Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Hiroshi Shimizu
PPTX, PDF
59,805 views
マルチレベルモデル講習会 実践編
東洋大学で行われたマルチレベル講習会の実践編です。SPSSとHADの使い方を解説しています。
Data & Analytics
◦
Read more
16
Save
Share
Embed
Embed presentation
Download
Downloaded 759 times
1
/ 78
2
/ 78
3
/ 78
4
/ 78
5
/ 78
6
/ 78
7
/ 78
8
/ 78
9
/ 78
10
/ 78
11
/ 78
12
/ 78
13
/ 78
14
/ 78
15
/ 78
16
/ 78
17
/ 78
18
/ 78
19
/ 78
20
/ 78
21
/ 78
22
/ 78
23
/ 78
24
/ 78
25
/ 78
26
/ 78
27
/ 78
28
/ 78
29
/ 78
30
/ 78
31
/ 78
32
/ 78
33
/ 78
34
/ 78
35
/ 78
36
/ 78
37
/ 78
38
/ 78
39
/ 78
40
/ 78
41
/ 78
42
/ 78
43
/ 78
44
/ 78
45
/ 78
46
/ 78
47
/ 78
48
/ 78
Most read
49
/ 78
50
/ 78
51
/ 78
52
/ 78
53
/ 78
54
/ 78
55
/ 78
56
/ 78
57
/ 78
58
/ 78
Most read
59
/ 78
60
/ 78
Most read
61
/ 78
62
/ 78
63
/ 78
64
/ 78
65
/ 78
66
/ 78
67
/ 78
68
/ 78
69
/ 78
70
/ 78
71
/ 78
72
/ 78
73
/ 78
74
/ 78
75
/ 78
76
/ 78
77
/ 78
78
/ 78
More Related Content
PPTX
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
PPTX
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
PDF
社会心理学とGlmm
by
Hiroshi Shimizu
PDF
2012-1110「マルチレベルモデルのはなし」(censored)
by
Mizumoto Atsushi
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
PDF
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
PDF
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
PDF
混合モデルを使って反復測定分散分析をする
by
Masaru Tokuoka
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
社会心理学とGlmm
by
Hiroshi Shimizu
2012-1110「マルチレベルモデルのはなし」(censored)
by
Mizumoto Atsushi
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
混合モデルを使って反復測定分散分析をする
by
Masaru Tokuoka
What's hot
PDF
媒介分析について
by
Hiroshi Shimizu
PDF
SEMを用いた縦断データの解析 潜在曲線モデル
by
Masaru Tokuoka
PDF
第4回DARM勉強会 (多母集団同時分析)
by
Masaru Tokuoka
PDF
Mplusの使い方 初級編
by
Hiroshi Shimizu
PPTX
重回帰分析で交互作用効果
by
Makoto Hirakawa
PDF
Mplusの使い方 中級編
by
Hiroshi Shimizu
PDF
RでMplusがもっと便利にーmplusAutomationパッケージー #Hiroshimar05
by
Masaru Tokuoka
PPTX
項目反応理論による尺度運用
by
Yoshitake Takebayashi
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
DOCX
RによるBox-Cox変換
by
wada, kazumi
PPTX
心理学におけるオープンサイエンス入門(OSF&PsyArXiv編)
by
daiki hojo
PDF
エクセルで統計分析2 HADの使い方
by
Hiroshi Shimizu
PPTX
SEMのやり方 改訂版
by
Shota Yuasa
PDF
一般化線形混合モデル入門の入門
by
Yu Tamura
PPTX
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
PDF
2 4.devianceと尤度比検定
by
logics-of-blue
PDF
潜在クラス分析
by
Yoshitake Takebayashi
PDF
Rで潜在ランク分析
by
Hiroshi Shimizu
