Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
kazutantan
PPTX, PDF
20,246 views
ベイズファクターとモデル選択
2014年6月8日に広島大学にて開催された魁!! 広島ベイズ塾のワークショップで発表したスライド。
Data & Analytics
◦
Read more
22
Save
Share
Embed
Embed presentation
Download
Downloaded 119 times
1
/ 25
2
/ 25
3
/ 25
4
/ 25
5
/ 25
6
/ 25
7
/ 25
8
/ 25
9
/ 25
10
/ 25
Most read
11
/ 25
Most read
12
/ 25
13
/ 25
14
/ 25
15
/ 25
16
/ 25
Most read
17
/ 25
18
/ 25
19
/ 25
20
/ 25
21
/ 25
22
/ 25
23
/ 25
24
/ 25
25
/ 25
More Related Content
PDF
ベイズ統計入門
by
Miyoshi Yuya
PDF
これからの仮説検証・モデル評価
by
daiki hojo
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
PDF
なぜベイズ統計はリスク分析に向いているのか? その哲学上および実用上の理由
by
takehikoihayashi
PDF
階層ベイズによるワンToワンマーケティング入門
by
shima o
PDF
Rubinの論文(の行間)を読んでみる-傾向スコアの理論-
by
Koichiro Gibo
PDF
「生態学における統計的因果推論」という大ネタへの挑戦:その理論的背景と適用事例
by
takehikoihayashi
ベイズ統計入門
by
Miyoshi Yuya
これからの仮説検証・モデル評価
by
daiki hojo
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
なぜベイズ統計はリスク分析に向いているのか? その哲学上および実用上の理由
by
takehikoihayashi
階層ベイズによるワンToワンマーケティング入門
by
shima o
Rubinの論文(の行間)を読んでみる-傾向スコアの理論-
by
Koichiro Gibo
「生態学における統計的因果推論」という大ネタへの挑戦:その理論的背景と適用事例
by
takehikoihayashi
What's hot
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PPTX
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
PDF
媒介分析について
by
Hiroshi Shimizu
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PDF
一般化線形混合モデル入門の入門
by
Yu Tamura
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
正準相関分析
by
Akisato Kimura
PDF
社会心理学とGlmm
by
Hiroshi Shimizu
PDF
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
PDF
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
PPTX
重回帰分析で交互作用効果
by
Makoto Hirakawa
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
PDF
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
PDF
第4回DARM勉強会 (構造方程式モデリング)
by
Yoshitake Takebayashi
PDF
潜在クラス分析
by
Yoshitake Takebayashi
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
階層モデルの分散パラメータの事前分布について
by
hoxo_m
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
媒介分析について
by
Hiroshi Shimizu
階層ベイズとWAIC
by
Hiroshi Shimizu
一般化線形混合モデル入門の入門
by
Yu Tamura
ベイズ統計学の概論的紹介
by
Naoki Hayashi
正準相関分析
by
Akisato Kimura
社会心理学とGlmm
by
Hiroshi Shimizu
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
重回帰分析で交互作用効果
by
Makoto Hirakawa
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
Stanコードの書き方 中級編
by
Hiroshi Shimizu
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
第4回DARM勉強会 (構造方程式モデリング)
by
Yoshitake Takebayashi
潜在クラス分析
by
Yoshitake Takebayashi
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
Viewers also liked
