Download as PDF, PPTX



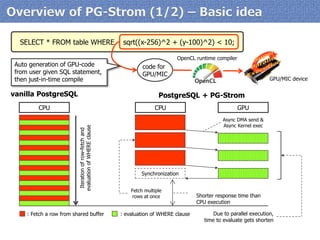
![●
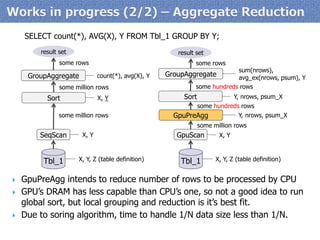
item[0]
step.1
step.2
step.4
step.3
Calculation of
Σi=0...N-1item[i]
with N of GPU cores
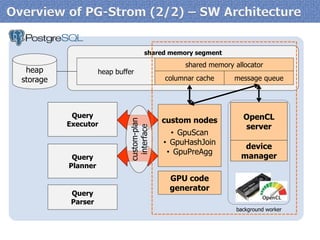
◆
●
▲
■
★
●
◆
●
●
◆
▲
●
●
◆
●
●
◆
▲
■
●
●
◆
●
●
◆
▲
●
●
◆
●
item[1]
item[2]
item[3]
item[4]
item[5]
item[6]
item[7]
item[8]
item[9]
item[10]
item[11]
item[12]
item[13]
item[14]
item[15]
Sum of items[]
with
log2N steps
Reduction algorithm well fits aggregate functionality of RDBMS](https://image.slidesharecdn.com/20140906-pgunconf-pgstrom-140906020228-phpapp02/85/Technology-Updates-of-PG-Strom-at-Aug-2014-PGUnconf-Tokyo-6-320.jpg)

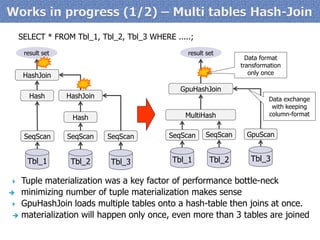
![Jul-2014 – A test implementation
◦Technical validation of GPU acceleration on RDBMS
◦Full-scan, Hash-Join, Sorting
x3~x23 times faster than vanilla PostgreSQL
Nov-2014 – A working beta
◦Target of evaluation on a series of PoC efforts
◦Full-scan, Hash-Join, Aggregate
Full-Scan
Hash-Join
Aggregate
PostgreSQL
8237.694
36206.565
7954.771
PG-Strom
545.516
8092.828
2071.513
0
5000
10000
15000
20000
25000
30000
35000
40000
Query response time [ms]
test result in the working beta (at Sep-20114)
Test Environment
Server: NEC Express5800 HR120b-1
CPU: Xeon(R) CPU E5-2640 x2
RAM: 256GB
GPU: NVidia GTX750 Ti (640 cuda cores)
Each query run on a table with 20M records. Hash-join workload joins 3 other tables with 40K rows.
Query response time comes from “execution time” in EXPLAIN ANALYZE](https://image.slidesharecdn.com/20140906-pgunconf-pgstrom-140906020228-phpapp02/85/Technology-Updates-of-PG-Strom-at-Aug-2014-PGUnconf-Tokyo-10-320.jpg)


The document discusses the performance advantages of utilizing GPU computing for database management systems, particularly with pg-strom enhancing PostgreSQL. It outlines significant speed improvements for operations such as hash-joins and full scans, claiming up to 23 times faster response times compared to traditional setups. Additionally, it considers the challenges in memory management and emphasizes minimizing tuple materialization to achieve higher performance.






















































































