Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Tomoki Matsumoto
PPTX, PDF
8,460 views
WAICとWBICのご紹介
Introduction to WAIC and WBIC
Data & Analytics
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 25 times
1
/ 20
2
/ 20
3
/ 20
4
/ 20
5
/ 20
6
/ 20
7
/ 20
8
/ 20
9
/ 20
Most read
10
/ 20
Most read
11
/ 20
12
/ 20
13
/ 20
14
/ 20
15
/ 20
16
/ 20
17
/ 20
18
/ 20
19
/ 20
Most read
20
/ 20
More Related Content
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
これからの仮説検証・モデル評価
by
daiki hojo
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
PRML輪読#2
by
matsuolab
PDF
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
PDF
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
PDF
負の二項分布について
by
Hiroshi Shimizu
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
Stanコードの書き方 中級編
by
Hiroshi Shimizu
これからの仮説検証・モデル評価
by
daiki hojo
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PRML輪読#2
by
matsuolab
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
負の二項分布について
by
Hiroshi Shimizu
What's hot
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PDF
あなたの心にBridgeSampling
by
daiki hojo
PPTX
PRML第6章「カーネル法」
by
Keisuke Sugawara
PDF
Stanでガウス過程
by
Hiroshi Shimizu
PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
PPTX
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PPTX
(実験心理学徒だけど)一般化線形混合モデルを使ってみた
by
Takashi Yamane
PDF
StanとRでベイズ統計モデリング 11章 離散値をとるパラメータ
by
Miki Katsuragi
PDF
XGBoostからNGBoostまで
by
Tomoki Yoshida
PDF
PRML輪読#1
by
matsuolab
PDF
相互情報量を用いた独立性の検定
by
Joe Suzuki
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PDF
2 3.GLMの基礎
by
logics-of-blue
PPTX
ベイズファクターとモデル選択
by
kazutantan
PDF
Chapter9 一歩進んだ文法(前半)
by
itoyan110
PDF
RStanとShinyStanによるベイズ統計モデリング入門
by
Masaki Tsuda
PDF
PRML輪読#8
by
matsuolab
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
PDF
20180118 一般化線形モデル(glm)
by
Masakazu Shinoda
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
あなたの心にBridgeSampling
by
daiki hojo
PRML第6章「カーネル法」
by
Keisuke Sugawara
Stanでガウス過程
by
Hiroshi Shimizu
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
(実験心理学徒だけど)一般化線形混合モデルを使ってみた
by
Takashi Yamane
StanとRでベイズ統計モデリング 11章 離散値をとるパラメータ
by
Miki Katsuragi
XGBoostからNGBoostまで
by
Tomoki Yoshida
PRML輪読#1
by
matsuolab
相互情報量を用いた独立性の検定
by
Joe Suzuki
階層ベイズとWAIC
by
Hiroshi Shimizu
2 3.GLMの基礎
by
logics-of-blue
ベイズファクターとモデル選択
by
kazutantan
Chapter9 一歩進んだ文法(前半)
by
itoyan110
RStanとShinyStanによるベイズ統計モデリング入門
by
Masaki Tsuda
PRML輪読#8
by
matsuolab
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
20180118 一般化線形モデル(glm)
by
Masakazu Shinoda
Viewers also liked
PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
PDF
『予測にいかす統計モデリングの基本』の売上データの分析をトレースしてみた
by
. .
PDF
パターン認識 04 混合正規分布
by
sleipnir002
PDF
Stochastic Gradient MCMC
by
Kenta Oono
PDF
Replica exchange MCMC
by
. .
PDF
RでWAIC
by
Toru Imai
PDF
2015年9月18日 (GTC Japan 2015) 深層学習フレームワークChainerの導入と化合物活性予測への応用
by
Kenta Oono
PDF
Numacraw for r user(upload)
by
Teito Nakagawa
PDF
ベイジアン仮説検定
by
Tomoki Matsumoto
PDF
Stanで人類最強の男を決定する 2
by
Teito Nakagawa
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
『予測にいかす統計モデリングの基本』の売上データの分析をトレースしてみた
by
. .