PDF
ベイズ主義による研究の報告方法
by
Masaru Tokuoka
PPTX
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
PDF
2 3.GLMの基礎
by
logics-of-blue
PDF
1 3.分散分析 anova
by
logics-of-blue
PDF
1 4.回帰分析と分散分析
by
logics-of-blue
PDF
TensorFlowで逆強化学習
by
Mitsuhisa Ohta
PDF
シンギュラリティを知らずに機械学習を語るな
by
hoxo_m
PDF
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
ベイズ主義による研究の報告方法
by
Masaru Tokuoka
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
2 3.GLMの基礎
by
logics-of-blue
1 3.分散分析 anova
by
logics-of-blue
1 4.回帰分析と分散分析
by
logics-of-blue
TensorFlowで逆強化学習
by
Mitsuhisa Ohta
シンギュラリティを知らずに機械学習を語るな
by
hoxo_m
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
Similar to ベイズファクターとモデル選択
PDF
演習II.第1章 ベイズ推論の考え方 Part 2.スライド
by
Wataru Shito
PDF
2019年 演習II.第1章 ベイズ推論の考え方 Part 1
by
Wataru Shito
PDF
第一回ぞくパタ
by
Akifumi Eguchi
PDF
演習II.第1章 ベイズ推論の考え方 Part 1.講義ノート
by
Wataru Shito
PPTX
基礎からのベイズ統計学 3章(3.1~3.3)
by
TeranishiKeisuke
PDF
Casual learning machine learning with_excel_no3
by
KazuhiroSato8
PDF
第4章 確率的学習---単純ベイズを使った分類
by
Wataru Shito
PDF
PRML第3章_3.3-3.4
by
Takashi Tamura
PPTX
ベイズ基本0425
by
asato kuno
PPTX
PRML1.2
by
Tomoyuki Hioki
PPTX
ベイズ基本0425
by
asato kuno
PPTX
ベイズ基本0425
by
asato kuno
PDF
Pattern Recognition and Machine Learning study session - パターン認識と機械学習 勉強会資料
by
Taro Masuda
PDF
20130716 はじパタ3章前半 ベイズの識別規則
by
koba cky
PDF
3.4
by
show you
PDF
Bayes
by
tdualdir
PDF
ベイズ入門
by
Zansa
PDF
A09 穴田研究室1 木村優斗,小笠原琉佳,坂本慶多,高橋昂大
by
aomorisix
PDF
いいからベイズ推定してみる
by
Makoto Hirakawa
PDF
Pattern recognition sec1 2(q)
by
ssuserfecf16
演習II.第1章 ベイズ推論の考え方 Part 2.スライド
by
Wataru Shito
2019年 演習II.第1章 ベイズ推論の考え方 Part 1
by
Wataru Shito
第一回ぞくパタ
by
Akifumi Eguchi
演習II.第1章 ベイズ推論の考え方 Part 1.講義ノート
by
Wataru Shito
基礎からのベイズ統計学 3章(3.1~3.3)
by
TeranishiKeisuke
Casual learning machine learning with_excel_no3
by
KazuhiroSato8
第4章 確率的学習---単純ベイズを使った分類
by
Wataru Shito
PRML第3章_3.3-3.4
by
Takashi Tamura
ベイズ基本0425
by
asato kuno
PRML1.2
by
Tomoyuki Hioki
ベイズ基本0425
by
asato kuno
ベイズ基本0425
by
asato kuno
Pattern Recognition and Machine Learning study session - パターン認識と機械学習 勉強会資料
by
Taro Masuda
20130716 はじパタ3章前半 ベイズの識別規則
by
koba cky
3.4
by
show you
Bayes
by
tdualdir
ベイズ入門
by
Zansa
A09 穴田研究室1 木村優斗,小笠原琉佳,坂本慶多,高橋昂大
by
aomorisix
いいからベイズ推定してみる
by
Makoto Hirakawa
Pattern recognition sec1 2(q)
by
ssuserfecf16
ベイズファクターとモデル選択
1.
ベイズファクターと モデル選択
2.
自己紹介 • 前田和寛(MAEDA Kazuhiro) •
比治山大学短期大学部 総合生活デザイン学科 • kazum@hijiyama-u.ac.jp • http://kz-md.net/ • Twitter: @kazutan #ビールうめぇ
3.
本日の内容 • ベイズの定理について考える • ベイズファクターとモデル選択 ※イメージを掴んでもらうことを意識してます •
細かいところで用語が不適切な場合があるかもしれません
4.
ベイズの定理について考える
5.
