4
Quadro M6000 /GeForce GTX TITAN X
Compute Capability 5.2, 3072 CUDA Cores, 300 ~ GB/sec memory bandwidth
5.
5
TESLA M40
World’s FastestAccelerator
for Deep Learning
0 1 2 3 4 5 6 7 8 9
Tesla M40
CPU
8x Faster
Caffe Performance
# of Days
Caffe Benchmark: AlexNet training throughput based on 20 iterations,
CPU: E5-2697v2 @ 2.70GHz. 64GB System Memory, CentOS 6.2
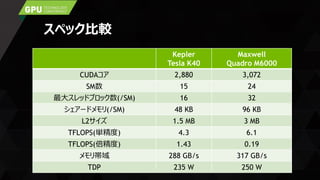
CUDA Cores 3072
Peak SP 7 TFLOPS
GDDR5 Memory 12 GB
Bandwidth 288 GB/s
Power 250W
Reduce Training Time from 8 Days to 1 Day
6.
6
TESLA M4
Highest Throughput
HyperscaleWorkload
Acceleration
CUDA Cores 1024
Peak SP 2.2 TFLOPS
GDDR5 Memory 4 GB
Bandwidth 88 GB/s
Form Factor PCIe Low Profile
Power 50 – 75 W
Video
Processing
4x
Image
Processing
5x
Video
Transcode
2x
Machine
Learning
Inference
2x
H.264 & H.265, SD & HD
Stabilization and
Enhancements
Resize, Filter, Search,
Auto-Enhance
Preliminary specifications. Subject to change.
9
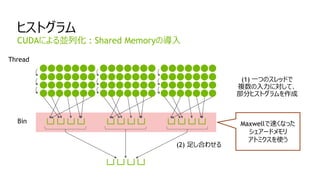
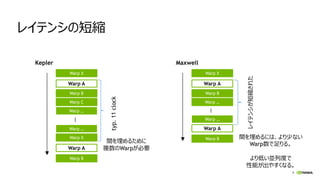
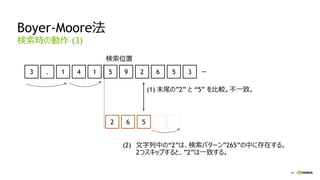
レイテンシの短縮
間を埋めるために
複数のWarpが必要
Warp X
Warp A
WarpB
Warp C
Warp …
Warp …
Warp X
Warp A
Warp B
…
typ.11clock
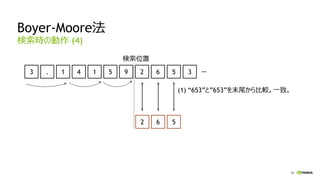
間を埋めるには、より少ない
Warp数で足りる。
より低い並列度で
性能が出やすくなる。
Warp X
Warp A
Warp B
Warp …
Warp …
Warp A
Warp B
…
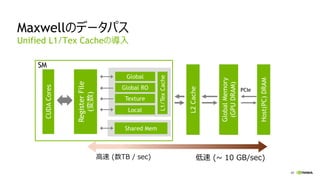
レイテンシが短縮された
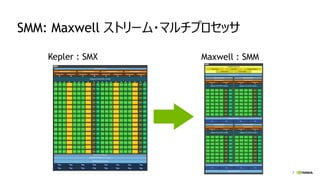
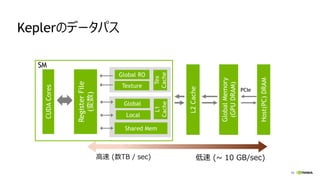
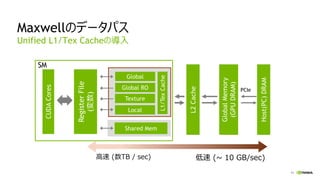
Kepler Maxwell
16
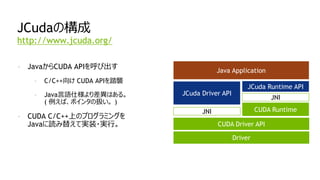
JCudaの構成
- JavaからCUDA APIを呼び出す
-C/C++向け CUDA APIを踏襲
- Java言語仕様より差異はある。