パターン認識 04 混合正規分布
by
sleipnir002
Stochastic Gradient MCMC
by
Kenta Oono
Replica exchange MCMC
by
. .
RでWAIC
by
Toru Imai
2015年9月18日 (GTC Japan 2015) 深層学習フレームワークChainerの導入と化合物活性予測への応用
by
Kenta Oono
Numacraw for r user(upload)
by
Teito Nakagawa
ベイジアン仮説検定
by
Tomoki Matsumoto
Stanで人類最強の男を決定する 2
by
Teito Nakagawa
Similar to WAICとWBICのご紹介
PDF
ベイズ統計入門
by
Miyoshi Yuya
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
PRML輪読#10
by
matsuolab
PPTX
GEE(一般化推定方程式)の理論
by
Koichiro Gibo
PDF
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PPTX
model selection and information criteria part 1
by
Masafumi Enomoto
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PDF
「統計的学習理論」第1章
by
Kota Matsui
PPTX
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PDF
修士論文発表:「非負値行列分解における漸近的Bayes汎化誤差」
by
Naoki Hayashi
PDF
PRML 10.4 - 10.6
by
Akira Miyazawa
PDF
ベイズ入門
by
Zansa
PDF
PRML10-draft1002
by
Toshiyuki Shimono
PDF
PRML セミナー
by
sakaguchi050403
PDF
PRML輪講用資料10章(パターン認識と機械学習,近似推論法)
by
Toshiyuki Shimono
PDF
3.4
by
show you
PDF
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
PDF
ma99992010id512
by
matsushimalab
