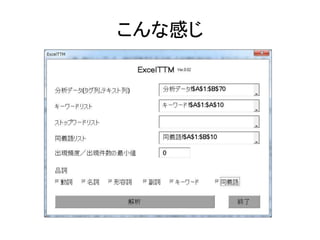
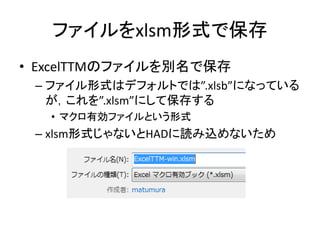
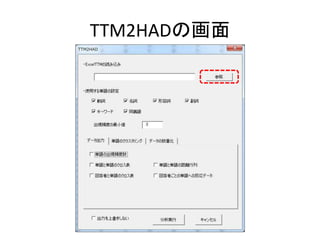
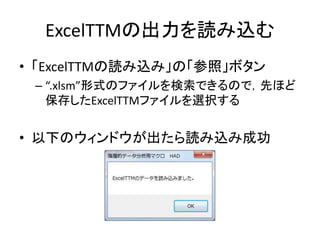
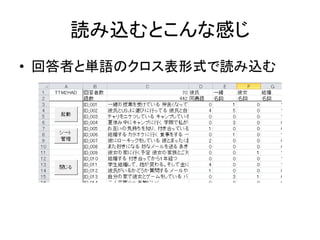
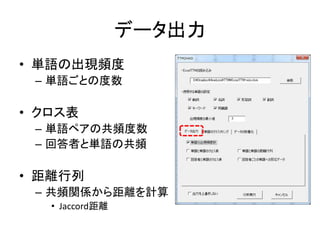
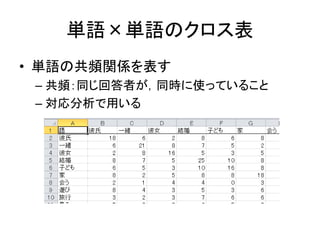
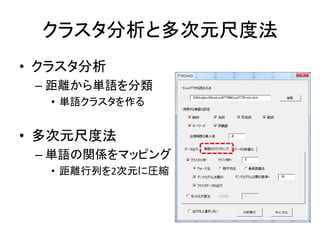
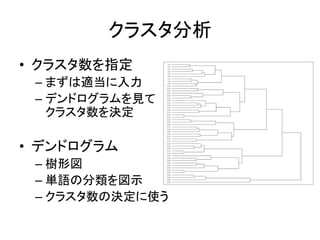
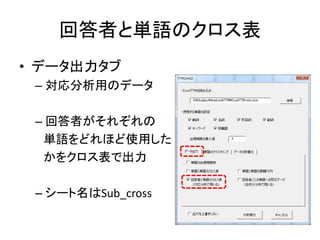
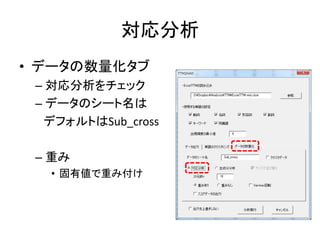
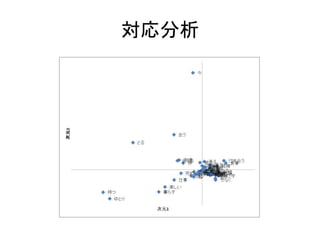
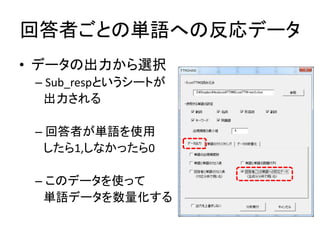
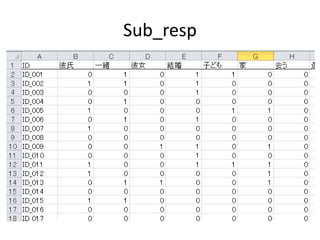
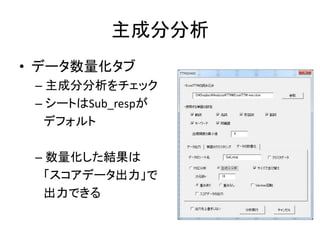
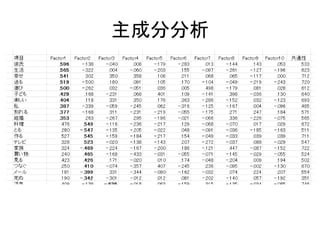
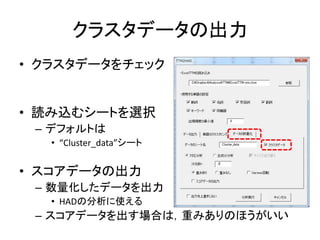
Excelで動くフリーソフトである,ExcelTTMとHADを用いたテキストマイニングの方法を解説しています。 HADはhttp://norimune.net/hadからダウンロードできます。 ExcelTTMはhttp://mtmr.jp/excelttm/からダウンロードできます。























































![心理学者のためのJASP入門(操作編)[説明文をよんでください]](https://cdn.slidesharecdn.com/ss_thumbnails/test-180307053956-thumbnail.jpg?width=640&height=640&fit=bounds)










