( 例えば、ポインタの扱い。 )
- CUDA C/C++上のプログラミングを
Javaに読み替えて実装・実行。
http://www.jcuda.org/
CUDA Driver API
CUDA Runtime
Driver
JNI
JCuda Driver API
JCuda Runtime API
JNI
Java Application
58
実行結果
処理 GPU 実行時間
CPU(4CORE)
実行時間
CPU(1CORE)
実行時間
CUDA初期化85 ms - -
カーネルコンパイル (537 ms*) - -
デバイスメモリアロケート 8 ms - -
文字列(PI)のロード 333 ms 343 ms 364 ms
GPUへと文字列を転送 75 ms - -
検索パターン設定 1 ms - -
検索実行 42 ms 103 ms 613 ms
終了処理 43 ms - -
総計 587 ms 446 ms 977 ms
検索自体は速い
もっと速くしたい
転送はGPUのみ
短くしたい
* カーネルコンパイルは、事前に実行可能なため、処理時間の総計から省いています。
61
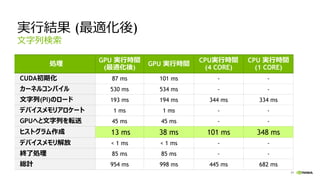
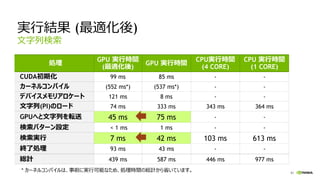
実行結果 (最適化後)
処理
GPU 実行時間
(最適化後)
GPU実行時間
CPU実行時間
(4 CORE)
CPU 実行時間
(1 CORE)
CUDA初期化 99 ms 85 ms - -
カーネルコンパイル (552 ms*) (537 ms*) - -
デバイスメモリアロケート 121 ms 8 ms - -
文字列(PI)のロード 74 ms 333 ms 343 ms 364 ms
GPUへと文字列を転送 45 ms 75 ms - -
検索パターン設定 < 1 ms 1 ms - -
検索実行 7 ms 42 ms 103 ms 613 ms
終了処理 93 ms 43 ms - -
総計 439 ms 587 ms 446 ms 977 ms
文字列検索
* カーネルコンパイルは、事前に実行可能なため、処理時間の総計から省いています。
61.
62
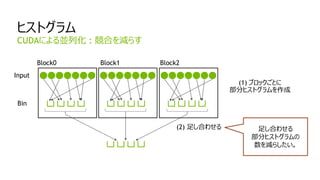
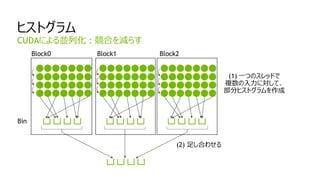
GPUの性能を有効に使うために
- GPU上の検索は、速い。
- GPU(最適化後): 7 ms, CPU (4 core) 103 ms
- GPUへの文字列転送 : 45 ms
- CPUには存在しない処理であり、GPUの性能が活かせない要因となる。
- GPUを有効に使うには:
データの再利用などを考慮し、「転送量を少なく」、かつ、「GPU上での処理量を多く」する。
文字列検索
71
実行結果 (最適化後)
処理
GPU 実行時間
(最適化後)
GPU実行時間
CPU実行時間
(4 CORE)
CPU 実行時間
(1 CORE)
CUDA初期化 87 ms 101 ms - -
カーネルコンパイル 530 ms 534 ms - -
文字列(PI)のロード 193 ms 194 ms 344 ms 334 ms
デバイスメモリアロケート 1 ms 1 ms - -
GPUへと文字列を転送 45 ms 45 ms - -
ヒストグラム作成 13 ms 38 ms 101 ms 348 ms
デバイスメモリ解放 < 1 ms < 1 ms - -
終了処理 85 ms 85 ms - -
総計 954 ms 998 ms 445 ms 682 ms
文字列検索
71.
