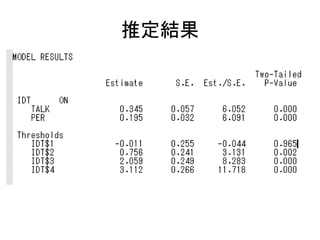
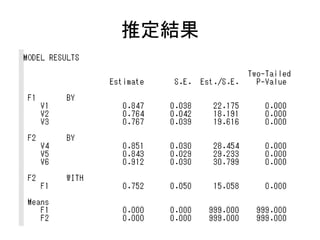
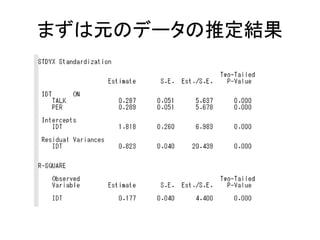
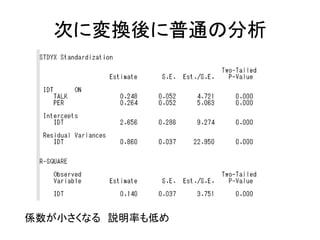
このスライドのコードはMplusデモ版で実行可能です。 http://www.statmodel.com/demo.shtml また、こちらのページにサンプルデータを置いています。 http://bit.ly/12NgDmI 初級編はこちらをどうぞ。 http://www.slideshare.net/simizu706/mplus-lecture-1





















![配置不変のコード
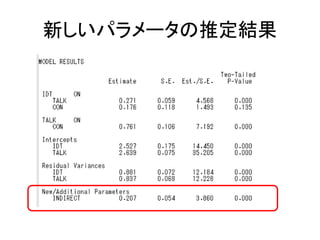
MODEL:
F1 by v1-v3*;
F2 by v4-v6*;
F1-F2@1;
[F1-F2@0];
MODEL female:
F1 by v1-v3*;
F2 by v4-v6*;
F1-F2; [F1-F2];](https://image.slidesharecdn.com/mpluslecture2-130312082349-phpapp02/85/Mplus-25-320.jpg)
![測定不変のコード
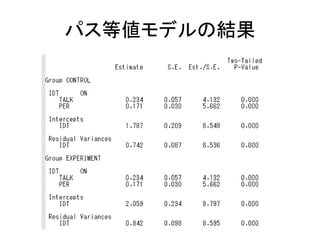
MODEL:
F1 by v1-v3*;
F2 by v4-v6*;
F1-F2@1;
[F1-F2@0];
MODEL female:
F1-F2;
[F1-F2];](https://image.slidesharecdn.com/mpluslecture2-130312082349-phpapp02/85/Mplus-26-320.jpg)
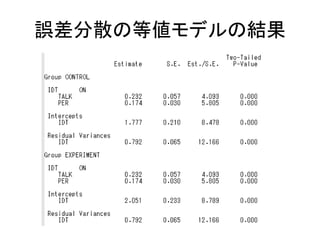
![弱因子不変のコード
MODEL:
F1 by v1-v3*;
F2 by v4-v6*;
F1-F2@1;
[F1-F2@0];
F1 with F2(cov1);
MODEL female:
[F1-F2];](https://image.slidesharecdn.com/mpluslecture2-130312082349-phpapp02/85/Mplus-27-320.jpg)
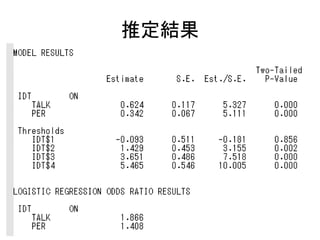
![強因子不変のコード
MODEL:
F1 by v1-v3*;
F2 by v4-v6*;
F1-F2@1;
[F1-F2@0];
F1 with F2(cov1);
v1-v6(err1-err6);
MODEL female:
[F1-F2];](https://image.slidesharecdn.com/mpluslecture2-130312082349-phpapp02/85/Mplus-28-320.jpg)











![以下のコードを書く
VARIABLE:
NAMES = ID v1-v6 sex;
USEVARIABLES = v1-v6;
MISSING = .;
CATEGORICAL = v1-v6;
ANALYSIS:
TYPE = GENERAL;
ESTIMATOR = WLS;
MODEL:
F1 by v1-v3*;
F2 by v4-v6*;
F1-F2@1;
[F1-F2@0];](https://image.slidesharecdn.com/mpluslecture2-130312082349-phpapp02/85/Mplus-42-320.jpg)

![以下のコードを書く
VARIABLE:
NAMES = ID v1-v6 sex;
USEVARIABLES = v1-v3 sex;
MISSING = .;
CATEGORICAL = v1-v3;
NOMINAL = sex;
ANALYSIS:
TYPE = GENERAL;
ESTIMATOR = ML;
MODEL:
F1 by v1-v3*;
F1@1;
[F1@0];
sex on F1;](https://image.slidesharecdn.com/mpluslecture2-130312082349-phpapp02/85/Mplus-45-320.jpg)





