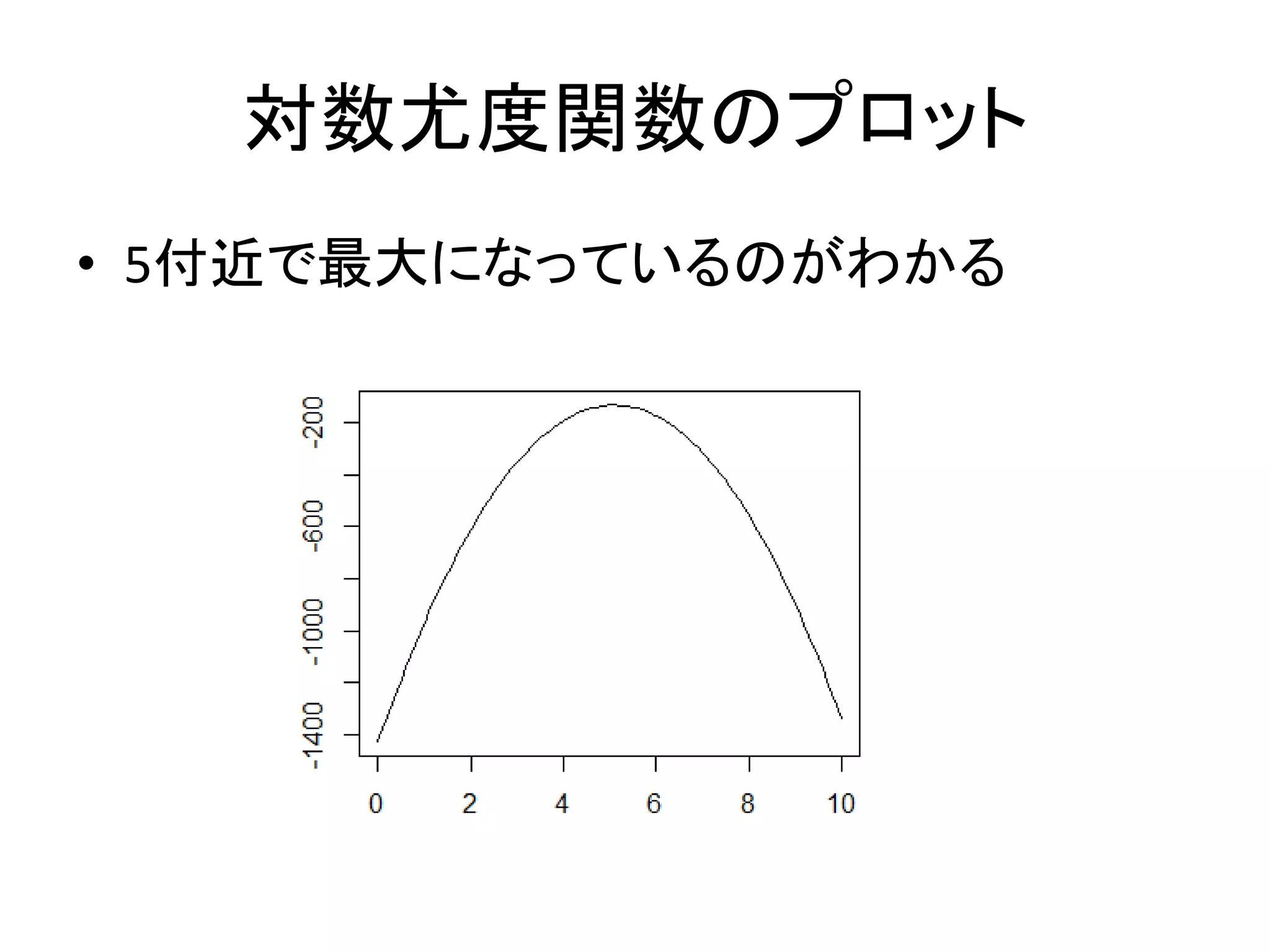
対数尤度関数のプロット • 5付近で最大になっているのがわかる
73.
最尤推定の方法 • 対数尤度関数の最大値を求める – 関数を微分して,接線の方程式が0になる𝜇 –
パラメータが複数ある場合は,パラメータごとに 偏微分をして,連立方程式を解く • 普通は解析的に解けないので数値的に解く • 伝統的な方法と統計モデリング – モデルが変わると対数尤度関数が変わる – モデルごとに微分して,数値的に解くためのアル ゴリズムを用意しないといけない
74.
最尤推定の問題 • 過学習しやすい – 最尤推定は,手元のデータのみでパラメータを推論 する –
つまり,手元のデータに「だけ」当てはまったモデルを 作ってしまいがち • これを過学習(オーバーフィッティング)と呼ぶ • 解を求めるのが困難な場合がある – 尤度関数が複雑になると,大局的に尤度を最大にす る値に到達するのが困難 – 初期値を変えていろいろ試す必要がある • それでも最適解である保証はなかなか得られない
75.
2.4 ベイズ推定とMCMC • 「伝統」の問題点を解決する –
その1つがベイズの定理を用いたベイズ推定と,マル コフ連鎖モンテカルロ法(MCMC) • 「ベイズ」の特徴 – パラメータを確率変数と考える – ベイズでは,パラメータを定数ではなく確率分布とし て推定する • パラメータが複数あったら,その同時分布 • でも実際,パラメータを評価するときは周辺分布を見る
76.
ベイズの定理 • ベイズ推定はベイズの定理で解く – ベイズでは𝑝(𝜃|𝑌)が知りたい •
データ𝑌を条件とした,パラメータ𝜃の確率分布 • 事後分布と呼ぶ – 𝑝(𝜃)はデータを得る前のパラメータの分布 • 事前分布と呼ぶ 𝑝 𝜃 𝑌 = 𝑝 𝑌 𝜃 𝑝 𝜃 𝑝 𝑌
77.
ベイズの定理 • 事後分布は尤度関数と事前分布の積に比例 – ∝は比例することを意味する –
尤度関数に事前分布をかけても確率分布にならない • 𝑝(𝑌)で割れば確率分布になる • その意味で, 𝑝(𝑌)は正規化定数であるといえる • 𝑝(𝑌) – データYのみに依存する定数値 – 𝑝 𝑌 は積分計算が大変で直接は求まらない • え? 𝑝 𝜃 𝑌 ∝ 𝑝 𝑌 𝜃 𝑝(𝜃)
78.
じゃあどうしましょう • マルコフ連鎖モンテカルロ法 – 通称MCMC(*´Д`)ハァハァ •
後半はいらない • 事後分布からパラメータをサンプリング – 事後分布がわからないのにサンプリング? – その辺の理屈は本書のレベルを超えるので,他 書で勉強してください
79.
MCMCの利点 • 𝑝(𝑌)を求めずに事後分布が得られる – ベイズの定理を無理なく解くことができる –
過去のは無理なやり方で解いていたことも • 事後分布の周辺分布が簡単に得られる – パラメータを個別に評価するためには,事後分布 を周辺化する必要がある – MCMCでは直接周辺分布が得られる
80.