PDF
エクセルで統計分析4 因子分析のやり方
by
Hiroshi Shimizu
PPTX
GEE(一般化推定方程式)の理論
by
Koichiro Gibo
媒介分析について
by
Hiroshi Shimizu
SEMを用いた縦断データの解析 潜在曲線モデル
by
Masaru Tokuoka
第4回DARM勉強会 (多母集団同時分析)
by
Masaru Tokuoka
Mplusの使い方 初級編
by
Hiroshi Shimizu
重回帰分析で交互作用効果
by
Makoto Hirakawa
Mplusの使い方 中級編
by
Hiroshi Shimizu
RでMplusがもっと便利にーmplusAutomationパッケージー #Hiroshimar05
by
Masaru Tokuoka
項目反応理論による尺度運用
by
Yoshitake Takebayashi
Stanコードの書き方 中級編
by
Hiroshi Shimizu
RによるBox-Cox変換
by
wada, kazumi
心理学におけるオープンサイエンス入門(OSF&PsyArXiv編)
by
daiki hojo
エクセルで統計分析2 HADの使い方
by
Hiroshi Shimizu
SEMのやり方 改訂版
by
Shota Yuasa
一般化線形混合モデル入門の入門
by
Yu Tamura
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
2 4.devianceと尤度比検定
by
logics-of-blue
潜在クラス分析
by
Yoshitake Takebayashi
Rで潜在ランク分析
by
Hiroshi Shimizu
エクセルで統計分析4 因子分析のやり方
by
Hiroshi Shimizu
GEE(一般化推定方程式)の理論
by
Koichiro Gibo
Similar to マルチレベルモデル講習会 実践編
PDF
2017jsyap seminar asano
by
Ryosuke Asano
PPTX
日本教育心理学会2016WSスライド
by
考司 小杉
PPTX
HCGシンポジウム2018;心理学における新しい統計学との付き合い方
by
考司 小杉
PPTX
HCG20181212
by
考司 小杉
PDF
エクセルで統計分析3 回帰分析のやり方
by
Hiroshi Shimizu
PPTX
要因計画データに対するベイズ推定アプローチ
by
Takashi Yamane
PDF
データ入力が終わってから分析前にすること
by
Masaru Tokuoka
PDF
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
PDF
第2回DARM勉強会
by
Masaru Tokuoka
PDF
2011jssp ws asano
by
Ryosuke Asano
PDF
ベイズ主義による研究の報告方法
by
Masaru Tokuoka
PDF
jsish20130308_hiroe
by
Takanori Hiroe
PDF
2015jpa sympo asano
by
Ryosuke Asano
PDF
明日から読める無作為化比較試験: 行動療法研究に求められる統計学
by
Yasuyuki Okumura
PDF
第2回DARM勉強会.preacherによるmoderatorの検討
by
Masaru Tokuoka
PDF
有意性と効果量について しっかり考えてみよう
by
Ken Urano
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
PPTX
(実験心理学徒だけど)一般化線形混合モデルを使ってみた
by
Takashi Yamane
PDF
Letmetho20151219key
by
youwatari
2017jsyap seminar asano
by
Ryosuke Asano
日本教育心理学会2016WSスライド
by
考司 小杉
HCGシンポジウム2018;心理学における新しい統計学との付き合い方
by
考司 小杉
HCG20181212
by
考司 小杉
エクセルで統計分析3 回帰分析のやり方
by
Hiroshi Shimizu
要因計画データに対するベイズ推定アプローチ
by
Takashi Yamane
データ入力が終わってから分析前にすること
by
Masaru Tokuoka
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
第2回DARM勉強会
by
Masaru Tokuoka
2011jssp ws asano
by
Ryosuke Asano
ベイズ主義による研究の報告方法
by
Masaru Tokuoka
jsish20130308_hiroe
by
Takanori Hiroe
2015jpa sympo asano
by
Ryosuke Asano
明日から読める無作為化比較試験: 行動療法研究に求められる統計学
by
Yasuyuki Okumura
第2回DARM勉強会.preacherによるmoderatorの検討
by
Masaru Tokuoka
有意性と効果量について しっかり考えてみよう
by
Ken Urano
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