PDF
Infinite SVM [改] - ICML 2011 読み会
by
Shuyo Nakatani
ベイズ統計入門
by
Miyoshi Yuya
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PRML輪読#10
by
matsuolab
GEE(一般化推定方程式)の理論
by
Koichiro Gibo
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
model selection and information criteria part 1
by
Masafumi Enomoto
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
「統計的学習理論」第1章
by
Kota Matsui
Prml 1.3~1.6 ver3
by
Toshihiko Iio
修士論文発表:「非負値行列分解における漸近的Bayes汎化誤差」
by
Naoki Hayashi
PRML 10.4 - 10.6
by
Akira Miyazawa
ベイズ入門
by
Zansa
PRML10-draft1002
by
Toshiyuki Shimono
PRML セミナー
by
sakaguchi050403
PRML輪講用資料10章(パターン認識と機械学習,近似推論法)
by
Toshiyuki Shimono
3.4
by
show you
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
ma99992010id512
by
matsushimalab
Infinite SVM [改] - ICML 2011 読み会
by
Shuyo Nakatani
WAICとWBICのご紹介
1.
WAICとWBICのご紹介 にゃんとも
2.
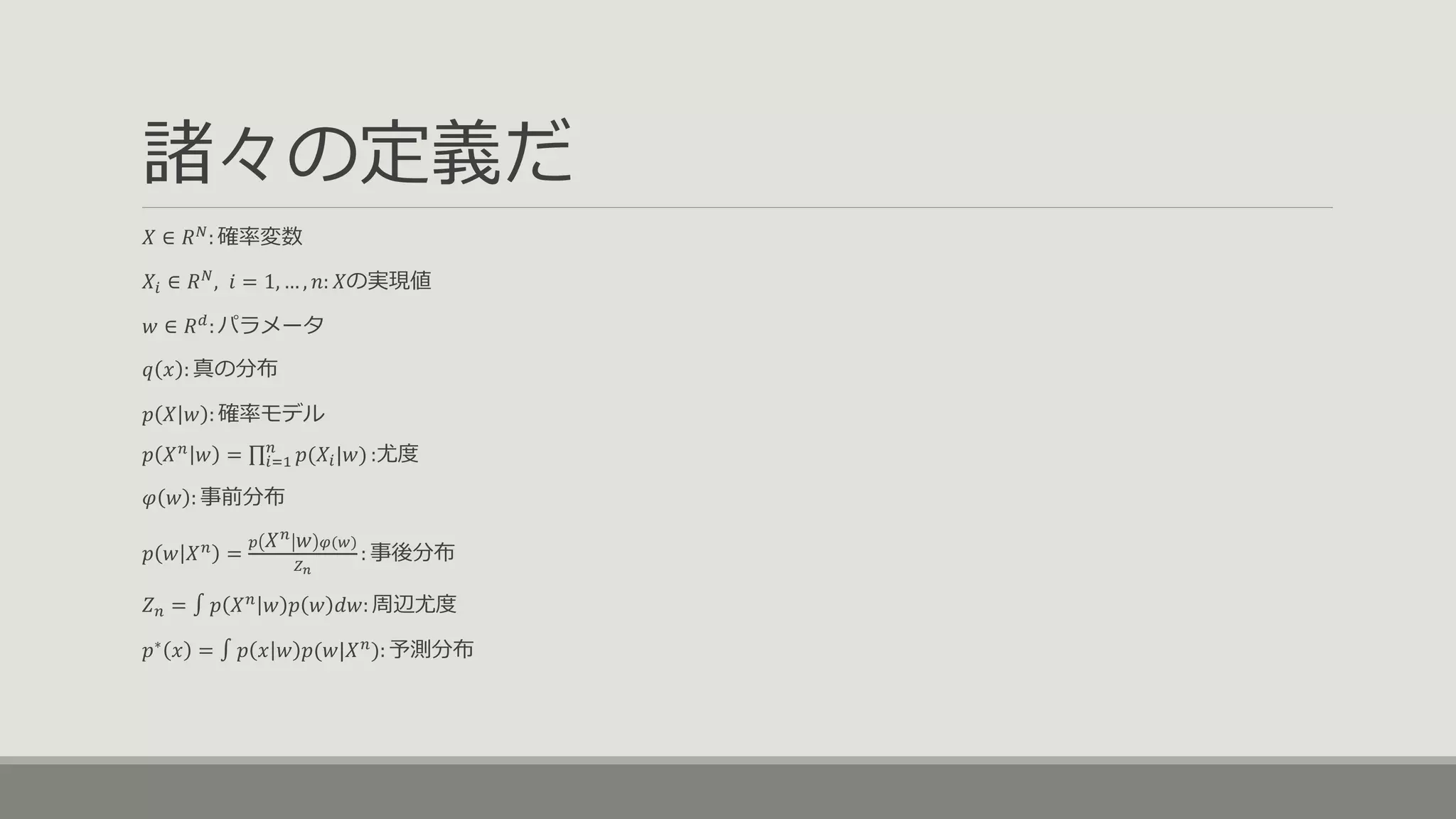
諸々の定義だ 𝑋 ∈ 𝑅
𝑁 : 確率変数 𝑋𝑖 ∈ 𝑅 𝑁 , 𝑖 = 1, … , 𝑛: 𝑋の実現値 𝑤 ∈ 𝑅 𝑑 : パラメータ 𝑞 𝑥 : 真の分布 𝑝 𝑋 𝑤 : 確率モデル 𝑝 𝑋 𝑛 𝑤 = 𝑖=1 𝑛 𝑝(𝑋𝑖|𝑤) :尤度 𝜑 𝑤 : 事前分布 𝑝 𝑤 𝑋 𝑛 = 𝑝 𝑋 𝑛 𝑤 𝜑(𝑤) 𝑍 𝑛 : 事後分布 𝑍 𝑛 = ∫ 𝑝 𝑋 𝑛 𝑤 𝑝 𝑤 𝑑𝑤: 周辺尤度 𝑝∗ 𝑥 = ∫ 𝑝 𝑥 𝑤 𝑝(𝑤|𝑋 𝑛 ): 予測分布
3.