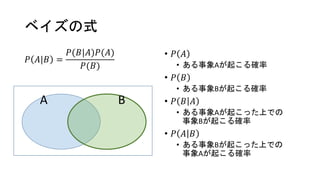
ベイズの式 𝑃 𝐴|𝐵 = 𝑃(𝐵|𝐴)𝑃(𝐴) 𝑃(𝐵) •
𝑃 𝐴 • ある事象Aが起こる確率 • 𝑃 𝐵 • ある事象Bが起こる確率 • 𝑃 𝐵 𝐴 • ある事象Aが起こった上での 事象Bが起こる確率 • 𝑃 𝐴 𝐵 • ある事象Bが起こった上での 事象Aが起こる確率 A B
6.
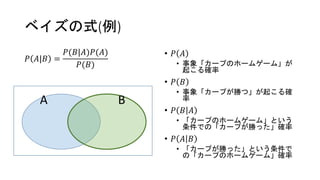
ベイズの式(例) 𝑃 𝐴|𝐵 = 𝑃(𝐵|𝐴)𝑃(𝐴) 𝑃(𝐵) •
𝑃 𝐴 • 事象「カープのホームゲーム」が 起こる確率 • 𝑃 𝐵 • 事象「カープが勝つ」が起こる確 率 • 𝑃 𝐵 𝐴 • 「カープのホームゲーム」という 条件での「カープが勝った」確率 • 𝑃 𝐴 𝐵 • 「カープが勝った」という条件で の「カープのホームゲーム」確率 A B
7.
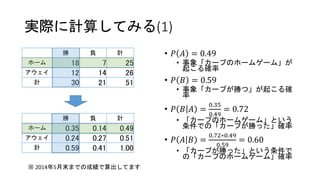
実際に計算してみる(1) 勝 負 計 ホーム
18 7 25 アウェイ 12 14 26 計 30 21 51 • 𝑃 𝐴 = 0.49 • 事象「カープのホームゲーム」が 起こる確率 • 𝑃 𝐵 = 0.59 • 事象「カープが勝つ」が起こる確 率 • 𝑃 𝐵 𝐴 = 0.35 0.49 = 0.72 • 「カープのホームゲーム」という 条件での「カープが勝った」確率 • 𝑃 𝐴 𝐵 = 0.72∗0.49 0.59 = 0.60 • 「カープが勝った」という条件で の「カープのホームゲーム」確率 勝 負 計 ホーム 0.35 0.14 0.49 アウェイ 0.24 0.27 0.51 計 0.59 0.41 1.00 ※ 2014年5月末までの成績で算出してます
8.
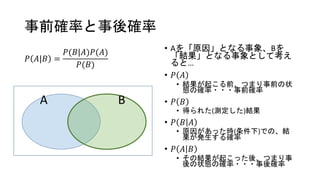
事前確率と事後確率 𝑃 𝐴|𝐵 = 𝑃(𝐵|𝐴)𝑃(𝐴) 𝑃(𝐵) •
Aを「原因」となる事象、Bを 「結果」となる事象として考え ると… • 𝑃 𝐴 • 結果が起こる前、つまり事前の状 態の確率・・・事前確率 • 𝑃 𝐵 • 得られた(測定した)結果 • 𝑃 𝐵 𝐴 • 原因があった時(条件下)での、結 果が発生する確率 • 𝑃 𝐴 𝐵 • その結果が起こった後、つまり事 後の状態の確率・・・事後確率 A B
9.
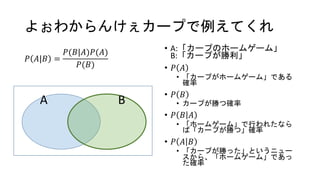
よぉわからんけぇカープで例えてくれ 𝑃 𝐴|𝐵 = 𝑃(𝐵|𝐴)𝑃(𝐴) 𝑃(𝐵) •
A:「カープのホームゲーム」 B:「カープが勝利」 • 𝑃 𝐴 • 「カープがホームゲーム」である 確率 • 𝑃 𝐵 • カープが勝つ確率 • 𝑃 𝐵 𝐴 • 「ホームゲーム」で行われたなら ば「カープが勝つ」確率 • 𝑃 𝐴 𝐵 • 「カープが勝った」というニュー スから、「ホームゲーム」であっ た確率 A B
10.