(実験心理学徒だけど)一般化線形混合モデルを使ってみた
by
Takashi Yamane
Letmetho20151219key
by
youwatari
More from Hiroshi Shimizu
PDF
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
PDF
Stanでガウス過程
by
Hiroshi Shimizu
PDF
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
PDF
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
PDF
SapporoR#6 初心者セッションスライド
by
Hiroshi Shimizu
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PDF
Tokyo r53
by
Hiroshi Shimizu
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PDF
glmmstanパッケージを作ってみた
by
Hiroshi Shimizu
PDF
負の二項分布について
by
Hiroshi Shimizu
PPTX
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
PPTX
Latent rank theory
by
Hiroshi Shimizu
PDF
エクセルでテキストマイニング TTM2HADの使い方
by
Hiroshi Shimizu
PPTX
Excelでも統計分析 HADについて SappoRo.R#3
by
Hiroshi Shimizu
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
Stanでガウス過程
by
Hiroshi Shimizu
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
SapporoR#6 初心者セッションスライド
by
Hiroshi Shimizu
Stan超初心者入門
by
Hiroshi Shimizu
Tokyo r53
by
Hiroshi Shimizu
階層ベイズとWAIC
by
Hiroshi Shimizu
glmmstanパッケージを作ってみた
by
Hiroshi Shimizu
負の二項分布について
by
Hiroshi Shimizu
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
Latent rank theory
by
Hiroshi Shimizu
エクセルでテキストマイニング TTM2HADの使い方
by
Hiroshi Shimizu
Excelでも統計分析 HADについて SappoRo.R#3
by
Hiroshi Shimizu
マルチレベルモデル講習会 実践編
1.
マルチレベルモデル講習会 実践編 清水裕士 広島大学大学院総合科学研究科 http://norimune.net 1
2.
自己紹介 • 清水裕士 – 所属:広島大学
大学院総合科学研究科 • 助教 – 専門:社会心理学 グループダイナミクス • 親密な対人関係におけるソーシャル・サポート • 社会規範・道徳の進化 • 連絡先 – E-mail:simizu706(at)hiroshima-u.ac.jp – Webサイト:http://norimune.net – Twitter: @simizu706
3.
実践編 3
4.
SPSSによる分析の流れ 4
5.
HLMの分析の流れ • グループ内類似性の評価 – 級内相関係数の算出 •
レベル1・レベル2の変数の用意 – レベル1の変数→集団平均で中心化を行う • →各集団の平均を得点から引くこと – レベル2の変数→全体平均で中心化を行う • HLMを行うソフトに変数をセット – モデリングをして推定値を算出 • 適合度などを参考に、モデルを修正 5
6.
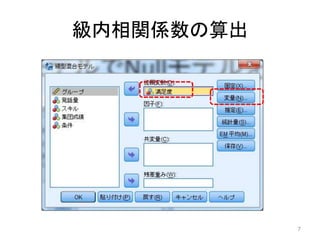
級内相関係数の算出 「分析」→ 「混合モデル」 6
7.
級内相関係数の算出 7
8.
「変量をクリック」 「被験者のグループ化」のところにグループ変数を指定 8 共分散タイプ:無構造 「定数項を含める」をチェック
9.
推定方法を最尤法にしておく • 「推定」をクリック – 今回は最尤法を使う –
どちらでも大きな違いはない – 他はいじらなくていい 9
10.
級内相関係数の算出 • 共分散パラメータを見る – 残差・・・集団内変動 –
切片・・・集団間変動 – 級内相関 = 0.349 / (0.637 + 0.349) = 0.354 10
11.
説明変数の準備 • 個人レベルの変数 – 集団平均値を算出 •
「グループ集計」で,グループごとの平均値を算出 – 集団平均で中心化 • 上で計算した集団平均値をデータから引く • 集団レベルの変数 – 全体平均で中心化 • 平均値を計算して,データから引く 11
12.
集団平均値の計算 12
13.
集団平均で中心化 13
14.
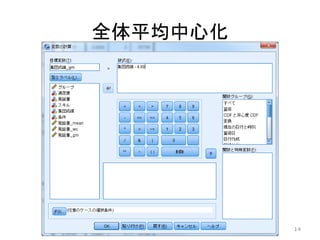
全体平均中心化 14
15.
