Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Kohei KaiGai
951 views
20170127 JAWS HPC-UG#8
2017-01-29 JAWS HPC-UG#8のLTのスライド
Software
◦
Related topics:
Drug Discovery Insights
•
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 19
2
/ 19
3
/ 19
4
/ 19
5
/ 19
6
/ 19
7
/ 19
8
/ 19
9
/ 19
10
/ 19
11
/ 19
12
/ 19
13
/ 19
14
/ 19
15
/ 19
16
/ 19
17
/ 19
18
/ 19
19
/ 19
More Related Content
PDF
pgconfasia2016 lt ssd2gpu
by
Kohei KaiGai
PDF
PL/CUDA - Fusion of HPC Grade Power with In-Database Analytics
by
Kohei KaiGai
PDF
An Intelligent Storage?
by
Kohei KaiGai
PDF
20170310_InDatabaseAnalytics_#1
by
Kohei KaiGai
PDF
20170329_BigData基盤研究会#7
by
Kohei KaiGai
PDF
SQL+GPU+SSD=∞ (Japanese)
by
Kohei KaiGai
PDF
TPC-DSから学ぶPostgreSQLの弱点と今後の展望
by
Kohei KaiGai
PDF
PL/CUDA - GPU Accelerated In-Database Analytics
by
Kohei KaiGai
pgconfasia2016 lt ssd2gpu
by
Kohei KaiGai
PL/CUDA - Fusion of HPC Grade Power with In-Database Analytics
by
Kohei KaiGai
An Intelligent Storage?
by
Kohei KaiGai
20170310_InDatabaseAnalytics_#1
by
Kohei KaiGai
20170329_BigData基盤研究会#7
by
Kohei KaiGai
SQL+GPU+SSD=∞ (Japanese)
by
Kohei KaiGai
TPC-DSから学ぶPostgreSQLの弱点と今後の展望
by
Kohei KaiGai
PL/CUDA - GPU Accelerated In-Database Analytics
by
Kohei KaiGai
What's hot
PDF
20210511_PGStrom_GpuCache
by
Kohei KaiGai
PDF
20210731_OSC_Kyoto_PGStrom3.0
by
Kohei KaiGai
PDF
20200828_OSCKyoto_Online
by
Kohei KaiGai
PDF
並列クエリを実行するPostgreSQLのアーキテクチャ
by
Kohei KaiGai
PDF
20211112_jpugcon_gpu_and_arrow
by
Kohei KaiGai
PDF
20190418_PGStrom_on_ArrowFdw
by
Kohei KaiGai
PDF
20181211 - PGconf.ASIA - NVMESSD&GPU for BigData
by
Kohei KaiGai
PDF
(JP) GPGPUがPostgreSQLを加速する
by
Kohei KaiGai
PDF
20200806_PGStrom_PostGIS_GstoreFdw
by
Kohei KaiGai
PDF
[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...
by
Insight Technology, Inc.
PDF
GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]
by
Kohei KaiGai
PDF
20170726 py data.tokyo
by
ManaMurakami1
PDF
20191115-PGconf.Japan
by
Kohei KaiGai
PDF
20171220_hbstudy80_pgstrom
by
Kohei KaiGai
PDF
20180920_DBTS_PGStrom_JP
by
Kohei KaiGai
PDF
SSDとGPUがPostgreSQLを加速する【OSC.Enterprise】
by
Kohei KaiGai
PDF
20201113_PGconf_Japan_GPU_PostGIS
by
Kohei KaiGai
PDF
NVIDIA TESLA V100・CUDA 9 のご紹介
by
NVIDIA Japan
PDF
20180217 FPGA Extreme Computing #10
by
Kohei KaiGai
PDF
Maxwell と Java CUDAプログラミング
by
NVIDIA Japan
20210511_PGStrom_GpuCache
by
Kohei KaiGai
20210731_OSC_Kyoto_PGStrom3.0
by
Kohei KaiGai
20200828_OSCKyoto_Online
by
Kohei KaiGai
並列クエリを実行するPostgreSQLのアーキテクチャ
by
Kohei KaiGai
20211112_jpugcon_gpu_and_arrow
by
Kohei KaiGai
20190418_PGStrom_on_ArrowFdw
by
Kohei KaiGai
20181211 - PGconf.ASIA - NVMESSD&GPU for BigData
by
Kohei KaiGai
(JP) GPGPUがPostgreSQLを加速する
by
Kohei KaiGai
20200806_PGStrom_PostGIS_GstoreFdw
by
Kohei KaiGai
[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...
by
Insight Technology, Inc.
GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]
by
Kohei KaiGai
20170726 py data.tokyo
by
ManaMurakami1
20191115-PGconf.Japan
by
Kohei KaiGai
20171220_hbstudy80_pgstrom
by
Kohei KaiGai
20180920_DBTS_PGStrom_JP
by
Kohei KaiGai
SSDとGPUがPostgreSQLを加速する【OSC.Enterprise】
by
Kohei KaiGai
20201113_PGconf_Japan_GPU_PostGIS
by
Kohei KaiGai
NVIDIA TESLA V100・CUDA 9 のご紹介
by
NVIDIA Japan
20180217 FPGA Extreme Computing #10
by
Kohei KaiGai
Maxwell と Java CUDAプログラミング
by
NVIDIA Japan
Viewers also liked
PDF
pgconfasia2016 plcuda en
by
Kohei KaiGai
PDF
SQL+GPU+SSD=∞ (English)
by
Kohei KaiGai
PDF
PL/CUDA - Fusion of HPC Grade Power with In-Database Analytics
by
Kohei KaiGai
PDF
20160407_GTC2016_PgSQL_In_Place
by
Kohei KaiGai
PDF
UX, ethnography and possibilities: for Libraries, Museums and Archives
by
Ned Potter
PDF
Designing Teams for Emerging Challenges
by
Aaron Irizarry
PDF
Visual Design with Data
by
Seth Familian
PDF
3 Things Every Sales Team Needs to Be Thinking About in 2017
by
Drift
PDF
How to Become a Thought Leader in Your Niche
by
Leslie Samuel
PDF
Task Parallel Library (TPL)
by
Muhammad Zaid Sarfraz
PDF
PostgreSQL with OpenCL
by
Muhaza Liebenlito
PDF
PG-Strom - A FDW module utilizing GPU device
by
Kohei KaiGai
PDF
TPL Dataflow – зачем и для кого?
by
GoSharp
PPTX
Task Parallel Library 2014
by
Lluis Franco
PDF
Technology Updates of PG-Strom at Aug-2014 (PGUnconf@Tokyo)
by
Kohei KaiGai
PDF
Let's turn your PostgreSQL into columnar store with cstore_fdw
by
Jan Holčapek
PDF
GPGPU Accelerates PostgreSQL ~Unlock the power of multi-thousand cores~
by
Kohei KaiGai
PDF
dashDB & R によるデータ分析 - In database Analytics 基礎編 -
by
IBM Analytics Japan
PDF
dashDB local ご紹介
by
IBM Analytics Japan
PPTX
Oracle In-database-archiving ~Oracleでの論理削除~
by
Daiki Mogmet Ito
pgconfasia2016 plcuda en
by
Kohei KaiGai
SQL+GPU+SSD=∞ (English)
by
Kohei KaiGai
PL/CUDA - Fusion of HPC Grade Power with In-Database Analytics
by
Kohei KaiGai
20160407_GTC2016_PgSQL_In_Place
by
Kohei KaiGai
UX, ethnography and possibilities: for Libraries, Museums and Archives
by
Ned Potter
Designing Teams for Emerging Challenges
by
Aaron Irizarry
Visual Design with Data
by
Seth Familian
3 Things Every Sales Team Needs to Be Thinking About in 2017
by
Drift
How to Become a Thought Leader in Your Niche
by
Leslie Samuel
Task Parallel Library (TPL)
by
Muhammad Zaid Sarfraz
PostgreSQL with OpenCL
by
Muhaza Liebenlito
PG-Strom - A FDW module utilizing GPU device
by
Kohei KaiGai
TPL Dataflow – зачем и для кого?