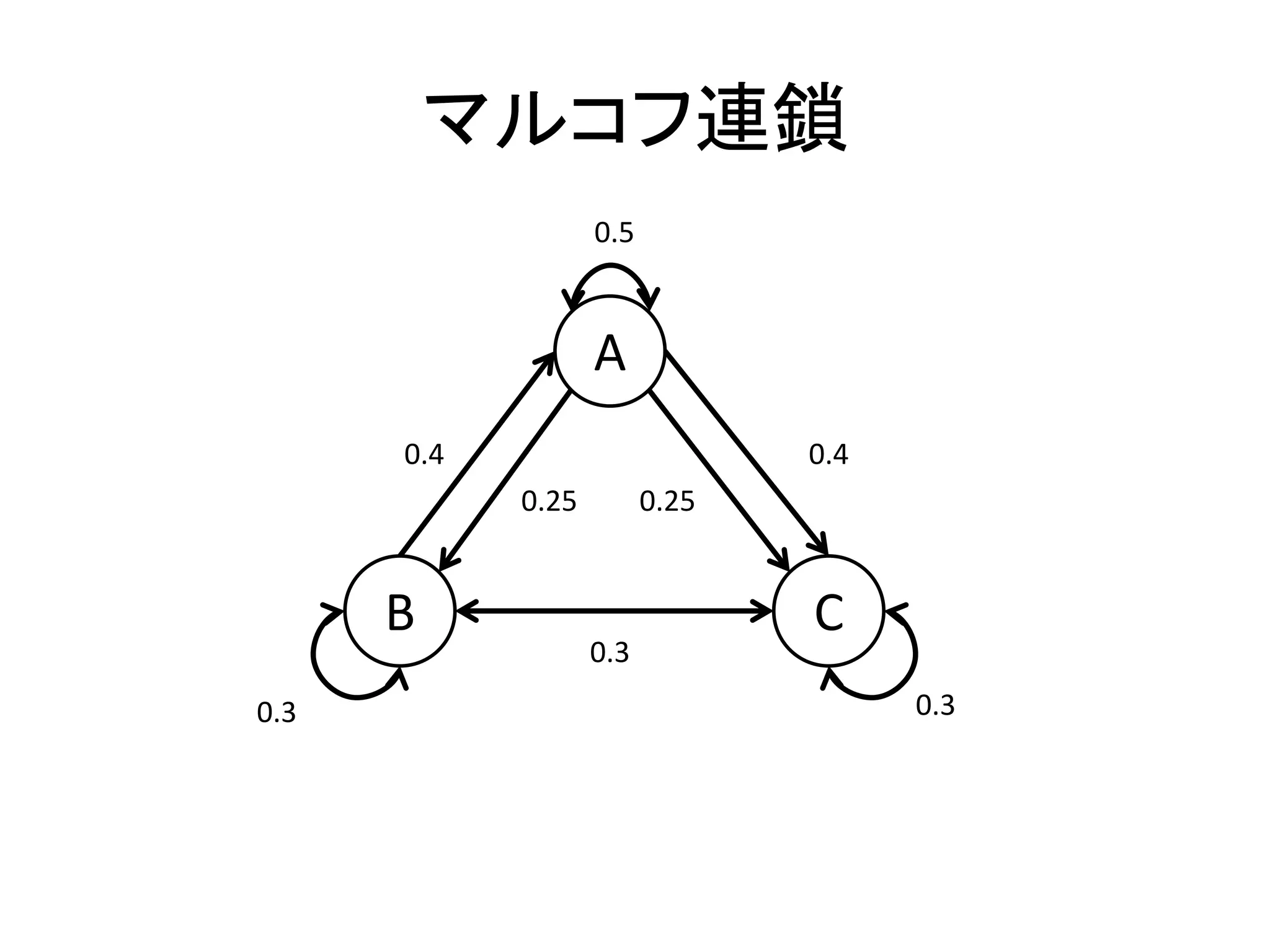
マルコフ連鎖って何よ • ある状態から,別の状態に推移する確率だけが 決まっている • 推移確率行列 –
AからBに移行する確率は0.25 – BからAは0.4 – CからCは0.3 A B C A 0.5 0.25 0.25 B 0.4 0.3 0.3 C 0.4 0.3 0.3
81.
マルコフ連鎖 A B C 0.25 0.3 0.4 0.5 0.30.3 0.25 0.4
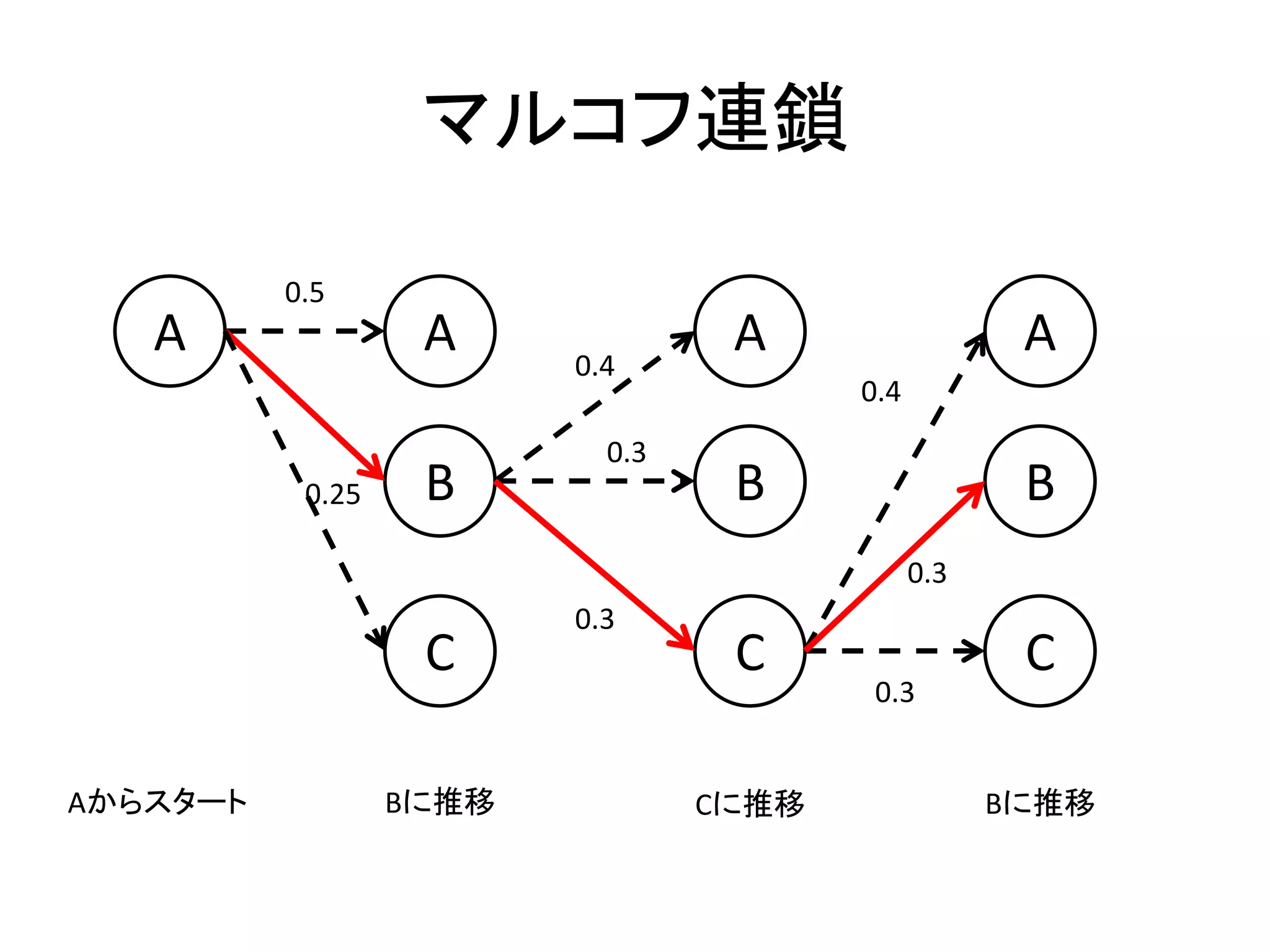
82.
マルコフ連鎖 A A B C 0.5 0.25 Aからスタート Bに推移 A B C 0.4 0.3 0.3 Cに推移 A B C Bに推移 0.3 0.3 0.4
83.
マルコフ連鎖 • 初期分布 – 最初にA,B,Cのどの状態にあるかを決めるもの –
たとえば1/3,1/3,1/3 • 推移確率に従って状態を変えていく – 2時点目においてAである確率は, – 初期分布×推移確率行列 – というように,推移確率行列をかけていくことで計 算ができる
84.
定常分布 • マルコフ連鎖を続けていると・・・ – 各状態にたどり着く確率は変化しなくなってくる –
それを定常分布という • 定常分布は推移確率行列のみから決まる – つまり,初期分布には依存しない – ついでに先ほどの推移確率行列の場合, – A=8/18,B=5/18,C=5/18という定常分布となる
85.