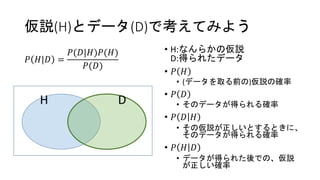
仮説(H)とデータ(D)で考えてみよう 𝑃 𝐻|𝐷 = 𝑃(𝐷|𝐻)𝑃(𝐻) 𝑃(𝐷) •
H:なんらかの仮説 D:得られたデータ • 𝑃 𝐻 • (データを取る前の)仮説の確率 • 𝑃 𝐷 • そのデータが得られる確率 • 𝑃 𝐷 𝐻 • その仮説が正しいとするときに、 そのデータが得られる確率 • 𝑃 𝐻 𝐷 • データが得られた後での、仮説 が正しい確率 H D
11.
よぉわからんけぇカープで(ry 𝑃 𝐻|𝐷 = 𝑃(𝐷|𝐻)𝑃(𝐻) 𝑃(𝐷) •
6月1日「カープが勝った」が、 この試合が「ホームゲーム」で ある確率は? • H:「6/1はホームゲーム」 D:「カープが勝つ」 • ホームゲームの確率は0.49 • 5月末カープの勝率は0.59 • 同ホームでの勝率は0.72 • 𝑃 𝐻 • ホームゲームが開催される確率 • 𝑃 𝐷 • カープの勝率 • 𝑃 𝐷 𝐻 • ホームでのカープの勝率 • 𝑃 𝐻 𝐷 • 「カープが勝った」ときのホーム ゲームである確率 • さあ計算してみよう! • (てかもう答え前に出してる)
12.
𝑃(𝐷|𝐻)について踏み込んでみよう • 仮説Hが正しいとした時に得られるデータ(D)の確率 • カープで(ry
: ホームゲーム(仮説H)である時の、5月末までの成績(デー タ)で得られるカープの勝率 • 言い換えれば… 得られたデータから、その仮説がどのくらい「もっともなのか」を表 す確率 • この6/1の勝利ゲームが「ホームゲーム」だった、と仮定しよう • ホームゲームは0.49だけ行われてる…からそのまま考えたらこのとおりだけど… • それじゃあ、ホームゲームで今のところ実際にどれだけ勝ってる?→0.72 • てことは、データからみたら、この仮定はこの確率くらい「もっともらしい」よ ね。 • この𝑃(𝐷|𝐻)は、尤度と言われる • 母数を含む仮説モデルの場合。データ分布とも。
13.
事前分布・事後分布・尤度 • ベイズの式は、以下のように表現できます • 事後確率
= 尤度 × 事前確率 基準化定数 • 基準化定数はさっきの分母P(D)のこと。 「全事象の確率の総和は1である」という制約から、そうなるように設定 …つまり「定数」です • 定数は定数なので、更に書き換えると… • [事後確率] ∝ [尤度]×[事前確率] • 事後確率は、尤度と事前確率をかけたものに比例する • つまりこの2つが重要となっている!
14.
ベイスファクターと モデル選択
15.
ホーム(H0)とアウェー(H1)で考えてみる • 仮説H0 :ホームゲーム 𝑃
𝐻0|𝐷 = 𝑃(𝐷|𝐻0)𝑃(𝐻0) 𝑃(𝐷) • さっきまで説明したものと同一 • 仮説H1 :アウェーゲーム 𝑃 𝐻1|𝐷 = 𝑃(𝐷|𝐻1)𝑃(𝐻1) 𝑃(𝐷) • 仮説「アウェー」になっている • それ以外は同一 どっちがいい仮説(モデル)なの?
16.