出来上がったデータセット 15
16.
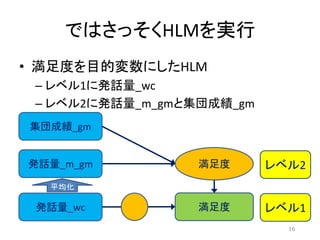
ではさっそくHLMを実行 • 満足度を目的変数にしたHLM – レベル1に発話量_wc –
レベル2に発話量_m_gmと集団成績_gm 16 発話量_wc 集団成績_gm 満足度 満足度 レベル2 レベル1 発話量_m_gm 平均化
17.
共変量に説明変数を入れて「固定」を押す 17
18.
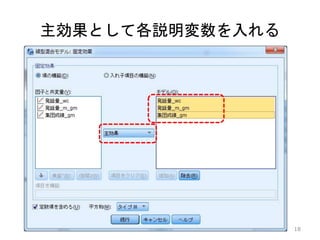
主効果として各説明変数を入れる 18
19.
「変量」を押して変量効果を指定 19
20.
出力のオプション • 「統計量」をクリック – パラメータ推定値 –
共分散パラメータの検定 • は最低限でも出力する • ここまで出来たら,「OK」 – 分析結果が出力される 20
21.
出力1:情報量基準 • モデルの適合度 – AIC・・・複雑なモデルを好む –
BIC・・・倹約的なモデルを好む – AICC・・・中間ぐらい 21
22.
固定効果 • 推定値 – いわゆる,回帰係数 –
dfは自由度 • 小数があるのは,Satterthwaiteの補正をしているため 22
23.
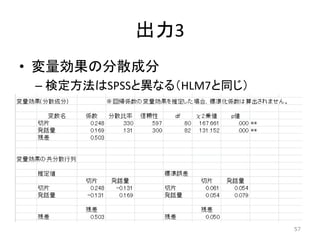
変量効果の分散成分 • 変量効果の分散と共分散 – UN(1,1)は切片の分散 –
UN(2,2)は回帰係数の分散 – UN(2,1)は切片と回帰係数の共分散 • ゾロ目は分散,それ以外は共分散 23
24.
レベル間交互作用 24
25.
レベル間交互作用 25
26.
単純効果分析 • 交互作用効果が出たら単純効果が知りたい – 分散分析や回帰分析と同じ –
説明変数が連続変量の場合は,±1SDの効果を 見ることが多い • あくまで,多い,というだけで,そうすべきというわけで はない • SPSSでは単純効果の検定ができない – PreacherのWebサイトにパラメータを入力 – http://www.quantpsy.org/interact/index.html 26
27.
PreacherのWebサイト 27
28.
グラフも出力してくれる 28
29.
HADによる分析 29
30.
HADとは • 清水が作ったExcelのVBAで動くプログラム – Excelのバージョンは2007以降に対応 –
Macにも対応(Excel for Mac2011以降) • WinとMacを同じファイルで使いまわせる • 主に心理統計分析ができる – 大抵の心理統計分析は可能 • データハンドリング,統計的検定,多変量解析など – マルチレベル分析もできる • 階層線形モデルや,マルチレベルSEMなど 30
31.
HADとは • 無償のソフトウェアです – 利用は無償です –
清水のブログからからダウンロードできます • http://norimune.net/had • 何度でもダウンロードできます • 自由なソフトウェアです – ソースコードを自由に閲覧・変更することができます • 第三者への配布も自由です – ライセンス • GNU General Public License(GPL)に則ってます • ライセンスについては「HADとは」 ( http://norimune.net/had)のページを参照してください。 31
32.
HLMにおけるHADの特徴 • フリーソフトウェアである – SPSS(とお金)がなくても,Excelがあれば使える •
単純効果分析ができる – 簡単に単純効果とグラフの出力ができる • 頑健標準誤差を出力できる – SPSSは出力してくれない • 最尤法しか対応していない – 制限付き最尤法は現状,利用できない – 今後搭載の可能性も0ではない 32
33.
