Downloaded 47 times
















![クロス集計表の条件付き確率分布 クロス集計表の確率分布の式を、ターゲットの条件付き確率 p ( i 1 , i 2 ) p ( i 1 | i 2 ) p ( i 2 ) により展開する。 最後の式の、はじめの [ ] は I 2 の値が与えられた下での I 1 の条件付き確率を示し、次の { } はその I 2 の値が実現する確率を示す。 p ( i 2 ) を含まない部分](https://image.slidesharecdn.com/aic-110807104734-phpapp01/85/AIC-19-320.jpg)
![クロス集計表の条件付きモデル 興味があるのは、ターゲット変数と説明変数との直接的な関係である。そこで、先の式の [ ] の部分のみに着目し、 p ( i 1 | i 2 ) をパラメータとみなしたときの条件付き対数尤度(坂本ら、 1983 、 § 4.5 )を求めると(定数項を無視して)、 I 2 の各実現値に対する I 1 のクロス集計表は、以下のモデルで表現できる。 パラメータの最尤推定量は、 自由パラメータ数は、 ( c 1 c 2](https://image.slidesharecdn.com/aic-110807104734-phpapp01/85/AIC-20-320.jpg)






















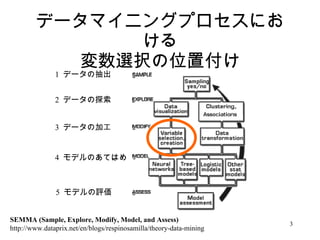
クロス集計表といえばχ2乗検定ですが、AICによる別の分析手法を紹介します。 ひとつのカテゴリカルなターゲット変数に対してカテゴリカルな複数の説明変数候補が与えられた場合、ターゲット変数と説明変数候補とのクロス集計表を作成し、各クロス集計表ごとにこの資料で定義されたAICを計算します。AICの低さが、相関の高さを示します。 この手法は、χ2乗検定におけるp値と異なり、カテゴリーのサイズ(つまり自由度)が異なる説明変数間の比較を可能にします。 資料内の AIC*(I1;I2) の説明は、(成書では30年ほど前に発表されているものですが)ネット上ではあまり見かけないものであり、参考になるかと思います。

![[第2版]Python機械学習プログラミング 第10章](https://cdn.slidesharecdn.com/ss_thumbnails/10-181212011917-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[DSO]勉強会_データサイエンス講義_Chapter7](https://cdn.slidesharecdn.com/ss_thumbnails/dsodatasciencelecturechapter7-191122112044-thumbnail.jpg?width=640&height=640&fit=bounds)