by
GoSharp
Task Parallel Library 2014
by
Lluis Franco
Technology Updates of PG-Strom at Aug-2014 (PGUnconf@Tokyo)
by
Kohei KaiGai
Let's turn your PostgreSQL into columnar store with cstore_fdw
by
Jan Holčapek
GPGPU Accelerates PostgreSQL ~Unlock the power of multi-thousand cores~
by
Kohei KaiGai
dashDB & R によるデータ分析 - In database Analytics 基礎編 -
by
IBM Analytics Japan
dashDB local ご紹介
by
IBM Analytics Japan
Oracle In-database-archiving ~Oracleでの論理削除~
by
Daiki Mogmet Ito
Similar to 20170127 JAWS HPC-UG#8
PDF
2012-03-08 MSS研究会
by
Kimikazu Kato
PDF
20181212 - PGconf.ASIA - LT
by
Kohei KaiGai
PPTX
SIGMOD 2022 Amazon Redshift Re-invented を読んで
by
Yohei Azekatsu
PDF
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
PDF
20190925_DBTS_PGStrom
by
Kohei KaiGai
PDF
20191211_Apache_Arrow_Meetup_Tokyo
by
Kohei KaiGai
PDF
[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する
by
DNA Data Bank of Japan center
PDF
20190516_DLC10_PGStrom
by
Kohei KaiGai
PDF
PostgreSQL 9.2 新機能 - 新潟オープンソースセミナー2012
by
Shigeru Hanada
PDF
生成AI時代のPostgreSQLハイブリッド検索 (第50回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
More modern gpu
by
Preferred Networks
PDF
20180914 GTCJ INCEPTION HeteroDB
by
Kohei KaiGai
PDF
20160324自由集会講演
by
astanabe
PDF
より深く知るオプティマイザとそのチューニング
by
Yuto Hayamizu
PDF
GPGPUを用いた大規模高速グラフ処理に向けて
by
Koichi Shirahata
PPTX
2012 1203-researchers-cafe
by
Toshiya Komoda
PDF
ChatGPTのデータソースにPostgreSQLを使う[詳細版](オープンデベロッパーズカンファレンス2023 発表資料)
by
NTT DATA Technology & Innovation
PDF
pgvectorを使ってChatGPTとPostgreSQLを連携してみよう!(PostgreSQL Conference Japan 2023 発表資料)
by
NTT DATA Technology & Innovation
PPTX
GPU-FPGA協調プログラミングを実現するコンパイラの開発
by
Ryuuta Tsunashima
PDF
2021 03-09-ac ri-nngen
by
直久 住川
2012-03-08 MSS研究会
by
Kimikazu Kato
20181212 - PGconf.ASIA - LT
by
Kohei KaiGai
SIGMOD 2022 Amazon Redshift Re-invented を読んで
by
Yohei Azekatsu
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
20190925_DBTS_PGStrom
by
Kohei KaiGai
20191211_Apache_Arrow_Meetup_Tokyo
by
Kohei KaiGai
[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する
by
DNA Data Bank of Japan center
20190516_DLC10_PGStrom
by
Kohei KaiGai
PostgreSQL 9.2 新機能 - 新潟オープンソースセミナー2012
by
Shigeru Hanada
生成AI時代のPostgreSQLハイブリッド検索 (第50回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
More modern gpu
by
Preferred Networks
20180914 GTCJ INCEPTION HeteroDB
by
Kohei KaiGai
20160324自由集会講演
by
astanabe
より深く知るオプティマイザとそのチューニング
by
Yuto Hayamizu
GPGPUを用いた大規模高速グラフ処理に向けて
by
Koichi Shirahata
2012 1203-researchers-cafe
by
Toshiya Komoda
ChatGPTのデータソースにPostgreSQLを使う[詳細版](オープンデベロッパーズカンファレンス2023 発表資料)
by
NTT DATA Technology & Innovation
pgvectorを使ってChatGPTとPostgreSQLを連携してみよう!(PostgreSQL Conference Japan 2023 発表資料)
by
NTT DATA Technology & Innovation
GPU-FPGA協調プログラミングを実現するコンパイラの開発
by
Ryuuta Tsunashima
2021 03-09-ac ri-nngen
by
直久 住川
More from Kohei KaiGai
PDF
20221116_DBTS_PGStrom_History
by
Kohei KaiGai
PDF
20221111_JPUG_CustomScan_API
by
Kohei KaiGai
PDF
20210928_pgunconf_hll_count
by
Kohei KaiGai
PDF
20210301_PGconf_Online_GPU_PostGIS_GiST_Index
by
Kohei KaiGai
PDF
20201128_OSC_Fukuoka_Online_GPUPostGIS
by
Kohei KaiGai
PDF
20201006_PGconf_Online_Large_Data_Processing