諸々の定義だ(続) 注意 見慣れないかもしれませんが、事後分布は一般的に次のように書かれます: 𝑝 𝑤 𝑋
𝑛 = 𝑝 𝑋 𝑛 𝑤 𝛽 𝜑(𝑤) 𝑍 𝑛(𝛽) ここで𝛽は(0, ∞)に値をとる定数で逆温度と呼ばれます。 我々がよく知っているのは𝛽 = 1の時です。 以降ではこの逆温度を用いた表記をします。よって上記の事後分布に加え、前ページで お約束した𝑍 𝑛は𝛽を用いて次のように書かれます: 𝑍 𝑛(𝛽) = ∫ 𝑝 𝑋 𝑛 𝑤 𝛽 𝑝 𝑤 𝑑𝑤 この時、 𝑍 𝑛 𝛽 を分配関数と呼びます。
4.
ベイズ推論とは 真の確率分布𝑞 𝑥 は、おおよそ𝑝∗ (𝑥)であろう と推測すること。 実際にデータが発生した真の分布は誰にも分からない 予測分布は人間が決めた「確率モデル」と「事前分布」から導出される 予測分布は真の分布に対してどれほど妥当なものだろうか? 情報量基準
5.
情報量基準 ざっくり言うと 「得られたデータを使用して推定した“値や分布”の“真の値や真の分布”に対する 確からしさを測る指標」 “確からしさ”の基準としてよく用いられているのが 「汎化損失」 「自由エネルギー」 の2つ 予測分布の真の分布に対する「汎化損失」もしくは「自由エネルギーは」どんなものか? が気になる。
6.
自由エネルギー 分配関数から定義される 𝐹𝑛(𝛽) = − 1 𝛽 log
𝑍 𝑛 𝛽 のことを自由エネルギーと呼ぶ。 真の分布𝑞(𝑥)のエントロピー𝑆を次のように定義する: 𝑆 = −∫ 𝑞(𝑥) log 𝑞 𝑥 𝑑𝑥 サンプル𝑋 𝑛に対して定義される経験エントロピーを次のように定義する: 𝑆 𝑛 = − 1 𝑛 𝑖=1 𝑛 log 𝑞 𝑋𝑖 実際に計算できる
7.
自由エネルギー 定義より 𝐸[𝑆 𝑛]
= 𝑆 また定義より 𝐹𝑛 1 = − log 𝑍 𝑛 1 = log 𝑞(𝑋 𝑛) 𝑍 𝑛(𝑋 𝑛) 1 𝑞(𝑋 𝑛) = − log 𝑞 𝑋 𝑛 + log 𝑞(𝑋 𝑛) 𝑍 𝑛(𝑋 𝑛) = − log 𝑖=1 𝑛 𝑞 𝑋𝑖 + log 𝑞(𝑋 𝑛) 𝑍 𝑛(𝑋 𝑛) = − 𝑖=1 𝑛 log 𝑞(𝑋𝑖) + log 𝑞(𝑋 𝑛) 𝑍 𝑛(𝑋 𝑛) = 𝑛𝑆 𝑛 + log 𝑞(𝑋 𝑛) 𝑍 𝑛(𝑋 𝑛) これに期待値をとると 𝐸 𝐹𝑛 1 = 𝑛𝑆 + ∫ 𝑞(𝑥 𝑛 ) log 𝑞(𝑋 𝑛) 𝑍 𝑛(𝑋 𝑛) 𝑑𝑥 𝑛 ◦ この式の右辺第1項は真のエントロピーであり、どんなモデルを想定しても変化しない、常に固定された値 ◦ 右辺の第2項は𝑞 𝑥 𝑛 と𝑍 𝑥 𝑛 のカルバック・ライブラ距離 𝐹𝑛 1 の値が小さいほど、想定した分布が真の分布を平均的によく近似しているとみなせる
8.
自由エネルギー 実際に計算できるのは𝐹𝑛 1 の値であって𝐸
𝐹𝑛 1 の値ではない 𝐹𝑛 1 をみることでどの程度まで推測の精度について知ることができるのか? 自由エネルギーを使用したモデル選択では“真のモデルにより近いモデル”を 選択することができる
9.