定常分布に収束 • 初期状態が1/3の場合 • 必ずBから始まる場合でも・・ –
このように,初期状態にかかわらずステップ6ぐら いで定常分布に収束する 状態 初期分布 ステップ1 ステップ2 ステップ3 ステップ4 ステップ5 ステップ6 ステップ7 ステップ8 A 0.333333 0.433333 0.443333 0.444333 0.444433 0.444443 0.444444 0.444444 0.444444 B 0.333333 0.283333 0.278333 0.277833 0.277783 0.277778 0.277778 0.277778 0.277778 C 0.333333 0.283333 0.278333 0.277833 0.277783 0.277778 0.277778 0.277778 0.277778 状態 初期分布 ステップ1 ステップ2 ステップ3 ステップ4 ステップ5 ステップ6 ステップ7 ステップ8 A 0 0.4 0.44 0.444 0.4444 0.44444 0.444444 0.444444 0.444444 B 1 0.3 0.28 0.278 0.2778 0.27778 0.277778 0.277778 0.277778 C 0 0.3 0.28 0.278 0.2778 0.27778 0.277778 0.277778 0.277778
86.
連続分布でも同様に • 連続分布でも定常分布が存在する – いくつかの条件がいるが・・・ –
MCMCを使う場合は,この条件を満たす • 連続分布の推移確率行列 – 状態=パラメータの値 • 先程の例の状態(A,B,C)の推移は,ベイズ統計では連続的 なパラメータの値の推移と同じ – あるステップでパラメータの値が決まれば,次のス テップでどのような値になるかが確率的に決まる
87.
MCMCは何をやっているか • 定常分布をシミュレーションで求める – 事後分布が定常分布となるようなマルコフ連鎖を発 生させる –
各パラメータが推移する確率はいずれ収束し,それ が定常分布=事後分布となる • MCMCにもいろんな方法が – ギブスサンプラー – メトロポリス・ヘイスティング – ハミルトニアンモンテカルロ
88.
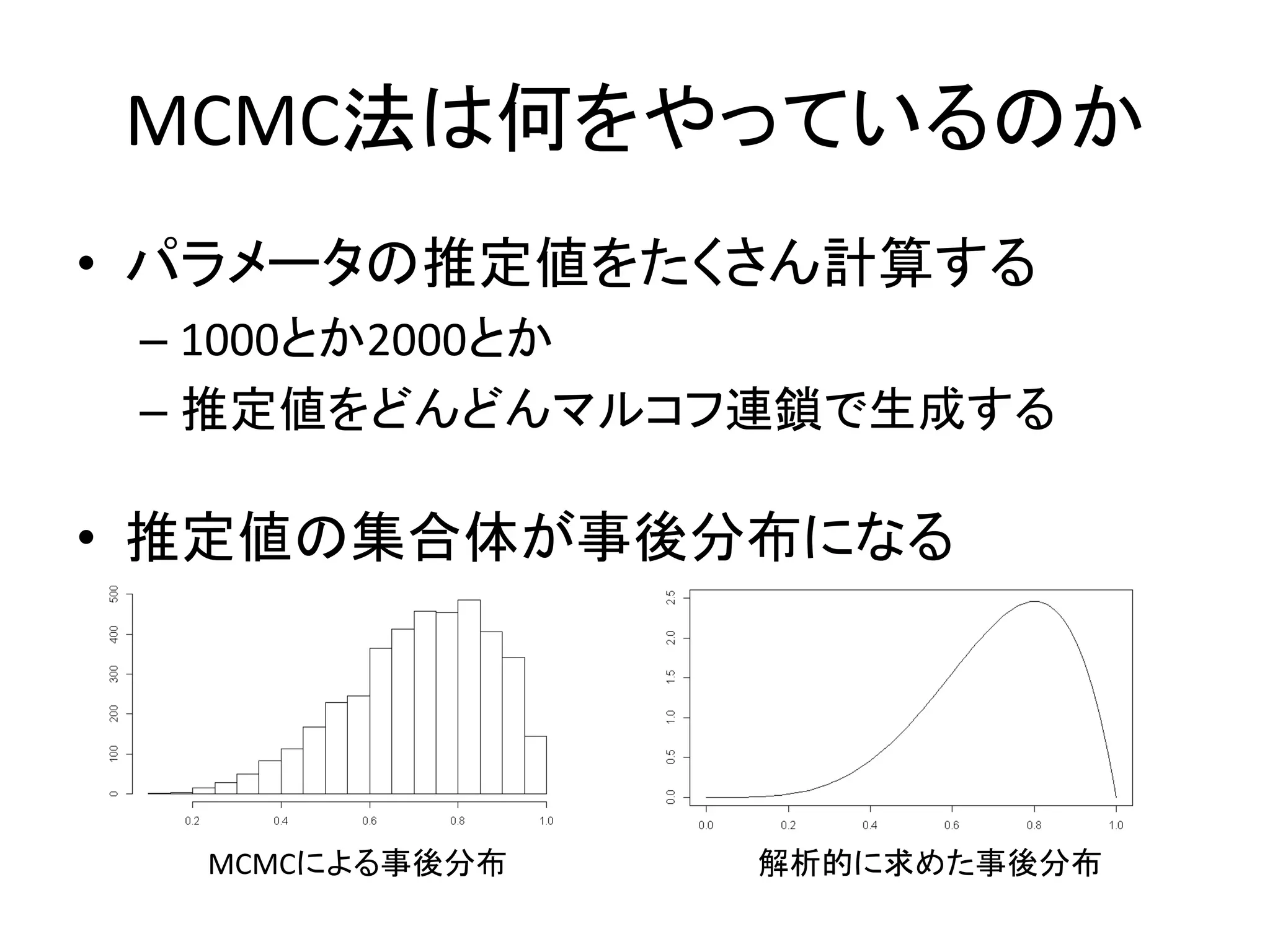
MCMC法は何をやっているのか • パラメータの推定値をたくさん計算する – 1000とか2000とか –
推定値をどんどんマルコフ連鎖で生成する • 推定値の集合体が事後分布になる MCMCによる事後分布 解析的に求めた事後分布
89.
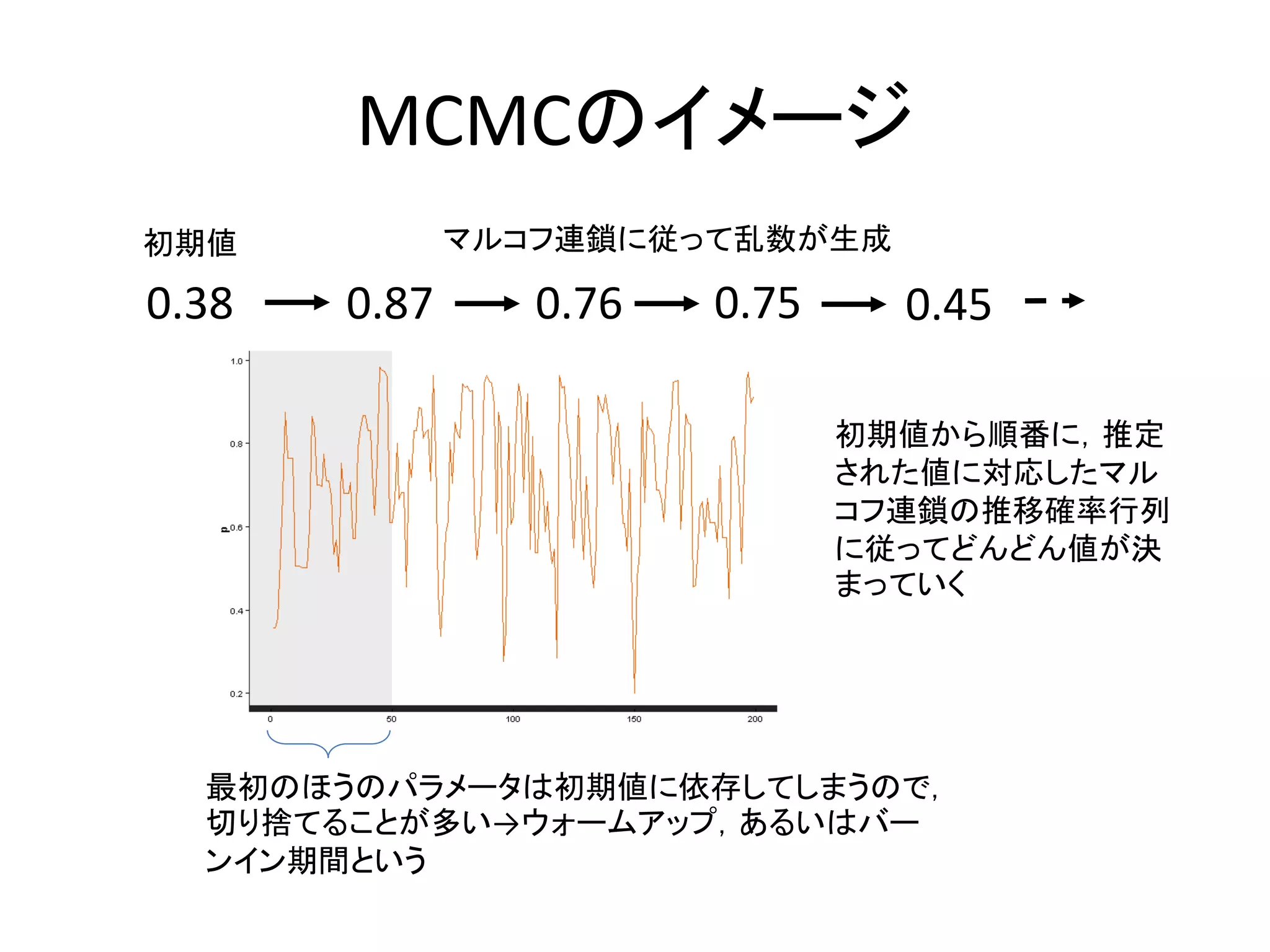
MCMCのイメージ 0.38 初期値 0.87 0.76 0.75 マルコフ連鎖に従って乱数が生成 0.45 最初のほうのパラメータは初期値に依存してしまうので, 切り捨てることが多い→ウォームアップ,あるいはバー ンイン期間という 初期値から順番に,推定 された値に対応したマル コフ連鎖の推移確率行列 に従ってどんどん値が決 まっていく
90.