by
Kohei KaiGai
PDF
20200424_Writable_Arrow_Fdw
by
Kohei KaiGai
PDF
20190926_Try_RHEL8_NVMEoF_Beta
by
Kohei KaiGai
PDF
20190909_PGconf.ASIA_KaiGai
by
Kohei KaiGai
PDF
20181212 - PGconfASIA - LT - English
by
Kohei KaiGai
PDF
20181210 - PGconf.ASIA Unconference
by
Kohei KaiGai
PDF
20181116 Massive Log Processing using I/O optimized PostgreSQL
by
Kohei KaiGai
PDF
20181016_pgconfeu_ssd2gpu_multi
by
Kohei KaiGai
PDF
20181025_pgconfeu_lt_gstorefdw
by
Kohei KaiGai
PDF
20180920_DBTS_PGStrom_EN
by
Kohei KaiGai
20221116_DBTS_PGStrom_History
by
Kohei KaiGai
20221111_JPUG_CustomScan_API
by
Kohei KaiGai
20210928_pgunconf_hll_count
by
Kohei KaiGai
20210301_PGconf_Online_GPU_PostGIS_GiST_Index
by
Kohei KaiGai
20201128_OSC_Fukuoka_Online_GPUPostGIS
by
Kohei KaiGai
20201006_PGconf_Online_Large_Data_Processing
by
Kohei KaiGai
20200424_Writable_Arrow_Fdw
by
Kohei KaiGai
20190926_Try_RHEL8_NVMEoF_Beta
by
Kohei KaiGai
20190909_PGconf.ASIA_KaiGai
by
Kohei KaiGai
20181212 - PGconfASIA - LT - English
by
Kohei KaiGai
20181210 - PGconf.ASIA Unconference
by
Kohei KaiGai
20181116 Massive Log Processing using I/O optimized PostgreSQL
by
Kohei KaiGai
20181016_pgconfeu_ssd2gpu_multi
by
Kohei KaiGai
20181025_pgconfeu_lt_gstorefdw
by
Kohei KaiGai
20180920_DBTS_PGStrom_EN
by
Kohei KaiGai
20170127 JAWS HPC-UG#8
1.
Run Drug-Discovery Workloads In-database
on AWS The PG-Strom Project KaiGai Kohei <kaigai@kaigai.gr.jp>
2.
The PG-Strom Project 自己紹介 JAWS-UG
HPC#8 / Run Drug-Discovery Workloads In-database, On AWS2 ▌海外 浩平 (KaiGai Kohei) tw: @kkaigai https://github.com/kaigai ▌PostgreSQL SELinux, Database Federation (FDW, CustomScan), etc... ▌PG-Strom GPUを用いたPostgreSQL向け 高速化モジュールの作者
3.
The PG-Strom Project PG-Strom概要
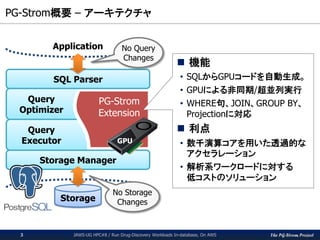
– アーキテクチャ JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS3 Application Storage Query Optimizer Query Executor PG-Strom Extension SQL Parser Storage Manager GPU No Storage Changes No Query Changes 機能 • SQLからGPUコードを自動生成。 • GPUによる非同期/超並列実行 • WHERE句、JOIN、GROUP BY、 Projectionに対応 利点 • 数千演算コアを用いた透過的な アクセラレーション • 解析系ワークロードに対する 低コストのソリューション
4.
The PG-Strom Project GPUによるSQL実行高速化の一例 JAWS-UG
HPC#8 / Run Drug-Discovery Workloads In-database, On AWS4 ▌Test Query: SELECT cat, count(*), avg(x) FROM t0 NATURAL JOIN t1 [NATURAL JOIN t2 ...] GROUP BY cat; t0 contains 100M rows, t1...t8 contains 100K rows (like a start schema) 40.44 62.79 79.82 100.50 119.51 144.55 201.12 248.95 9.96 9.93 9.96 9.99 10.02 10.03 9.98 10.00 0 50 100 150 200 250 300 2 3 4 5 6 7 8 9 QueryResponseTime[sec] Number of joined tables PG-Strom microbenchmark with JOIN/GROUP BY PostgreSQL v9.5 PG-Strom v1.0 CPU: Xeon E5-2670v3 GPU: GTX1080 RAM: 384GB OS: CentOS 7.2 DB: PostgreSQL 9.5 + PG-Strom v1.0
5.
The PG-Strom Project 失敗から学ぶ
(1/2) – アルゴリズムをSQLで記述する JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS5 Apr-2016 問題① そもそも SQL でアルゴリズムを 書く人って何人くらいいるのか?
6.
The PG-Strom Project 失敗から学ぶ
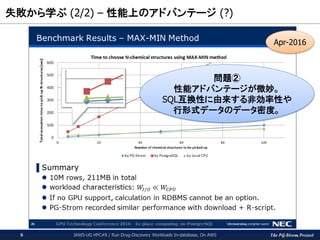
(2/2) – 性能上のアドバンテージ (?) JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS6 Apr-2016 問題② 性能アドバンテージが微妙。 SQL互換性に由来する非効率性や 行形式データのデータ密度。
7.