72
Java CUDA プログラミング
-JCudaの利用で、Javaで、CUDAアプリケーションを実装できる。
- CUDA Driver・Runtime APIを使用。
- 文字列検索、ヒストグラム作成とも、GPU上の処理は高速。
- 事前のカーネルコンパイル、メモリ転送量の削減など、工夫する必要あり。
(通常のCUDA C/C++プログラミングでも、同様の考慮を行っている。)
まとめ













![19
プログラム例
- 配列に収められたa[i], b[i] を、並列に加算し、c[i] を得る
配列の和
c[i] = a[i] + b[i]](https://image.slidesharecdn.com/2cudaforjavar1-160128054404/85/Maxwell-Java-CUDA-19-320.jpg)
![20
配列の和:メモリの扱い
ホスト(CPU) デバイス(GPU)
カーネル
dc[i] = da[i] + db[i]
*a, *bに値を設定
ホスト->デバイス転送 a-> da, b->db
ホスト <- デバイス転送 c <- dc
float *da, *db, *dc をアロケート (デバイスメモリ)
結果表示・検証
float *da, *db, *dc を開放 (デバイスメモリ)
float *a, *b, *c を開放
カーネル実行依頼
float *a, *b, *c をアロケート](https://image.slidesharecdn.com/2cudaforjavar1-160128054404/85/Maxwell-Java-CUDA-20-320.jpg)
![21
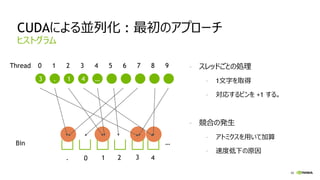
並列化(カーネル設計)
- 1 スレッドで、一つの要素の和を計算。
- 複数のブロックに分割。
1 Blockあたりの最大スレッド数は、1024。 (図はBlockあたり4スレッドとした)
a[i]
b[i]
c[i]
Block[0]
0 1 2 3
+ + + +
15 14 13 12
Block[1]
4 5 6 7
+ + + +
11 10 9 8
Block[2]
8 9 10 11
+ + + +
7 6 5 4
Block[3]
12 13 14 15
+ + + +
3 2 1 0
Thread ID ? 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15](https://image.slidesharecdn.com/2cudaforjavar1-160128054404/85/Maxwell-Java-CUDA-21-320.jpg)
![23
カーネル実装
__global__
void addArrayKernel(float *dc, const float *da, const float *db, int size) {
/* Global IDを算出 */
int globalID = blockDim.x * blockIdx.x + threadIdx.x;
if (globalID < size) { /* 範囲チェック */
/* 自スレッド担当の要素のみ、処理 */
dc[globalID] = da[globalID] + db[globalID];
}
}](https://image.slidesharecdn.com/2cudaforjavar1-160128054404/85/Maxwell-Java-CUDA-23-320.jpg)





![31
3. CUDAのモジュール、カーネルは、自前でロードする。
/* 作成したPTXは、ptxに収められている */
byte[] ptx = …;
/* モジュールの作成とロード */
CUmodule =new CUmodule();
cuModuleLoadData(module, ptx);
/* カーネル関数へのポインタを取得 */
CUfunction function = new CUfunction();
cuModuleGetFunction(function, module, "add");
CUDA C/C++ Runtime API との違い
CUDA Driver APIを用いる。
- Moduleの作成 (PTXのロード)
- カーネル関数へのポインタを取得
*CUDA Runtime APIを使用している場合に
は、自動的に実行される。](https://image.slidesharecdn.com/2cudaforjavar1-160128054404/85/Maxwell-Java-CUDA-30-320.jpg)
![32
3. CUDAのモジュール、カーネルは、自前でロードする。
extern “C” /* 関数シンボルを ”add” とする。 */
__global__
void add(float *dc, const float *da, const float *db, int size) {
/* Global IDを算出 */
int globalID = blockDim.x * blockIdx.x + threadIdx.x;
if (globalID < size) { /* 範囲チェック */
/* 自スレッド担当の要素のみ、処理 */
dc[globalID] = da[globalID] + db[globalID];
}
}
カーネルソース](https://image.slidesharecdn.com/2cudaforjavar1-160128054404/85/Maxwell-Java-CUDA-31-320.jpg)
![33
4.ネイティブポインタは、Pointerクラスで扱う。
/* ホスト(CPU)側の配列 */
byte[] inputA =new byte[numElements];
(… 略 …)
/* デバイスメモリをアロケート */
Pointer dInputA = new Pointer();
int bufSize = Sizeof.FLOAT * numElements;
cudaMalloc(dInputA, bufSize);
/* デバイスメモリdInputAに、ホストメモリ inputAを転送 */
cudaMemcpy(dInputA, Pointer.to(inputA), bufSize,