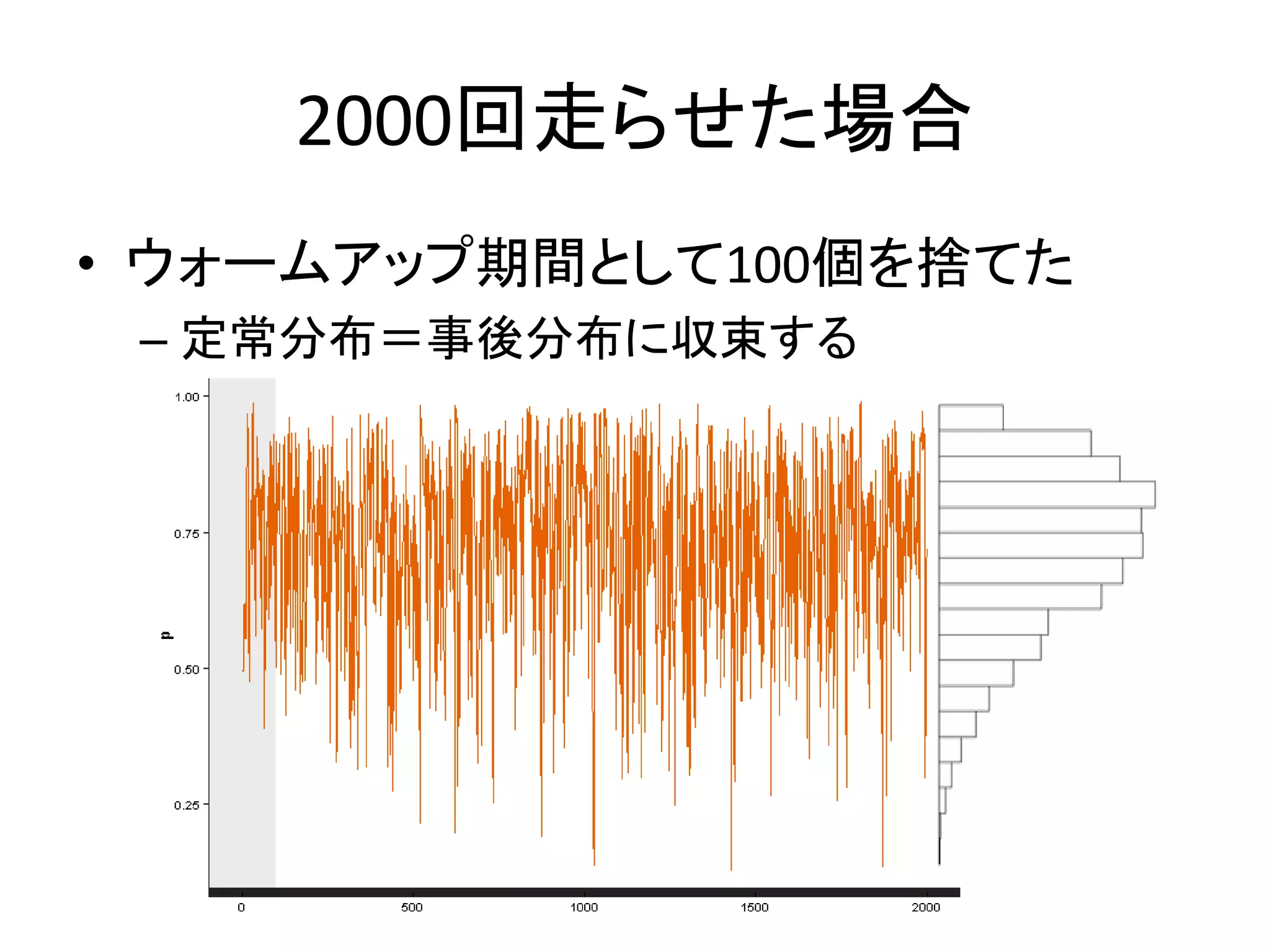
2000回走らせた場合 • ウォームアップ期間として100個を捨てた – 定常分布=事後分布に収束する
91.
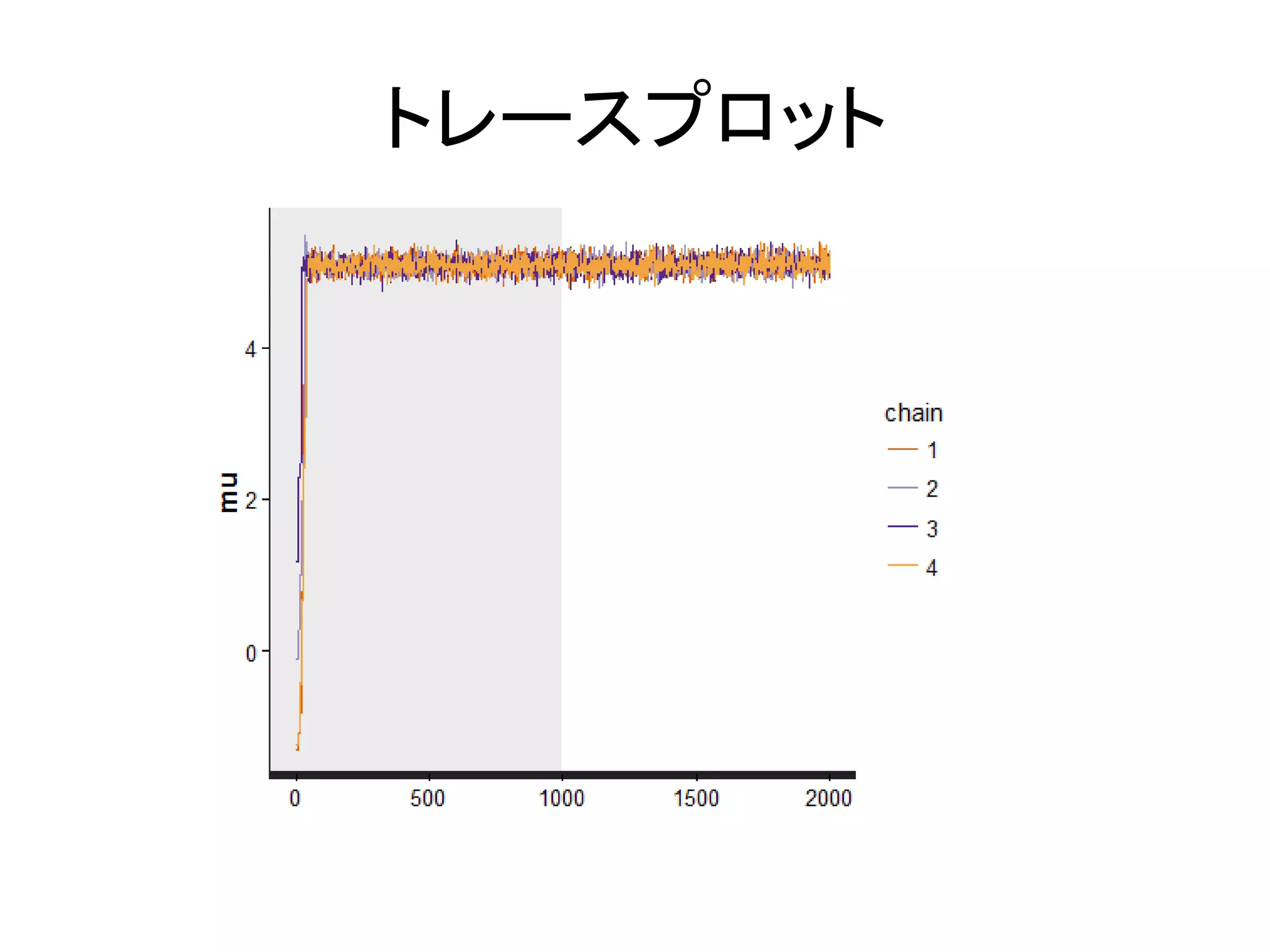
サンプルの集合体が推定結果 • サンプル列 – マルコフ連鎖によってサンプリングされたパラメー タの値の集合 –
初期値と乱数の種を決めて得られたサンプル列 をchainと呼ぶ – 普通は,複数のchainを得て評価する • トレースプロット(trace plot) – サンプル列をステップ数で並べた折れ線グラフ
92.