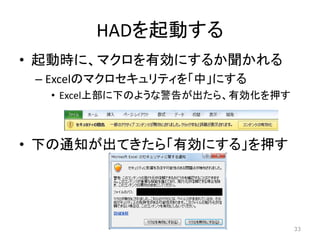
HADを起動する • 起動時に、マクロを有効にするか聞かれる – Excelのマクロセキュリティを「中」にする •
Excel上部に下のような警告が出たら、有効化を押す • 下の通知が出てきたら「有効にする」を押す 33
34.
HAD12以降の注意点 • HAD12からはExcelのソルバーを使っている – ソルバー:Excelに入っているアドイン •
最初に起動したときにエラーがでる場合 – コンパイルエラーというのが出ることがある – その場合は,HADを一度閉じて,もう一度起動する。 すると,ソルバーが入っていれば普通に使うことがで きる • ソルバーがない場合 – ソルバーオフバージョンを使う必要がある 34
35.
HADを起動 • B列にグループを識別する変数を入れる 35
36.
モデリングシートに読み込む • データの読み込み – セットできたら「データ読み込み」ボタン –
データをチェックして、以下の場合に警告 • データセットに空白がある場合 • 欠損値記号以外の文字列がある場合 – 数式エラーの場合は、それらを欠損値に変換できる • データが保存されているわけではない – 変数名の読み込みと設定を読み込むだけ – データセットを変えると分析結果も変わる 36
37.
モデリングシートの機能 基本的な 統計分析 新しい変数の作成 多変量解析 変数情報の設定 データセット選択 使用変数の指定 37
38.
• モデリングシートの9行目に変数名を指定 • 3通りの指定方法がある –
自分でセルに入力する → コピペでもよい – 「選択セルを使用」ボタンを押す – GUIを使う 分析に使用する変数を指定 ここに入力 ID変数はB列に入力する 38
39.
GUIを使用する • 「使用変数」ボタンを押すとGUIが立ち上がる • 追加と削除で指定 –
ShiftやCtrlを使えば複数の 変数を選択できる • 変数の登録 – よく使う変数のセットは登録 しておくと便利 – すぐにセットを呼び出せる 39
40.
HADで基礎統計分析 • 使用変数を指定して,「分析」ボタンを押す ヒストグラム 40
41.
級内相関係数の算出 • 使用変数を指定して,「分析」ボタンを押す – 級内相関係数を チェック •
OKボタンを押す 41
42.
級内相関係数の算出 • 推定値と信頼区間,検定統計量,p値を出力 42
43.
回帰分析の方法 モデリングスペース 43
44.
回帰分析の方法 • 「回帰分析」のラジオボタンをクリック – 回帰分析用のモデリングスペースが表示される –
その中の「回帰分析」を選択 • 先に目的変数,あとで説明変数を指定 – 変数を選択して,「目的変数を投入」を押す • ここでは満足度 – 「主効果を全投入」を押すと,自動的に説明変数 がモデルに投入される 44
45.
回帰分析の方法 • 「分析実行」を押す – 「Reg」というシートで結果が出力される 45
46.
交互作用も簡単にできる • 交互作用項は自動的に中心化して作成 46
47.
ステップごとの結果 47
48.
単純効果分析も出力する 48
49.
HLMの方法 • モデリングシートで「階層線形モデル」を選択 – HLM用のモデリングスペースに切り替わる 今回はSPSSと結果を一致させるため 頑健標準誤差はオフにしておく 49
50.
実行を押せばHLMができる • 切片の集団間変動だけを仮定したモデル – 「HLM」というシートに出力される HADのHLMは,デフォルトで説明 変数は全体平均で中心化される 50
51.
説明変数の中心化 • 「変数の作成」ボタンから行う – 「変数の作成」を押して,「尺度変換」タブの「集団 平均で中心化する」をチェック •
分析上で中心化を行う – 「レベル1変数を集団平均で中心化」をチェックす ると,自動的に中心化される – 説明変数は自動的に全体平均で中心化される • この設定をオフにすることもできる 51
52.