cudaMemcpyHostToDevice);
CUDA C/C++ Runtime API との違い
jcuda.Pointer クラス
ネイティブポインタを保持する。
ネイティブポインタへの参照としても
利用される。
jcuda.Pointer.to()メソッド
ホスト側オブジェクトのネイティブポインタを
Pointerクラスのインスタンスとして取得](https://image.slidesharecdn.com/2cudaforjavar1-160128054404/85/Maxwell-Java-CUDA-32-320.jpg)
![34
5. カーネルは、Driver APIを使用してローンチする
int blockDim = 128;
int gridDim = (numElements + blockDim - 1) / blockDim;
Pointer kernelParameters = Pointer.to(
Pointer.to(new int[]{numElements}),
Pointer.to(dInputA), Pointer.to(dInputB),
Pointer.to(dOutput)
);
cuLaunchKernel(addFunction,
gridDim, 1, 1, // GridDim
blockDim, 1, 1, // BlockDim
0, null, // シェアードメモリのサイズ、ストリーム
kernelParameters, null // カーネル引数
);
CUDA C/C++ Runtime API との違い
カーネル引数
Pointerの配列へのPointerで定義する。
カーネルローンチ
cuLaunchKernel()関数を用いる。
サンプルコードは、
add<<<gridDim, blockDim>>>
(nElements, dC, dA, dB)に対応](https://image.slidesharecdn.com/2cudaforjavar1-160128054404/85/Maxwell-Java-CUDA-33-320.jpg)



![38
ブレークポイントの挿入
extern “C” /* 関数シンボルを ”add” とする。 */
__global__
void add(float *dc, const float *da, const float *db, int size) {
/* Global IDを算出 */
int globalID = blockDim.x * blockIdx.x + threadIdx.x;
if (globalID < size) { /* 範囲チェック */
/* 自スレッド担当の要素のみ、処理 */
asm volatile (“brkpt;”); /* ブレークポイントを挿入 */
dc[globalID] = da[globalID] + db[globalID];
}
}
デバッグ事前準備](https://image.slidesharecdn.com/2cudaforjavar1-160128054404/85/Maxwell-Java-CUDA-37-320.jpg)






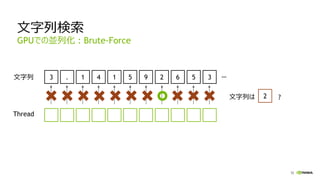
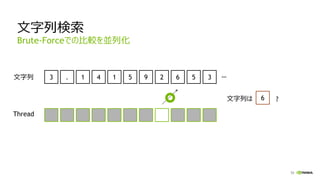
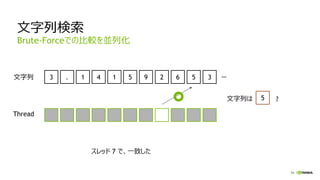
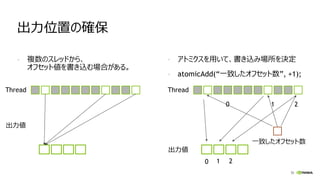
![56
カーネルソース
extern "C“ __global__
void searchPatternKernel_bruteForce
(int *d_nFound, int *d_offsets, int nMaxMatched,
const unsigned char *d_pattern, int patternLength,
const unsigned char *d_text, int searchLength) {
/* 検索の先頭位置を算出 */
int gid = blockDim.x * blockIdx.x + threadIdx.x;
/* 自スレッドが検索範囲にあることを確認 */
if (gid < searchLength) {
bool matched = true;
/* 文字列の検索開始位置のポインタを取得 */
const unsigned char *d_myPos = &d_text[gid];
/* ループで一文字づつ検索 */
for (int idx = 0; idx < patternLength; ++idx) {
if (d_pattern[idx] != d_myPos[idx]) {
matched = false; /* 一致せず */
break;
}
}
/* 一致していたら */
if (matched) {
/* アトミクスを用いて、出力場所を算出 */
int offsetPos = atomicAdd(d_nFound, 1);
/* 出力場所を取得 */
if (offsetPos < nMaxMatched)
d_offsets[offsetPos] = gid;
}
}
}](https://image.slidesharecdn.com/2cudaforjavar1-160128054404/85/Maxwell-Java-CUDA-55-320.jpg)





![65
JavaにおけるCPU実装
/* ヒストグラム作成 */
public static int[] make(byte[] sequence) {
/* ヒストグラム用の領域を作成 */
int[] histgram = new int[256];
for (int idx = 0; idx < sequence.length; ++idx) {
/* 要素に対応するビンに 1 を足す */
int binIdx = sequence[idx];
++histgram[binIdx];
}
return histgram;
}
シングルスレッド版](https://image.slidesharecdn.com/2cudaforjavar1-160128054404/85/Maxwell-Java-CUDA-64-320.jpg)