トレースプロット
93.
トレースプロット
94.
事後分布の確率密度
95.
収束していない事後分布
96.
収束していな事後分布
97.
事後分布の収束評価 • トレースプロットを見る – チェインがあっちゃこっちゃしてないか見る •
自己相関を確認 – 収束していないと、ひとつ前の値の影響を強く受ける • 収束すると、ランダムになる – 事後分布をサンプル列から適当な間隔でまびいて評価す ることで、自己相関が小さくなることがある • thinningと呼び、Stanで間引き間隔を指定できる • 複数のチェインの一致の程度を見る – Rhatという指標を見る 4章に詳しい
98.
事後分布の評価の仕方 • MCMCサンプル列を要約する – 平均値
→ パラメータの期待値(EAPとも呼ぶ) • 確率が最大になる値はMAP推定値と呼ぶ • Maximum a posterioriの略 – SD → パラメータの推定精度 • 「伝統」でいうところの標準誤差のようなもの – 95%区間 → パラメータの信頼区間 • ベイズ信頼区間
99.
2.5 ベイズ信頼区間とベイズ予測区間 • ベイズ信頼区間 –
得られた事後分布の特定の信頼度の区間 • 信頼度が95%の場合、95%信頼区間 – MCMCなら分位点から簡単に計算可能 • 95%の場合は、0.025と0.975の分位点をみればよい • 信頼区間の重要性 – 事後分布は常に単峰で左右対称とは限らない • SDだけでは、パラメータの精度は評価できない – 相関係数などもゆがんだ分布になるので信頼区間を 使って評価する方がよい
100.
予測区間 • 将来得られるデータが散らばりうる範囲 – 予測分布の95%区間 •
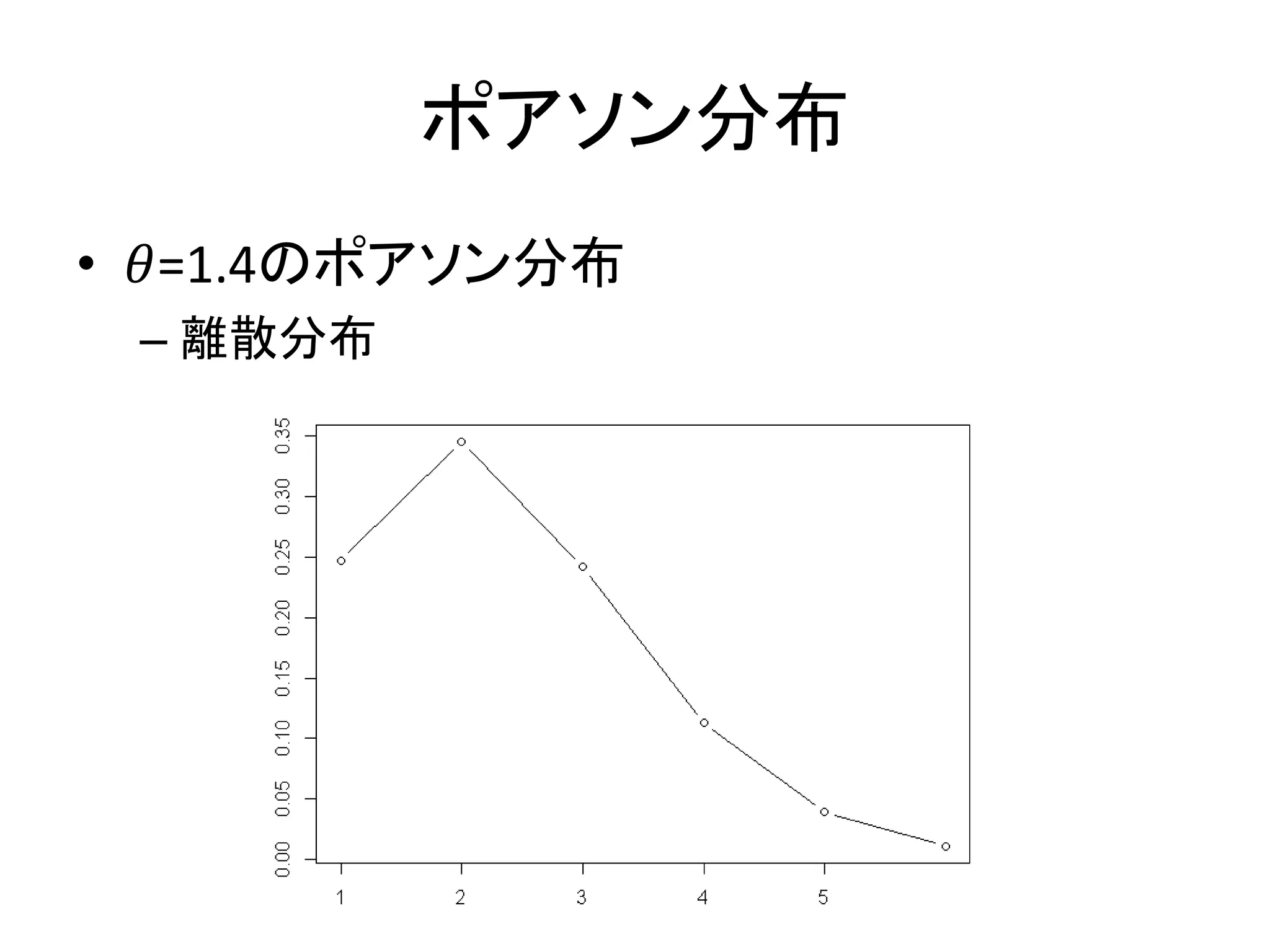
流れ星の例 – しし座流星群の夜に流れ星の数を数える • 10分10回観測 • 𝑌 = 0,1,1,3,0,3,3,2,1,0だった – ポアソン分布に従うと仮定すると、次の10分に観測で きる流れ星の数はいくらぐらいだろうか? • 𝑌 ~ 𝑃𝑜𝑖𝑠𝑠𝑜𝑛(𝜃)
101.
最尤推定における予測 • 𝜃の最尤推定値は1.4 – ポアソン分布の平均パラメータ𝜃に1.4を代入した ものが予測分布 –
𝜃の標準誤差を加味して予測分布を作る場合も ある • ただしその場合は積分しないといけない
102.
ポアソン分布 • 𝜃=1.4のポアソン分布 – 離散分布
103.