説明変数の中心化 52
53.
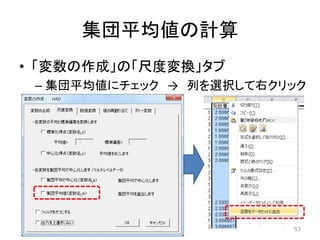
集団平均値の計算 • 「変数の作成」の「尺度変換」タブ – 集団平均値にチェック
→ 列を選択して右クリック 53
54.
回帰係数の集団間変動 • 「変量効果→」にレベル1変数を指定する 54
55.
出力1 • モデル適合度 – 情報量基準を参照する –
回帰係数の集団間変動を仮定すると,R2乗など の計算はできなくなる 55
56.
出力2 • 固定効果 – 集団平均で中心化した変数・・・wcがつく –
全体平均で中心化した変数・・・gmがつく 56
57.
出力3 • 変量効果の分散成分 – 検定方法はSPSSと異なる(HLM7と同じ) 57
58.
交互作用項の投入 • 交互作用項を「*」を挟んで投入する 58
59.
交互作用項の投入 • 「交互作用を全投入」ボタン – 説明変数すべての交互作用項が投入される •
Shiftキー+「交互作用を全投入」ボタン – 交互作用項を作りたい説明変数を選択した状態 で,Shiftキーを押しながらボタンを押すと,その変 数だけの交互作用項が投入される – 今回は,「発話量」と「集団成績」の交互作用項だ けを投入 59
60.
交互作用項の投入 • 分析結果 – 交互作用項が有意 –
情報量基準も小さくなった AIC:777→764 60
61.
単純効果分析 • 「スライス→」に群分け変数を指定 – ここでは集団成績をスライスに指定 61
62.
• 集団成績±1SDの単純効果を推定 単純効果分析 62
63.
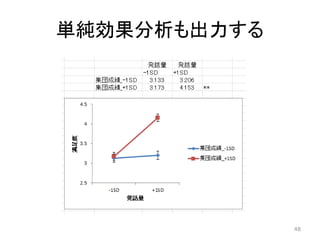
単純効果分析 発話量 発話量 -1SD +1SD 集団成績_-1SD
3.230 3.097 集団成績_+1SD 3.350 4.057 ** 2.5 3 3.5 4 4.5 -1SD +1SD 満足度 発話量 集団成績_-1SD 集団成績_+1SD 63
64.
マルチレベルモデルあれこれ 64
65.
HLMをするならどのソフトウェア? • HLM7→ HLMだけならベスト •
HAD → REMLができない 単純効果分析可 • Mplus → REMLができない • SPSS→ ロバストSEが出ない、DF設定が不自由 • R → ロバストSEが出ない • HLMをするならとりあえずHLM7がオススメ – フリーソフトならHADで十分 65
66.
結果を報告するとき • 固定効果は回帰分析とまったく同じ – 推定値,効果量,
信頼区間,検定統計量,p値 – βとかγなど,数式や記号は必須ではない • 変量効果は分散か標準偏差を報告 – 分散か標準偏差かは,ソフトウェアの出力による • 適合度 – 逸脱度(-2*対数尤度) • これも必須ではない – モデル比較をするなら,情報量基準 66
67.
階層「線形」モデル? • 実は線形だけではない – HLM7はロジットやポワソンなどのリンクを選べる –
SPSSも一般化線形混合モデルで可能 • ただし,推定精度はよくない • 擬最尤法を使っているため • HADでは,簡便的な推定法で可能 – 一般化線形モデルを使って,クラスタ標準誤差で 推定精度を補正する方法 67
68.
HLMの限界 • 従属変数が一つ – 重回帰分析の発展版であることの限界 –
モデリングが限られる • 集団レベルの独立変数の問題 – 個人レベルの変数を平均化する必要がある – 説明変数の集団平均値の信頼性が低い場合, 推定にバイアスが生じる 68
69.