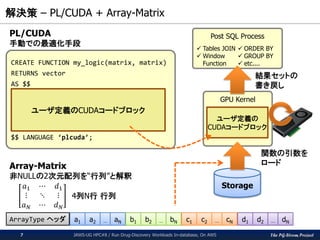
The PG-Strom Project 解決策
– PL/CUDA + Array-Matrix JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS7 CREATE FUNCTION my_logic(matrix, matrix) RETURNS vector AS $$ $$ LANGUAGE ‘plcuda’; ユーザ定義のCUDAコードブロック Storage GPU Kernel ユーザ定義の CUDAコードブロック Post SQL Process Tables JOIN Window Function ORDER BY GROUP BY etc.... 関数の引数を ロード 結果セットの 書き戻し PL/CUDA 手動での最適化手段 ArrayType ヘッダ a1 a2 aN… b1 b2 bN… c1 c2 cN… d1 d2 dN… 𝑎1 ⋯ 𝑑1 ⋮ ⋱ ⋮ 𝑎 𝑁 ⋯ 𝑑 𝑁 4列N行 行列 Array-Matrix 非NULLの2次元配列を“行列”と解釈
8.
The PG-Strom Project PL/CUDA関数定義の例 JAWS-UG
HPC#8 / Run Drug-Discovery Workloads In-database, On AWS8 CREATE OR REPLACE FUNCTION knn_gpu_similarity(int, int[], int[]) RETURNS float4[] AS $$ #plcuda_begin cl_int k = arg1.value; MatrixType *Q = (MatrixType *) arg2.value; MatrixType *D = (MatrixType *) arg3.value; MatrixType *R = (MatrixType *) results; : nloops = (ARRAY_MATRIX_HEIGHT(Q) + (part_sz - k - 1)) / (part_sz - k); for (loop=0; loop < nloops; loop++) { /* 1. calculation of the similarity */ for (i = get_local_id(); i < part_sz * part_nums; i += get_local_size()) { j = i % part_sz; /* index within partition */ /* index of database matrix (D) */ dindex = part_nums * get_global_index() + (i / part_sz); /* index of query matrix (Q) */ qindex = loop * (part_sz - k) + (j - k); values[i] = knn_similarity_compute(D, dindex, Q, qindex); } } : #plcuda_end $$ LANGUAGE 'plcuda'; CUDA code block
9.
The PG-Strom ProjectJAWS-UG
HPC#8 / Run Drug-Discovery Workloads In-database, On AWS9 Case Study 創薬における類似度サーチ
10.
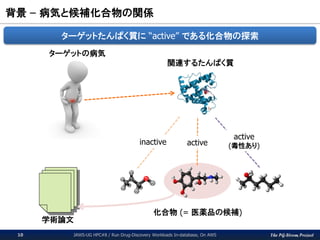
The PG-Strom Project 背景
– 病気と候補化合物の関係 JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS10 ターゲットの病気 関連するたんぱく質 化合物 (= 医薬品の候補) ターゲットたんぱく質に “active” である化合物の探索 inactive active active (毒性あり) 学術論文
11.
The PG-Strom Project k-NN法による類似化合物サーチ
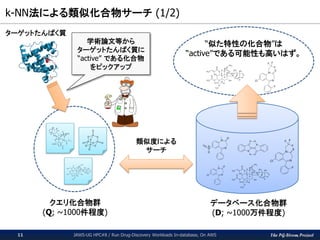
(1/2) JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS11 データベース化合物群 (D; ~1000万件程度) クエリ化合物群 (Q; ~1000件程度) 類似度による サーチ ターゲットたんぱく質 “似た特性の化合物”は “active”である可能性も高いはず。 学術論文等から ターゲットたんぱく質に “active” である化合物 をピックアップ
12.
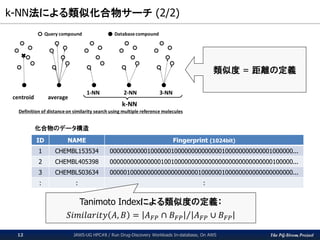
The PG-Strom Project k-NN法による類似化合物サーチ
(2/2) JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS12 類似度 = 距離の定義 ID NAME Fingerprint (1024bit) 1 CHEMBL153534 000000000001000000100000000000000100000000000001000000... 2 CHEMBL405398 000000000000000100100000000000000000000000000000100000... 3 CHEMBL503634 000001000000000000000000001000000100000000000000000000... : : : 化合物のデータ構造 Tanimoto Indexによる類似度の定義: 𝑆𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦 𝐴, 𝐵 = 𝐴 𝐹𝑃 ∩ 𝐵 𝐹𝑃 𝐴 𝐹𝑃 ∪ 𝐵 𝐹𝑃
13.