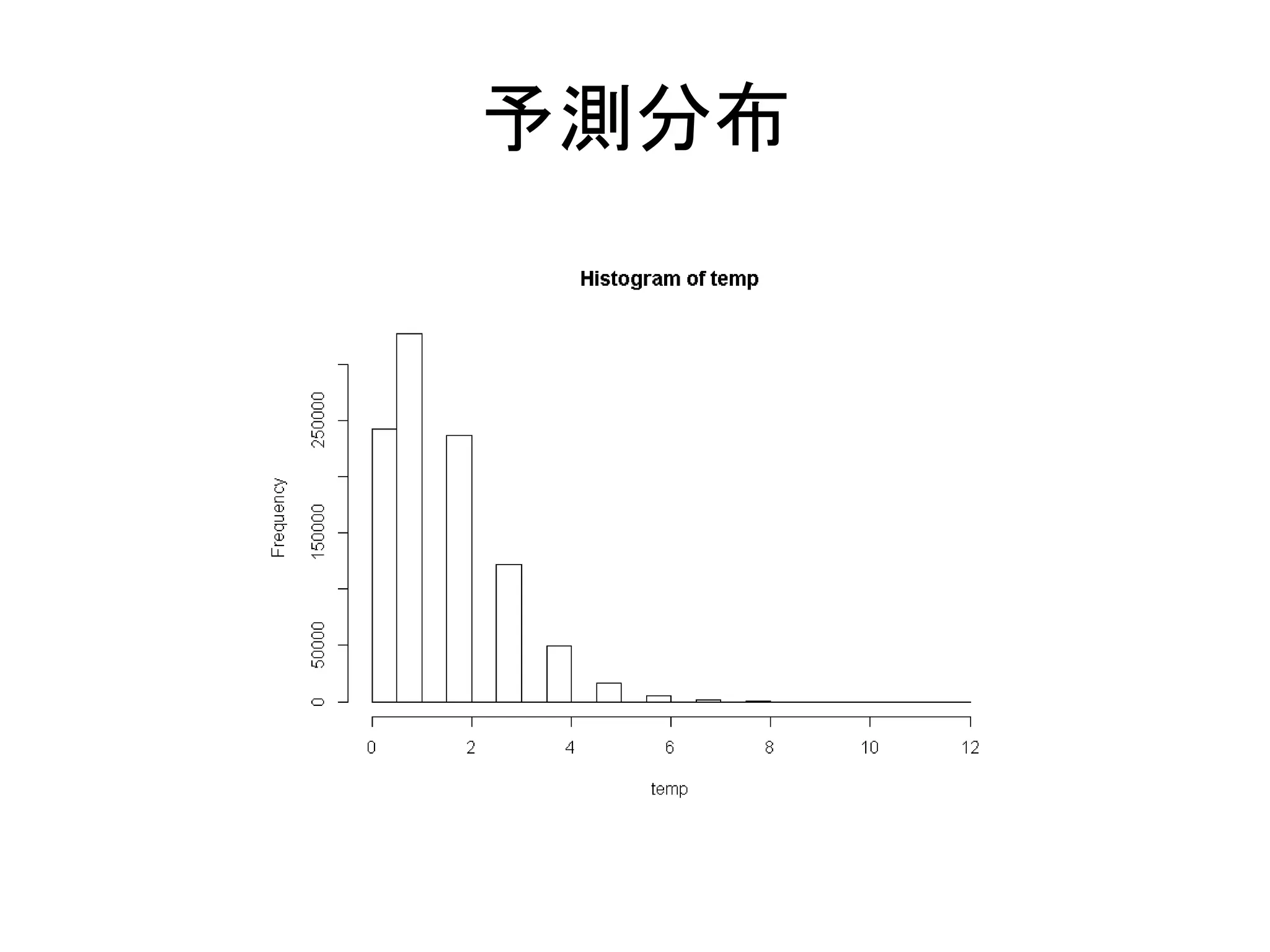
ベイズ予測区間 • 積分によって求めることができる – 予測分布
= ∫ 𝑝 𝑦 𝜃 𝑝 𝜃 𝑌 𝑑𝜃 • 𝑝(𝑦|𝑌) • 事後分布で重みづけた確率モデル • MCMCで計算された𝜃を全部使う – 例えば1000個の𝜃がサンプリングされたら、 – 1000個のポアソン分布を作成し、乱数を生成 – 乱数によって形作られたものが予測分布
104.
予測分布
105.
最尤推定とベイズ推定の関係 • ベイズの定理 • 最尤推定は事前分布が一様分布のMAP –
最尤推定は尤度のみを使って推定 – もし事前分布𝑝 𝜃 が一様分布なら、尤度関数に すべて同じ値をかけたものが事後分布に比例 – その最大事後確率推定値(MAP)は尤度を最大 にする点と同じ 𝑝 𝜃 𝑌 ∝ 𝑝 𝑌 𝜃 𝑝(𝜃)
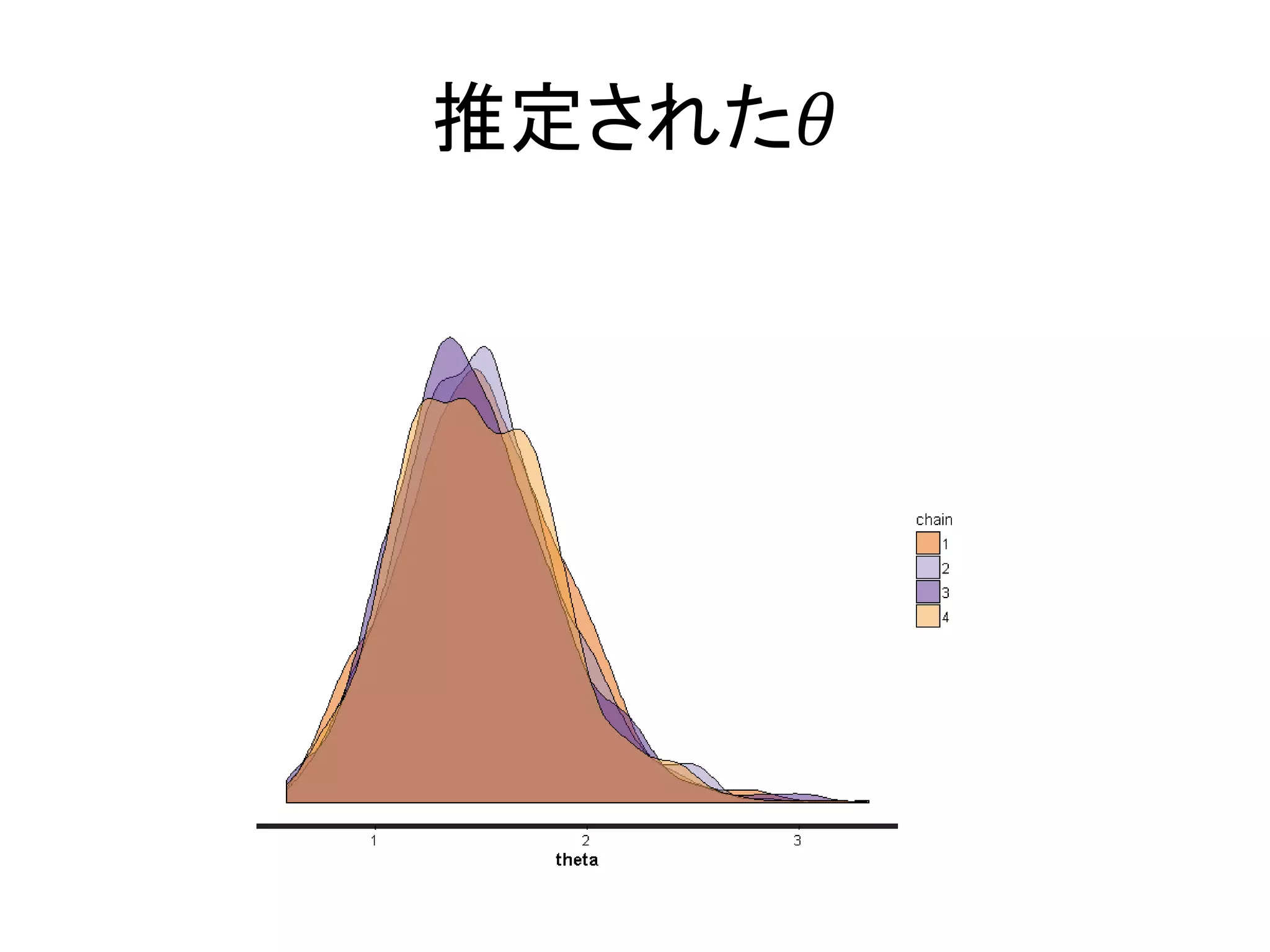
106.