汎化損失 予測分布から定義される 𝐺 𝑛 =
− log ∫ 𝑞 𝑥 log 𝑝∗ 𝑥 𝑑𝑥 のことを汎化損失と呼ぶ。 サンプル𝑋 𝑛 に対して定義される経験損失を次のように定義する: 𝑇𝑛 = − 1 𝑛 𝑖=1 𝑛 log 𝑝∗ 𝑋𝑖 真の分布𝑞(𝑥)のエントロピー𝑆を用いると次のように書ける: 𝐺 𝑛 = − ∫ 𝑞 𝑥 log 𝑝∗ 𝑥 𝑑𝑥 = ∫ 𝑞 𝑥 log 𝑞(𝑥) 𝑝∗(𝑥) 1 𝑞(𝑥) 𝑑𝑥 = − ∫ 𝑞 𝑥 log 𝑞 𝑥 𝑑𝑥 + ∫ 𝑞 𝑥 log 𝑞(𝑥) 𝑝∗(𝑥) 𝑑𝑥 = 𝑆 + log ∫ 𝑞 𝑥 log 𝑞(𝑥) 𝑝∗(𝑥) 𝑑𝑥 ◦ 右辺の第2項は真の分布と推測した分布のカルバック・ライブラ距離 𝐺 𝑛の値が小さいほど、想定した分布が真の分布を平均的によく近似しているとみなせる 真の分布が不明だから 実際に計算できない 実際に計算できる
10.
汎化損失 真の分布𝑞 𝑥 が不明であり、真の分布についての期待値計算が必要なため 𝐺
𝑛を直接計算することは出来ない 一方で経験損失𝑇𝑛は計算することができる 𝐺 𝑛と𝑇𝑛は異なるものであるが、𝑇𝑛から𝐺 𝑛の値を推測することは出来ないだろうか? 汎化損失を使用したモデル選択では“予測精度の高いモデル”を選択することができる
11.
事後分布が正規分布で近似できると は? 平均対数損失関数を次のように定義する: 𝐿 𝑤 =
−log ∫ 𝑞 𝑥 log 𝑝 𝑋 𝑤 𝑑𝑥 経験対数損失関数を次のように定義する: 𝐿 𝑛 𝑤 = − 𝑖=1 𝑛 log 𝑝(𝑋𝑖|𝑤) このとき事後分布が正規分布で近似できる条件は以下の3つ: (1) 𝐿 𝑤 を最小にするパラメータが1つ (2) 𝐿 𝑤 の2回偏微分を要素としてもつ行列 𝐽 が正則 (3) データ数𝑛が非常に大きい
12.
事後分布が正規分布で近似できると は? このとき事後分布は 𝐿 𝑛
𝑤 = − 𝑖=1 𝑛 log 𝑝(𝑋𝑖|𝑤) を最小にする点、 つまり最尤推定量 𝑤 を中心にして、分散共分散行列が 𝑛𝐽 −1 の正規分布に従う: p w Xn ≈ 𝑁( 𝑤, 𝑛𝐽 −1)
13.
赤池情報量基準(AIC) 確からしさとして「汎化損失」を用いた指標 事後分布が正規分布で近似できるとき、汎化損失𝐺 𝑛と平均対数損失𝐿( 𝑤)は𝑜
𝑝 1 𝑛 のオーダーで一致する。 AICを以下のように定義する: このとき𝐸 AIC = 𝐸[𝐿( 𝑤)]+ 𝑜 𝑝 1 𝑛 AIC = − 1 𝑛 𝑖=1 𝑛 log 𝑝(𝑋𝑖| 𝑤) + 𝑑 𝑛
14.
ベイズ情報量基準(BIC) 確からしさとして「自由エネルギー」を用いた指標 事後分布が正規分布で近似できるとき、自由エネルギー 𝐹𝑛(1) は以下のように計算でき る: 𝐹𝑛
1 = 𝐿 𝑛 𝑤 + 𝑑 2𝛽 log 𝑛 + 𝑑 2𝛽 log 𝛽 2𝜋 + 1 2𝛽 log det(𝛻2 𝐿(𝑤)) + 𝑜 𝑝(1) ここでlog 𝑛 以上のオーダーの項だけを抜き出し、 𝑤 として最尤推定量を用いたものが BICである: BIC = − 𝑖=1 𝑛 log 𝑝(𝑋𝑖| 𝑤) + 𝑑 2 log 𝑛
15.