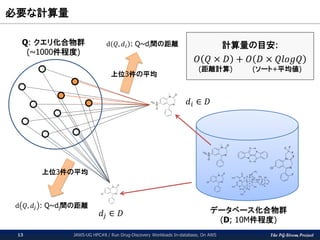
The PG-Strom Project 必要な計算量 JAWS-UG
HPC#8 / Run Drug-Discovery Workloads In-database, On AWS13 データベース化合物群 (D; 10M件程度) Q: クエリ化合物群 (~1000件程度) 上位3件の平均 𝑑𝑖 ∈ 𝐷 d 𝑄, 𝑑𝑖 : Q~di間の距離 𝑑𝑗 ∈ 𝐷 上位3件の平均 計算量の目安: 𝑂 𝑄 × 𝐷 + 𝑂 𝐷 × 𝑄𝑙𝑜𝑔𝑄 (距離計算) (ソート+平均値) d 𝑄, 𝑑𝑗 : Q~dj間の距離
14.
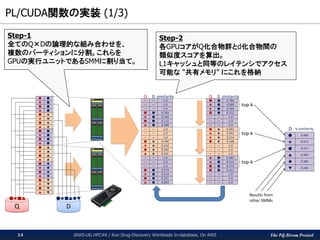
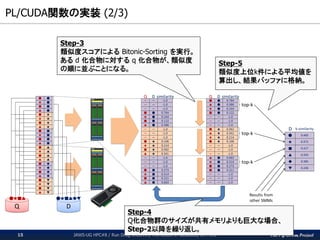
The PG-Strom Project PL/CUDA関数の実装
(1/3) JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS14 Step-1 全てのQ×Dの論理的な組み合わせを、 複数のパーティションに分割。これらを GPUの実行ユニットであるSMMに割り当て。 Step-2 各GPUコアがQ化合物群とd化合物間の 類似度スコアを算出。 L1キャッシュと同等のレイテンシでアクセス 可能な “共有メモリ” にこれを格納
15.
The PG-Strom Project PL/CUDA関数の実装
(2/3) JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS15 Step-3 類似度スコアによる Bitonic-Sorting を実行。 ある d 化合物に対する q 化合物が、類似度 の順に並ぶことになる。 Step-5 類似度上位k件による平均値を 算出し、結果バッファに格納。 Step-4 Q化合物群のサイズが共有メモリよりも巨大な場合、 Step-2以降を繰り返し。
16.
The PG-Strom Project PL/CUDA関数の実装
(3/3) JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS16 CREATE OR REPLACE FUNCTION knn_gpu_similarity(int, -- k-value int[], -- ID+bitmap of Q int[]) -- ID+bitmap of D RETURNS float4[] -- result: ID+similarity AS $$ #plcuda_decl : #plcuda_begin #plcuda_kernel_blocksz ¥ knn_gpu_similarity_main_block_size #plcuda_num_threads ¥ knn_gpu_similarity_main_num_threads #plcuda_shmem_blocksz 8192 cl_int k = arg1.value; MatrixType *Q = (MatrixType *) arg2.value; MatrixType *D = (MatrixType *) arg3.value; MatrixType *R = (MatrixType *) results; : for (loop=0; loop < nloops; loop++) { /* 1. calculation of the similarity */ for (i = get_local_id(); i < part_sz * part_nums; i += get_local_size()) { j = i % part_sz; /* index within partition */ dindex = part_nums * get_global_index() + (i / part_sz); qindex = loop * (part_sz - k) + (j - k); if (dindex < ARRAY_MATRIX_HEIGHT(D) && qindex < ARRAY_MATRIX_HEIGHT(Q)) { values[i] = knn_similarity_compute(D, dindex, Q, qindex); } } __syncthreads(); /* 2. sorting by the similarity for each partition */ knn_similarity_sorting(values, part_sz, part_nums); __syncthreads(); : } #plcuda_end #plcuda_sanity_check knn_gpu_similarity_sanity_check #plcuda_working_bufsz 0 #plcuda_results_bufsz knn_gpu_similarity_results_bufsz $$ LANGUAGE 'plcuda'; real[] -- ID+Similarity of D化合物 (2xN) knn_gpu_similarity(int k, -- k-value int[] Q, -- ID+Fingerprint of Q化合物 (33xM) int[] D); -- ID+Fingerprint of D化合物 (33xN)
17.