2.7 本書の事前分布の選び方 • 事前分布の選び方 –
恣意的に選ぶのはよくない • 背景知識が不十分な場合は、特定の値がでやすいような事前分 布を選ぶのは適切ではない • 再現性の低下の元になる – 無情報事前分布 • 範囲の広い一様分布 • 分散がすごい大きい分布 – 弱情報事前分布 • ある程度の知識がある場合は、それを反映させた事前分布を用 いることも有効
107.
推定された𝜃
108.
3章 統計モデリングをはじめる前に
109.
3.1 データ解析の前準備 • データをとる前に –
背景知識の収集 • 該当分野においてよく使われる手法や仮定を調べる – 問題設定 • データから何を知りたいかをまとめる • 何を主張したいかをまとめる • どういうストーリー、図で主張するとよいかを考える – 解析計画 • どの手法を使うか • 解析のベストシナリオを描く • マイルストーンを考えておく
110.
データ解析の前準備 • データをとった後で – データの分布の確認 •
ヒストグラム・箱ひげ図を見る • 散布図・クロス表を見る • 時系列データの場合は折れ線グラフなど • データ分布の確認の重要性 – 分布の確認は、データの生成メカニズムを推測する うえでとても重要 • どの確率分布を仮定するかを類推するのに役立つ – 図の描写はRなどが便利
111.
3.2 統計モデリングの手順 • 1.解析の目的 –
さきほどの問題設定と同じ • 2.データの分布の確認 – さきほどと同じ – これらは基本中の基本!
112.
統計モデリングの手順 • 3.メカニズムの想像 – データ生成のメカニズムやデータとデータをつなぐメ カニズムを考える •
4.モデル式の記述 – メカニズムを式に落とし込む – Y ~ normal(mu, sigma) など • 5.シミュレーション – Rなどをつかって、モデル式の性質を調べる – 仮定した確率モデルからデータをRで生成してみる
113.
統計モデリングの手順 • 6.Stanで実装 – Stanのコードを書いて実装し、パラメータ推定を実行する –
Rで想定した確率モデルから生成した乱数データを分析し て、真値が得られるかの確認も重要 • 7.推定結果の解釈 – 推定結果やベイズ信頼区間などをもとに解釈をしたり、図 を描いたりする • 8.図によるモデルのチェック – モデルがうまく当てはまっていそうかを図でチェックする
114.
モデリングの段取り • メカニズムの想像の仕方 – イラストで表現 •
パス図、グラフィカルモデル、概念図など • 数式で表現する前段階でやっておくと便利 – まずはシンプルなモデルから • つい最初から複雑なメカニズムを考えがちだが、うまく モデルが書けなかったり、推定できなかったりする • 確実にうまくいくモデルから徐々に複雑に
115.
モデリングの段取り • シンプルなモデルの例 – 当該分野の教科書に載ってるようなモデル –
説明変数を絞る – 確率変数はなるべく独立と考えて、多変量正規分布をい きなり使わない – グループ差や個人差は最初は考慮しない • データも最初は小さくする – データが大きいと計算時間がかかり、モデルの試行錯誤 にも時間がかかる – ランダムに抽出して1/10ぐらいにする – カテゴリの水準を限定する
116.
再現性のチェック • 再現性 – 同じ手順に従えば、毎回同じ結果が得られること –
推定結果の再現性をチェックして、モデルの安定性、 頑健性を確認する • チェックポイント – 異なるデータセットでも同じような結果になるか • データを数個除いて分析しても同じになるか – ソフトやアルゴリズムを変えても同じ結果になるか • Stan以外のソフトを使っても同じになるか – アルゴリズムが乱数に依存する場合、それらを変え ても同じ推定結果になるか
117.
データ解析のサイクル – データ分析は、ベストモデルを一つ作成できれば それで終わる営みではない – 予測性能が低い場合は原因を考える –
データの増加に伴い、複雑なモデルを作る – 新しい解釈が可能になり、予測精度も上がる
118.
3.3 背景知識の役割 • メカニズムを想像と背景知識 –
統計モデリングでは、データだけからデータ生成 のメカニズムが完全にわかるわけではない – そのため、背景知識が利用される • 背景知識が統計モデリングでは必須 • その当該分野における実質科学的知見(背景知識)を抜 きにしてはメカニズムを想定することはできない
119.
統計モデリングは不良設定問題 • 不良設定問題とは – 答えが与えられた情報だけでは一意に定まらないよ うな問題 –
背景知識などを利用して、可能なデータ生成メカニズ ムの選択肢を限定していく必要がある • モデルの「正しさ」を議論することはできない – 真のモデルがなにかはわからない – あるモデルが、別のモデルよりも正しいかどうかもよ くわからない • どちらがありえそうか、解釈しやすいか、納得できるか
120.
すべての要素を考慮する必要はない • 知りたいことに関わらない問題は削る – 知りたいことと関係ない場合は、できるだけシン プルに表現 –
無駄に複雑にすることは、解釈可能性が落ちる • 問題設定によってモデルが変わる – 知りたいことによって、複雑にする部分、シンプル にする部分が変わる
121.
3.4 モデルの記述方法 • モデル式 –
データとパラメータの関係性 – パラメータとパラメータの関係性 • 確率的な関係性 – Y ~ Normal(μ, 1) • チルダを使う Yは正規分布に確率的に従う • 確定的な関係性 – μ = α + βX • イコールを使う μはα + βXによって規定される
122.
グラフィカルモデル • 確率モデルのパラメータ関係を図示 – ◯に黒文字のノードは推定される確率変数 •
パラメータ – ●に白文字のノードは観測された確率変数 • データ – 矢印(有向リンク)は条件付き確率 – 線分(無向リンク)は同時確率 – 四角い枠は繰り返し • データ数分だけ繰り返す μ Y[n] n = 1,… 20
123.
3.5 情報量規準を使ったモデル選択 • 情報量規準 –
AIC、BIC、あるいはWAIC、WBICなどなど • 前者よりも後者(WAIC、WBIC)のほうがよい • MCMCを使えばこれらは簡単に計算可能 – モデル選択に使える • 予測精度の高いモデルや、データにあったモデルをこれらの指標 で選ぶことができる • 情報量規準に頼りすぎるのはよくない – しかし、情報量規準は万能ではない – WAICが小さいモデルが常に良いモデルとは限らない – 本書では、情報量規準によるモデル選択は扱わない
124.
補足 Stanによるモデリング例
125.