ベイズファクター • さっきの2つの仮説(モデル)について、事後確率を比べてみる (比を取る) 𝑃 𝐻1|𝐷 𝑃
𝐻0|𝐷 = 𝑃(𝐷|𝐻1)𝑃(𝐻1) 𝑃(𝐷|𝐻0)𝑃(𝐻0) = 𝑃(𝐷|𝐻1) 𝑃(𝐷|𝐻0) × 𝑃(𝐻1) 𝑃(𝐻0) • これは、[事後確率の比]=[尤度の比]×[事前確率の比]となります • この式を変形すると… • [尤度の比(ベイズファクター)] = [事後確率の比(事後オッズ)] [事前確率の比(事前オッズ)] • つまり、「2つの仮説(モデル)のもっともらしさを比較したもの」 がベイズファクター!
17.
なにがどうなればいいの? • ベイズファクターは簡単に言うと 「2つのモデルそれぞれのもっとらしさを比べた指標」 • 先の例で言うと… •
ベイズファクターが1より大きい → H1のモデルの方が(相対的に)もっともらしい、となる • ベイズファクターが1より小さい →H0 のモデルの方が(相対的に)もっともらしい、となる • ではカープで… • 𝑃 𝐻1|𝐷 𝑃 𝐻0|𝐷 = 0.47 0.72 =0.65 • これってどうなの?
18.
ベイズファクターの基準 • Kass &
Raftery(1995)の基準 • 基準というか「目安」 • 他にも有名なものが色々あり • 大切なのは、「有意水準」 みたいにズバッと切るもの ではないこと • そもそもそれに問題提起され て広がってきた側面もあるん ですしね・・・ BF 2logBF M0と比べた M1に対する判断 BF < 1 2logBF < 0 M0の方が良い 1 < BF < 3 0 < 2logBF <2 かろうじて優れてい る 3 < BF < 12 2 < 2logBF < 5 優れている 12 < BF < 150 5 < 2logBF < 10 かなり優れている 150 < BF 10 < 2logBF 非常に優れている 追記: 先の式で大きい方を分子に持ってきて、 その上でBFを見たほうがスムーズです。 あと基準(目安)はいろいろあります。
19.
ベイズファクターの問題点 • 2つのモデルの相対的比較である • ベイズファクターの式:
2つのモデルの「もっとらしさの比」 →数値の大小は、「2つを比較してどっちがいいか」にしかならない • 複数の指標を算出して、トータルで考えていくべし → この後紹介します • 計算が鬼(になることが多い) • 詳細は省略します… • パラメータが増えたり、事前分布などによって大変になるようです
20.
他のモデル指標も考えよう BIC • Bayes
information criterion(ベイズ情報量基準) 𝐵𝐼𝐶ℎ = −2 log 𝑃 𝐷 𝜃ℎ, 𝑀ℎ + 𝐾ℎ log 𝐼 𝜃ℎはモデル𝑀ℎのもとでのパラメータの最尤推定値 𝐾ℎはパラメータの数、𝐼はサンプルサイズ • 2つのモデルでそれぞれ算出された𝐵𝐼𝐶0と𝐵𝐼𝐶1の差が、 2logBFの近似となる • 算出が比較的カンタンなので、用いられることも多い • ただし、これはベイズファクターとは別物だということには注意
21.
他のモデル指標も考えよう DIC • Deviance
information criterion(偏差情報量基準) 𝐷𝐼𝐶ℎ = − 2 𝑇 𝑡=1 𝑇 log 𝑃 𝐷 𝜃ℎ (𝑡) , 𝑀ℎ + 2𝐾ℎ • 𝜃ℎ (𝑡) はパラメータ𝜃の事後分布から得られたT個の無作為標本 • この𝜃ℎ (𝑡) にマルコフ連鎖の連鎖要素をそのまま持ってこれる → MCMCとの相性がいい • 2つのモデルについてDICを算出し、値が小さいモデルのほうが データに対する当てはまりがいいと評価 • また、この指標も相対的な比較のための指標
22.