The PG-Strom Project パフォーマンス JAWS-UG
HPC#8 / Run Drug-Discovery Workloads In-database, On AWS17 CPU版は、同等のロジックをC言語によるバイナリ版で実装して比較計測 D化合物群の数は1000万レコード、Q化合物群の数は10,50,100,500,1000個の5通り 最大で100億通りの組合せを計算。これは実際の創薬ワークロードの規模と同等。 HW) p2.xlargeインスタンス, 4vCPU, GPU: Tesla K80/2, RAM: 61GB SW) CentOS7, CUDA7.5, PostgreSQL v9.5 + PG-Strom v1.0 34.29 165.06 333.30 1723.91 3487.90 17.44 18.27 19.33 25.81 34.57 0 500 1000 1500 2000 2500 3000 3500 10 50 100 500 1000 SQLクエリ応答時間[sec] (shorterisbetter) クエリ化合物数 k-NN法による類似化合物サーチ SQL応答時間 CPU (???) GPU (Tesla K80/2) x100 times faster!
18.
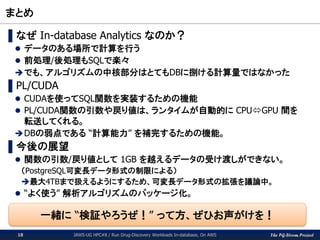
The PG-Strom Project まとめ JAWS-UG
HPC#8 / Run Drug-Discovery Workloads In-database, On AWS18 ▌なぜ In-database Analytics なのか? データのある場所で計算を行う 前処理/後処理もSQLで楽々 でも、アルゴリズムの中核部分はとてもDBに捌ける計算量ではなかった ▌PL/CUDA CUDAを使ってSQL関数を実装するための機能 PL/CUDA関数の引数や戻り値は、ランタイムが自動的に CPUGPU 間を 転送してくれる。 DBの弱点である “計算能力” を補完するための機能。 ▌今後の展望 関数の引数/戻り値として 1GB を越えるデータの受け渡しができない。 (PostgreSQL可変長データ形式の制限による) 最大4TBまで扱えるようにするため、可変長データ形式の拡張を議論中。 “よく使う” 解析アルゴリズムのパッケージ化。 一緒に “検証やろうぜ!” って方、ぜひお声がけを!
19.
Thank you!
Download



![The PG-Strom Project
GPUによるSQL実行高速化の一例
JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS4
▌Test Query:
SELECT cat, count(*), avg(x)
FROM t0 NATURAL JOIN t1 [NATURAL JOIN t2 ...]
GROUP BY cat;
t0 contains 100M rows, t1...t8 contains 100K rows (like a start schema)
40.44
62.79
79.82
100.50
119.51
144.55
201.12
248.95
9.96 9.93 9.96 9.99 10.02 10.03 9.98 10.00
0
50
100
150
200
250
300
2 3 4 5 6 7 8 9
QueryResponseTime[sec]
Number of joined tables
PG-Strom microbenchmark with JOIN/GROUP BY
PostgreSQL v9.5 PG-Strom v1.0
CPU: Xeon E5-2670v3
GPU: GTX1080
RAM: 384GB
OS: CentOS 7.2
DB: PostgreSQL 9.5 +
PG-Strom v1.0](https://image.slidesharecdn.com/20170127jawsughpclt-170129122722/85/20170127-JAWS-HPC-UG-8-4-320.jpg)

![The PG-Strom Project
PL/CUDA関数定義の例
JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS8
CREATE OR REPLACE FUNCTION
knn_gpu_similarity(int, int[], int[])
RETURNS float4[]
AS $$
#plcuda_begin
cl_int k = arg1.value;
MatrixType *Q = (MatrixType *) arg2.value;
MatrixType *D = (MatrixType *) arg3.value;
MatrixType *R = (MatrixType *) results;
:
nloops = (ARRAY_MATRIX_HEIGHT(Q) + (part_sz - k - 1)) / (part_sz - k);
for (loop=0; loop < nloops; loop++) {
/* 1. calculation of the similarity */
for (i = get_local_id(); i < part_sz * part_nums; i += get_local_size()) {
j = i % part_sz; /* index within partition */
/* index of database matrix (D) */
dindex = part_nums * get_global_index() + (i / part_sz);
/* index of query matrix (Q) */
qindex = loop * (part_sz - k) + (j - k);
values[i] = knn_similarity_compute(D, dindex, Q, qindex);
}
}
:
#plcuda_end
$$ LANGUAGE 'plcuda';
CUDA code block](https://image.slidesharecdn.com/20170127jawsughpclt-170129122722/85/20170127-JAWS-HPC-UG-8-8-320.jpg)

![The PG-Strom Project
PL/CUDA関数の実装 (3/3)
JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS16
CREATE OR REPLACE FUNCTION