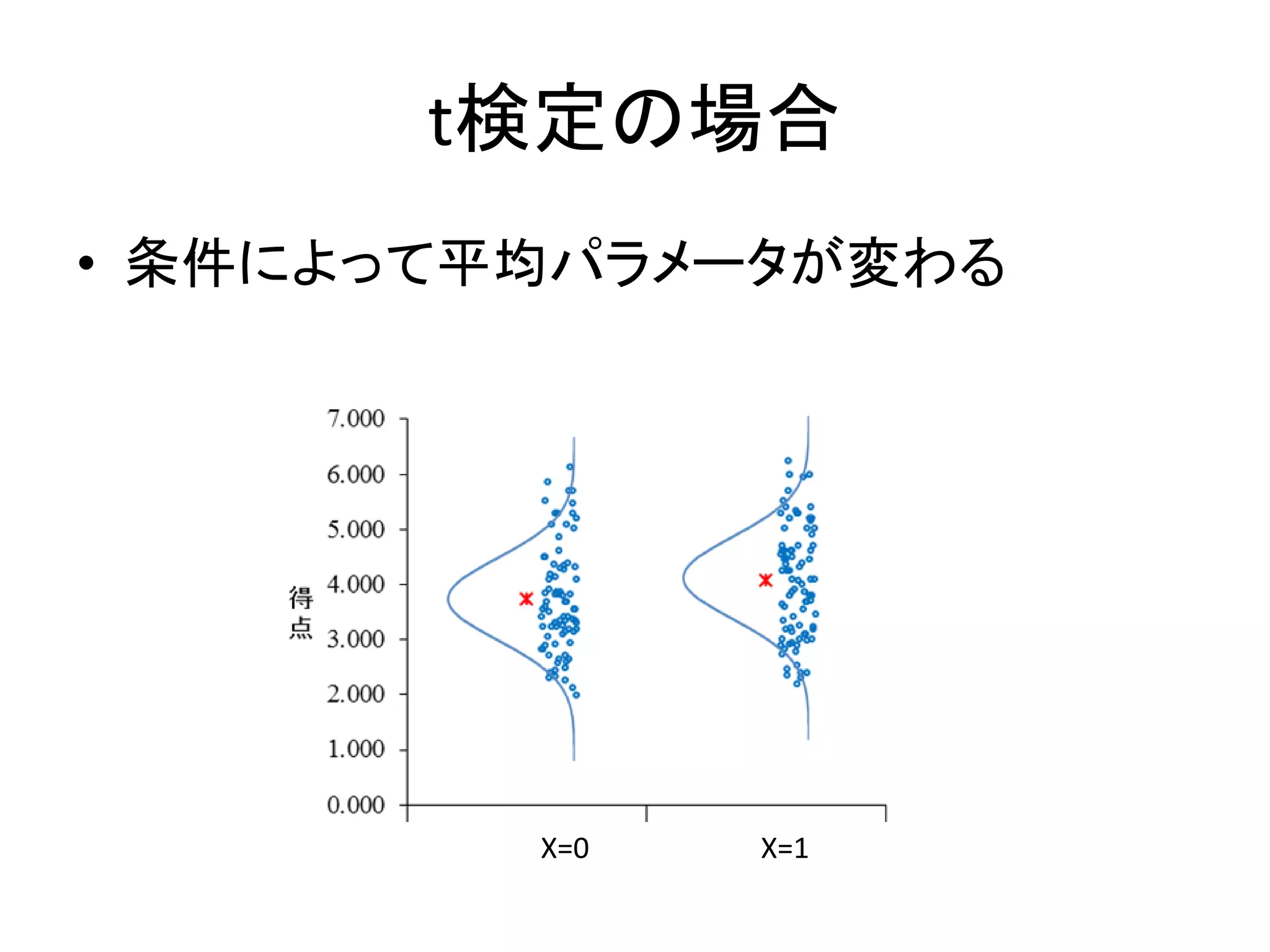
t検定の場合 • 条件によって平均パラメータが変わる X=0 X=1
126.
t検定の場合 • 確率モデル – 𝑌1
𝑛 ~ 𝑁𝑜𝑟𝑚𝑎𝑙 𝜇1, 𝜎 – 𝑌2 𝑚 ~ 𝑁𝑜𝑟𝑚𝑎𝑙(𝜇2, 𝜎) – 𝜇2 = 𝜇1 + 𝛿 • 推定するパラメータは – Y1の平均パラメータ𝜇1と,差のパラメータ𝛿 – 二つの群の共通した標準偏差𝜎
127.
Stanコードの例 • 確率モデル – 𝑌1
𝑛 ~ 𝑁𝑜𝑟𝑚𝑎𝑙 𝜇1, 𝜎 – 𝑌2 𝑚 ~ 𝑁𝑜𝑟𝑚𝑎𝑙(𝜇2, 𝜎) – 𝜇2 = 𝜇1 + 𝛿
128.
回帰分析 • 回帰分析の仮定 – 確率モデルは正規分布 –
データはすべて独立に同一分散の分布から生成 • 心理統計的な回帰分析の書き方 – 𝑌𝑖 = 𝛼 + 𝛽 𝑋𝑖 + 𝑒𝑖 – 𝑒𝑖~ 𝑁(0, 𝜎)
129.
回帰分析の統計モデル • データの生成メカニズムを正規分布と仮定 – 𝑌[𝑛]~
𝑁 𝜇[𝑛], 𝜎 • 平均パラメータ𝜇に線形モデルを仮定 – 𝜇 𝑛 = 𝛼 + 𝛽 𝑋[𝑛] • つまり,こういう確率分布となる – 𝑌[𝑛]~𝑁 𝛼 + 𝛽𝑋[𝑛] , 𝜎
130.
平均が𝛼 + 𝛽𝑋[𝑛]の正規分布 平均値がXの値によって変わる, 条件付き正規分布 すべてのXの値において,分散 が等しい正規分布を仮定 →均一分散の仮定 青い破線は95%予測区間
131.
回帰分析の場合 • パラメータは3つ – 𝛼,
𝛽, 𝜎 • 切片,回帰係数,残差SD • 確率モデル – 𝑌[𝑛]~ 𝑁 𝜇[𝑛], 𝜎 – 𝜇 𝑛 = 𝛼 + 𝛽 𝑋[𝑛]
Download













































![ベクトルの要素の表記
• 添字のバージョン
– 𝑌𝑛
– データ𝑌の𝑛番目の値
– 数学ではこっちを使う
• 大カッコバージョン
– 𝑌[𝑛]
– データ𝑌の𝑛番目の値
– Stanの場合はこっちのほうがわかりやすいかも](https://image.slidesharecdn.com/stanrbayesmodeling-161124025614/75/Stan-R-1-3-56-2048.jpg)









![尤度関数のプロット
• Y[1]が3の場合
– 𝑁𝑜𝑟𝑚𝑎𝑙 𝑌 = 3 𝜇 =
1
2 𝜋
exp
− 3−𝜇 2
2
– 𝜇は3が一番尤もらしい](https://image.slidesharecdn.com/stanrbayesmodeling-161124025614/75/Stan-R-1-3-66-2048.jpg)
![尤度関数のプロット
• Yが(1,2,3,4,5)の場合 5人のデータ
– 𝑁𝑜𝑟𝑚𝑎𝑙 𝑌 𝜇 =
1
2 𝜋
exp
− 𝑌[𝑛]−𝜇 2
2
5
𝑛=1
– 1人より5人のほうが尤度の分散は小さい
Πは繰り返し「かける」
ことを意味する
Σは繰り返す「たす」の
を思い出そう](https://image.slidesharecdn.com/stanrbayesmodeling-161124025614/75/Stan-R-1-3-67-2048.jpg)





































![グラフィカルモデル
• 確率モデルのパラメータ関係を図示
– ◯に黒文字のノードは推定される確率変数
• パラメータ
– ●に白文字のノードは観測された確率変数
• データ
– 矢印(有向リンク)は条件付き確率
– 線分(無向リンク)は同時確率
– 四角い枠は繰り返し
• データ数分だけ繰り返す
μ Y[n]
n = 1,… 20](https://image.slidesharecdn.com/stanrbayesmodeling-161124025614/75/Stan-R-1-3-122-2048.jpg)





![回帰分析の統計モデル
• データの生成メカニズムを正規分布と仮定
– 𝑌[𝑛]~ 𝑁 𝜇[𝑛], 𝜎
• 平均パラメータ𝜇に線形モデルを仮定
– 𝜇 𝑛 = 𝛼 + 𝛽 𝑋[𝑛]
• つまり,こういう確率分布となる
– 𝑌[𝑛]~𝑁 𝛼 + 𝛽𝑋[𝑛] , 𝜎](https://image.slidesharecdn.com/stanrbayesmodeling-161124025614/75/Stan-R-1-3-129-2048.jpg)
![平均が𝛼 + 𝛽𝑋[𝑛]の正規分布
平均値がXの値によって変わる,
条件付き正規分布
すべてのXの値において,分散
が等しい正規分布を仮定
→均一分散の仮定
青い破線は95%予測区間](https://image.slidesharecdn.com/stanrbayesmodeling-161124025614/75/Stan-R-1-3-130-2048.jpg)
![回帰分析の場合
• パラメータは3つ
– 𝛼, 𝛽, 𝜎
• 切片,回帰係数,残差SD
• 確率モデル
– 𝑌[𝑛]~ 𝑁 𝜇[𝑛], 𝜎
– 𝜇 𝑛 = 𝛼 + 𝛽 𝑋[𝑛]](https://image.slidesharecdn.com/stanrbayesmodeling-161124025614/75/Stan-R-1-3-131-2048.jpg)
























































