マルチレベル構造方程式モデル • Multilevel Structure
Equation Modeling – 以下、ML-SEM – SEMの階層的データ分析版 • 多変量を扱ったモデリングが可能 – 適合度指標を参照できる – 今のところ、Mplus、EQS、ML-winなどが対応 • 今回は簡単な紹介にとどめる 69
70.
HLMとML-SEMのイメージ 個人レベル 説明変数 個人レベル 目的変数 個人レベル HLM 集団レベル 分解 70 集団平均で中心化 集団レベル 独立変数 集団平均値 集団平均値には個人レベルの情報が含まれる
71.
HLMとML-SEMのイメージ 説明変数 集団レベル 個人レベル 目的変数 個人レベル 分解 ML-SEM 集団レベル 分解 71 集団レベルの推定は,ML-SEMのほうが正確
72.
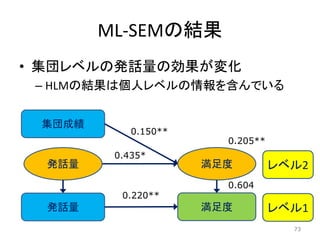
HLMの結果 • 発言量の集団平均のパスが有意 – しかも高度に有意 72 発話量_wc 集団成績 満足度 満足度
レベル2 レベル1 発話量_m 平均化 0.154** 0.344** 0.220** 0.211** 0.604 72
73.
ML-SEMの結果 • 集団レベルの発話量の効果が変化 – HLMの結果は個人レベルの情報を含んでいる 73 発話量 集団成績 満足度 満足度
レベル2 レベル1 0.150** 0.435* 0.220** 0.205** 0.604 73 発話量
74.
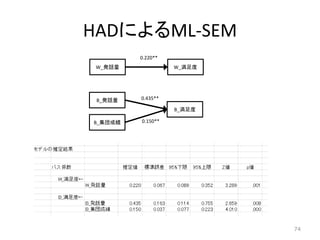
HADによるML-SEM 74 W_満足度W_発話量 B_満足度 B_発話量 B_集団成績 0.220** 0.435** 0.150**
75.
HLMとML-SEMの違い • 同じ点 – 階層的なデータを分析できる –
ML-SEMはHLMの上位モデル • 回帰分析と構造方程式モデルの関係と同じ • ML-SEMの利点 – モデリングが自由(HLMは従属変数が一つ) – 個人のデータから、集団レベルの独立変数を推定で きる(HLMは平均値を算出する必要がある) • HLMの利点 – 多くのソフトウェアが対応している – 制限付き最尤法を利用できる • 不偏分散を推定できる 75
76.
階層線形モデルについての資料 • Raudenbush, S.
W. & Bryk, A. S. (2002). – Hierarchical linear models – Applications and data analysis methods(2nd ED.). – HLMについてのほぼすべてが書いてある • PreacherのWebサイト – http://www.quantpsy.org/interact/index.html – HLMの単純効果分析を実行できる • 奥村太一 (2006). – 階層的線形モデルによるデータの分析例 – http://www.p.u-tokyo.ac.jp/~okumurin/gd_okumura.pdf 76
77.
階層線形モデルについての資料 • 尾崎幸謙先生のWeb資料 – http://www.jartest.jp/pdf/3-5ozaki.pdf –
独立変数の中心化についてまとめてある • 水本篤先生のWebサイトの資料 – http://mizumot.com/lablog/archives/179 – 今日の話とは少し違った視点での説明がある • 村山航先生のWebサイトの資料 – http://www4.ocn.ne.jp/~murakou/statistics.htm – HLMについてのマニアックな話題がいくつかある 77
78.
ありがとうございました • 清水裕士 – 所属:広島大学
大学院総合科学研究科 • 助教 – 専門:社会心理学 グループダイナミクス • 親密な対人関係におけるソーシャル・サポート • 社会規範・道徳の進化 • 連絡先 – E-mail:simizu706(at)hiroshima-u.ac.jp – Webサイト:http://norimune.net – Twitter: @simizu706
Download