AICとBICの欠点 先に述べたように、AICとBICが理論的に正しく“確からしさ”を測れるモデルは “正規分布で近似できる”場合のみ ◦ この制約はかなり強い ◦ 世の中、なんでも正規分布で近似できるほど単純じゃない じゃあ、統計モデルが正規近似できないときはどうすればいいの???
16.
Prof. Watanabeは神である 渡辺澄夫先生(東工大)は2010年、ベイズ統計学の唯一の理論であるWAICを導出した AICが適用できるモデルには制約があったが、 WAIC
は真の分布、確率モデル、 事前分 布がどのような場合でも使う ことができる そしてその2年後、BAICを導出した BICが適用できるモデルには制約があったが、 WBIC は真の分布、確率モデル、 事前分 布がどのような場合でも使う ことができる 全ベイジアンは渡辺先生に足を向けて寝てはならない
17.
WAICとWBICを考える上での仮定 ・パラメータの集合とその元を𝑊, 𝑤 ∈
𝑊とする ・平均対数損失関数𝐿 𝑤 を最小にするパラメータ空間とその元を𝑊0, 𝑤0 ∈ 𝑊0とする。 ・対数尤度比関数を次のように定義する: 𝑓 𝑥, 𝑤0, 𝑤 = log 𝑝(𝑥|𝑤0) 𝑝(𝑥|𝑤) このとき、対数尤度比関数が相対的に有限な分散をもつとは次のことをいう; 𝐸 𝑋 𝑓 𝑋, 𝑤0, 𝑤 ≧ 𝑐0 𝐸 𝑋[𝑓 𝑋, 𝑤0, 𝑤 2 ], 𝑐0 > 0 WAICとWBICはこの対数尤度比関数が相対的に有限な分散をもつことを仮定している
18.
WAIC 汎関数分散を以下のように定義する: 𝑉𝑛 = 𝑖=1 𝑛 {𝐸
𝑤 log 𝑝 𝑋𝑖 𝑤 2 − 𝐸 𝑤 log 𝑝 𝑋𝑖 𝑤 2} この時、WAICは以下のようになる: 汎化損失𝐺 𝑛の期待値はWAICの期待値と漸近的に同じ値をとる: 𝐸[𝐺 𝑛] = 𝐸 WAIC + 𝑜 1 𝑛2 実際に計算できる WAIC = 𝑇𝑛 + 𝛽𝑉𝑛 𝑛
19.
WBIC WBICは以下のようになる: このとき自由エネルギーとWBICは log 𝑛
のオーダーで同じ漸近挙動をもつ 事後分布に対する 𝑛𝐿 𝑛 𝑤 の期待値 MCMCドローを使用し て実際に計算できる WBIC = ∫ 𝑛𝐿 𝑛 𝑤 𝑖=1 𝑛 𝑝 𝑋𝑖 𝑤 𝛽 𝜑 𝑤 𝑑𝑤 ∫ 𝑖=1 𝑛 𝑝 𝑋𝑖 𝑤 𝛽 𝜑 𝑤 𝑑𝑤 ここで 𝛽 = 1 log 𝑛
20.