knn_gpu_similarity(int, -- k-value
int[], -- ID+bitmap of Q
int[]) -- ID+bitmap of D
RETURNS float4[] -- result: ID+similarity
AS $$
#plcuda_decl
:
#plcuda_begin
#plcuda_kernel_blocksz ¥
knn_gpu_similarity_main_block_size
#plcuda_num_threads ¥
knn_gpu_similarity_main_num_threads
#plcuda_shmem_blocksz 8192
cl_int k = arg1.value;
MatrixType *Q = (MatrixType *) arg2.value;
MatrixType *D = (MatrixType *) arg3.value;
MatrixType *R = (MatrixType *) results;
:
for (loop=0; loop < nloops; loop++)
{
/* 1. calculation of the similarity */
for (i = get_local_id();
i < part_sz * part_nums;
i += get_local_size()) {
j = i % part_sz; /* index within partition */
dindex = part_nums * get_global_index()
+ (i / part_sz);
qindex = loop * (part_sz - k) + (j - k);
if (dindex < ARRAY_MATRIX_HEIGHT(D) &&
qindex < ARRAY_MATRIX_HEIGHT(Q)) {
values[i] = knn_similarity_compute(D, dindex,
Q, qindex);
}
}
__syncthreads();
/* 2. sorting by the similarity for each partition */
knn_similarity_sorting(values, part_sz, part_nums);
__syncthreads();
:
}
#plcuda_end
#plcuda_sanity_check knn_gpu_similarity_sanity_check
#plcuda_working_bufsz 0
#plcuda_results_bufsz knn_gpu_similarity_results_bufsz
$$ LANGUAGE 'plcuda';
real[] -- ID+Similarity of D化合物 (2xN)
knn_gpu_similarity(int k, -- k-value
int[] Q, -- ID+Fingerprint of Q化合物 (33xM)
int[] D); -- ID+Fingerprint of D化合物 (33xN)](https://image.slidesharecdn.com/20170127jawsughpclt-170129122722/85/20170127-JAWS-HPC-UG-8-16-320.jpg)
![The PG-Strom Project
パフォーマンス
JAWS-UG HPC#8 / Run Drug-Discovery Workloads In-database, On AWS17
CPU版は、同等のロジックをC言語によるバイナリ版で実装して比較計測
D化合物群の数は1000万レコード、Q化合物群の数は10,50,100,500,1000個の5通り
最大で100億通りの組合せを計算。これは実際の創薬ワークロードの規模と同等。
HW) p2.xlargeインスタンス, 4vCPU, GPU: Tesla K80/2, RAM: 61GB
SW) CentOS7, CUDA7.5, PostgreSQL v9.5 + PG-Strom v1.0
34.29
165.06
333.30
1723.91
3487.90
17.44 18.27 19.33 25.81 34.57
0
500
1000
1500
2000
2500
3000
3500
10 50 100 500 1000
SQLクエリ応答時間[sec]
(shorterisbetter)
クエリ化合物数
k-NN法による類似化合物サーチ SQL応答時間
CPU (???) GPU (Tesla K80/2)
x100 times
faster!](https://image.slidesharecdn.com/20170127jawsughpclt-170129122722/85/20170127-JAWS-HPC-UG-8-17-320.jpg)


















![[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...](https://cdn.slidesharecdn.com/ss_thumbnails/20170922mapd-170926064811-thumbnail.jpg?width=640&height=640&fit=bounds)
![GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]](https://cdn.slidesharecdn.com/ss_thumbnails/20170906dbtsgpussdacceleratespostgresqljp-170906073226-thumbnail.jpg?width=640&height=640&fit=bounds)



































![[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する](https://cdn.slidesharecdn.com/ss_thumbnails/31ddbjingohta-150626022623-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)









](https://cdn.slidesharecdn.com/ss_thumbnails/postgresqlchatgptodc2023nttdata-230830045114-329af13b-thumbnail.jpg?width=640&height=640&fit=bounds)

