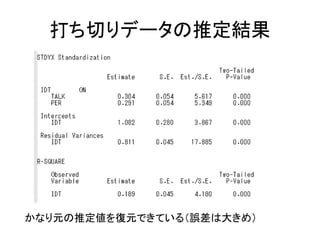

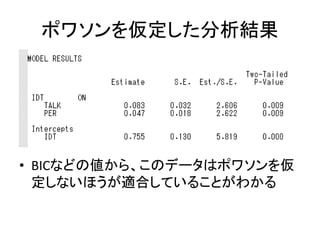









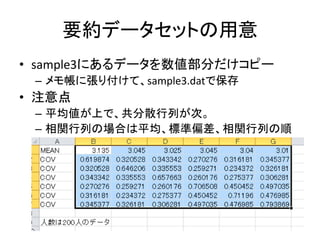




![以下のコードを書く
VARIABLE:
NAMES = ID v1-v6 sex;
USEVARIABLES = v1-v6;
MISSING = .;
CATEGORICAL = v1-v6;
ANALYSIS:
ESTIMATOR = ML;
MODEL:
F1 by v1-v6*(p1-p6);
F1@1; [F1@0];
MODEL Constraint:
NEW(a1-a6);
DO(1,6)p# = 1.702*a#;
PLOT:
TYPE = PLOT3;](https://image.slidesharecdn.com/mpluslecture2-130312082349-phpapp02/85/Mplus-70-320.jpg)
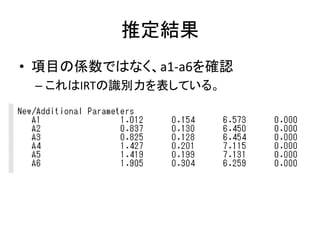
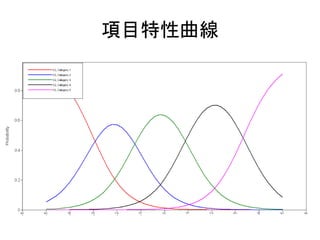
![多母集団の項目反応理論
• 性別で項目反応理論の推定が等しいか検討
– MLによるカテゴリカル分析は多母集団同時分析では
実行できない
• よって、WLSによる推定を使う
– 閾値母数の指定方法
[v1$1-v1$3];
[v2$1-v2$4];
[v3$1-v3$4];
[v4$1-v4$4];
[v5$1-v5$4];
[v6$1-v6$4];](https://image.slidesharecdn.com/mpluslecture2-130312082349-phpapp02/85/Mplus-74-320.jpg)
![識別力は等値で閾値が異なるモデル
VARIABLE: MODEL female:
NAMES = ID v1-v6 sex; F1 by v1-v6*(p1-p6);
USEVARIABLES = v1-v6; F1@1;
MISSING = .; [F1@0];
CATEGORICAL = v1-v6; [v1$1-v1$3];
GROUPING = sex(1 = male 2 =
female); [v2$1-v2$4];
[v3$1-v3$4];
ANALYSIS: [v4$1-v4$4];
TYPE = GENERAL; [v5$1-v5$4];
ESTIMATOR = WLS; [v6$1-v6$4];
MODEL: PLOT:
F1 by v1-v6*(p1-p6); TYPE = PLOT3;
F1@1;
[F1@0];](https://image.slidesharecdn.com/mpluslecture2-130312082349-phpapp02/85/Mplus-75-320.jpg)

![識別力も閾値も異なるモデル
VARIABLE: %c#2%
NAMES = ID v1-v6 sex; F1 by v1-v6*(q1-q6);
USEVARIABLES = v1-v6; F1@1;
MISSING = .; [F1@0];
CATEGORICAL = v1-v6; [v1$1-v1$3];
CLASS = c(2); [v2$1-v2$4];
KNOWNCLASS = c(sex = 1 sex = 2); [v3$1-v3$4];
[v4$1-v4$4];
ANALYSIS: [v5$1-v5$4];
TYPE = MIXTURE; [v6$1-v6$4];
ESTIMATOR = ML;
ALGORITHM=INTEGRATION; MODEL Constraint:
NEW(a1-a6 b1-b6);
MODEL: DO(1,6)p# = 1.702*a#;
%OVERALL% DO(1,6)q# = 1.702*b#;
F1 by v1-v6*(p1-p6);
F1@1; PLOT:
[F1@0]; TYPE = PLOT3;](https://image.slidesharecdn.com/mpluslecture2-130312082349-phpapp02/85/Mplus-77-320.jpg)




































