WAIC・WBICをもっと深く知るた めに 最終的に導出されたWAICとWBICは非常に簡単な式でした でも、この式の導出を理解するにはそこそこ数学の知識が必要です ◦ 集合論 ◦ 測度論(確率論) ◦
関数解析 ◦ 多様体 みんなも勉強した方がいいと思う((≡゚♀゚≡))
Download






![自由エネルギー
定義より 𝐸[𝑆 𝑛] = 𝑆
また定義より
𝐹𝑛 1 = − log 𝑍 𝑛 1 = log
𝑞(𝑋 𝑛)
𝑍 𝑛(𝑋 𝑛)
1
𝑞(𝑋 𝑛)
= − log 𝑞 𝑋 𝑛
+ log
𝑞(𝑋 𝑛)
𝑍 𝑛(𝑋 𝑛)
= − log 𝑖=1
𝑛
𝑞 𝑋𝑖 + log
𝑞(𝑋 𝑛)
𝑍 𝑛(𝑋 𝑛)
= − 𝑖=1
𝑛
log 𝑞(𝑋𝑖) + log
𝑞(𝑋 𝑛)
𝑍 𝑛(𝑋 𝑛)
= 𝑛𝑆 𝑛 + log
𝑞(𝑋 𝑛)
𝑍 𝑛(𝑋 𝑛)
これに期待値をとると
𝐸 𝐹𝑛 1 = 𝑛𝑆 + ∫ 𝑞(𝑥 𝑛
) log
𝑞(𝑋 𝑛)
𝑍 𝑛(𝑋 𝑛)
𝑑𝑥 𝑛
◦ この式の右辺第1項は真のエントロピーであり、どんなモデルを想定しても変化しない、常に固定された値
◦ 右辺の第2項は𝑞 𝑥 𝑛
と𝑍 𝑥 𝑛
のカルバック・ライブラ距離
𝐹𝑛 1 の値が小さいほど、想定した分布が真の分布を平均的によく近似しているとみなせる](https://image.slidesharecdn.com/waicwbic-170125084304/75/WAIC-WBIC-7-2048.jpg)





![赤池情報量基準(AIC)
確からしさとして「汎化損失」を用いた指標
事後分布が正規分布で近似できるとき、汎化損失𝐺 𝑛と平均対数損失𝐿( 𝑤)は𝑜 𝑝
1
𝑛
のオーダーで一致する。
AICを以下のように定義する:
このとき𝐸 AIC = 𝐸[𝐿( 𝑤)]+ 𝑜 𝑝
1
𝑛
AIC = −
1
𝑛
𝑖=1
𝑛
log 𝑝(𝑋𝑖| 𝑤) +
𝑑
𝑛](https://image.slidesharecdn.com/waicwbic-170125084304/75/WAIC-WBIC-13-2048.jpg)



![WAICとWBICを考える上での仮定
・パラメータの集合とその元を𝑊, 𝑤 ∈ 𝑊とする
・平均対数損失関数𝐿 𝑤 を最小にするパラメータ空間とその元を𝑊0, 𝑤0 ∈ 𝑊0とする。
・対数尤度比関数を次のように定義する:
𝑓 𝑥, 𝑤0, 𝑤 = log
𝑝(𝑥|𝑤0)
𝑝(𝑥|𝑤)
このとき、対数尤度比関数が相対的に有限な分散をもつとは次のことをいう;
𝐸 𝑋 𝑓 𝑋, 𝑤0, 𝑤 ≧ 𝑐0 𝐸 𝑋[𝑓 𝑋, 𝑤0, 𝑤 2
], 𝑐0 > 0
WAICとWBICはこの対数尤度比関数が相対的に有限な分散をもつことを仮定している](https://image.slidesharecdn.com/waicwbic-170125084304/75/WAIC-WBIC-17-2048.jpg)
![WAIC
汎関数分散を以下のように定義する:
𝑉𝑛 = 𝑖=1
𝑛
{𝐸 𝑤 log 𝑝 𝑋𝑖 𝑤 2 − 𝐸 𝑤 log 𝑝 𝑋𝑖 𝑤 2}
この時、WAICは以下のようになる:
汎化損失𝐺 𝑛の期待値はWAICの期待値と漸近的に同じ値をとる:
𝐸[𝐺 𝑛] = 𝐸 WAIC + 𝑜
1
𝑛2
実際に計算できる
WAIC = 𝑇𝑛 +
𝛽𝑉𝑛
𝑛](https://image.slidesharecdn.com/waicwbic-170125084304/75/WAIC-WBIC-18-2048.jpg)















![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)











































![Infinite SVM [改] - ICML 2011 読み会](https://cdn.slidesharecdn.com/ss_thumbnails/isvm-icml11a-110719050617-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)