他のモデル指標も考えよう 事後予測p 値 • 事後分布が算出されるんだから、それに基づく分布から標本分 布をだせるんでね? →
事後予測分布 • そしたらこの分布と元データの分布は近くなるはずでね? → 指標化したのが事後予測p値 • 0.5に近ければモデルのデータへの当てはまりがいい • 2つのモデル比較ではなく、1つのモデルに対するデータへの当てはま りを見る指標 • ただし、実際に事後予測p値を用いるときには、ベイズファクターなど を補完するものとしたほうが無難とのこと
23.
そもそもなんでベイズファクターを…? • 帰無仮説の呪縛からの開放 • 伝統的な検定は「帰無仮説」と「対立仮説」という構図 •
でもベイズファクターなら「独立する2つのモデル(仮説)」を比較 ・・・別に「帰無仮説」なんてなくていい • 正規分布の呪縛からの開放 • このベイズの式には、事前分布を組み込んでいる • 「事前分布は正規分布でなくていい」 → より柔軟な統計モデルをあてはめて検討可能 ・・・ベイズ推定が利用される ※ この先は、あとのメンバーにお任せします
24.
さいごに ベイズファクターは2つの対立する 仮説について,データが支持 する程度の比を直接数量化 した量である。100倍支持するのであ れば十分であり,
1.04倍支持するのでは不十分だ,ということに は多くの 研究者が同意するだろう。しかしながら,文献中には 明 確なガイドラインはなく,また我々もそれを提供しな い。な ぜならば,恣意的な決定規則を与えたくはないか らだ。 p値についてのよく知られた警句を思い出すとよ い: 『神はp<.05をp<.06と等しく,そして同じくらい 強く愛してく ださる』 Rosnow & Rosenthal (1989)の一部より(岡田, 2014)
25.
参考資料(主なもののみ記載) • 涌井良幸「道具としてのベイズ時計」 • 入門書としてまず読んでみるにはちょうどいいです •
今回の前半部分を作成するのに参考にさせていただきました • 大久保街亜・岡田謙介「伝えるための心理統計」 • 本書の6章2節にベイズ統計学に関する説明があります • ベイズファクターを用いた具体例も記載してあります • 豊田秀樹(編)「マルコフ連鎖モンテカルロ法」 • 通称MCMC本。 • 本書の3章2節にベイズファクター及びモデル指標の説明があります • 岡田謙介 (2014). ベイズ統計による情報仮説の評価は分散分析にとって代 わるのか? 基礎心理学研究, 32(2), 223-231
Download








![事前分布・事後分布・尤度
• ベイズの式は、以下のように表現できます
• 事後確率 =
尤度 × 事前確率
基準化定数
• 基準化定数はさっきの分母P(D)のこと。
「全事象の確率の総和は1である」という制約から、そうなるように設定
…つまり「定数」です
• 定数は定数なので、更に書き換えると…
• [事後確率] ∝ [尤度]×[事前確率]
• 事後確率は、尤度と事前確率をかけたものに比例する
• つまりこの2つが重要となっている!](https://image.slidesharecdn.com/bayesfactor-140609034339-phpapp02/85/slide-13-320.jpg)


![ベイズファクター
• さっきの2つの仮説(モデル)について、事後確率を比べてみる
(比を取る)
𝑃 𝐻1|𝐷
𝑃 𝐻0|𝐷
=
𝑃(𝐷|𝐻1)𝑃(𝐻1)
𝑃(𝐷|𝐻0)𝑃(𝐻0)
=
𝑃(𝐷|𝐻1)
𝑃(𝐷|𝐻0)
×
𝑃(𝐻1)
𝑃(𝐻0)
• これは、[事後確率の比]=[尤度の比]×[事前確率の比]となります
• この式を変形すると…
• [尤度の比(ベイズファクター)] =
[事後確率の比(事後オッズ)]
[事前確率の比(事前オッズ)]
• つまり、「2つの仮説(モデル)のもっともらしさを比較したもの」
がベイズファクター!](https://image.slidesharecdn.com/bayesfactor-140609034339-phpapp02/85/slide-16-320.jpg)
































































