Download as PDF, PPTX



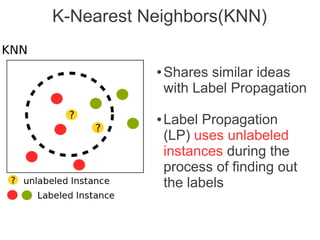
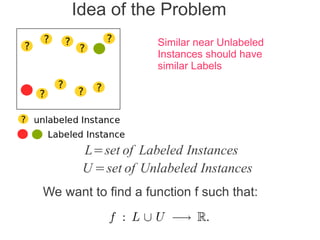
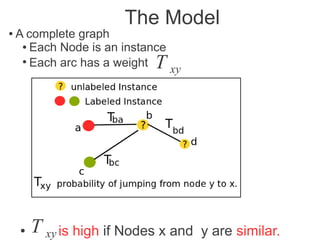

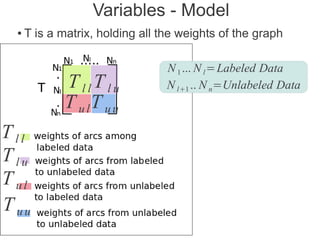
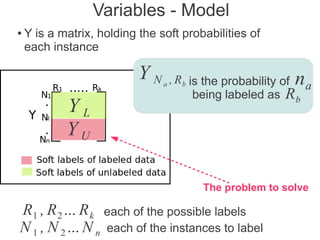
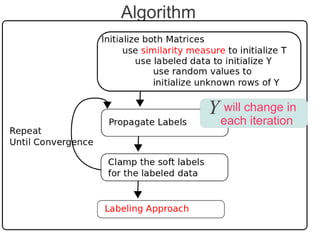


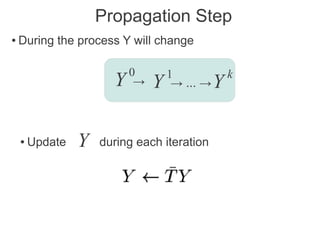









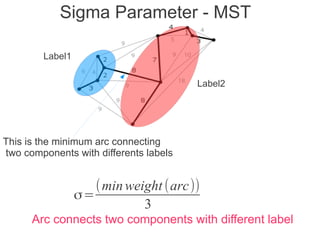

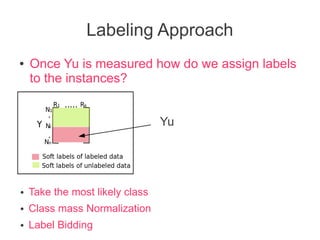

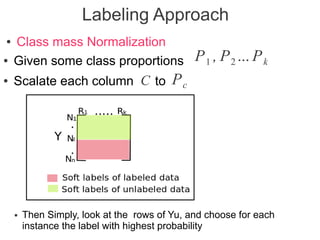


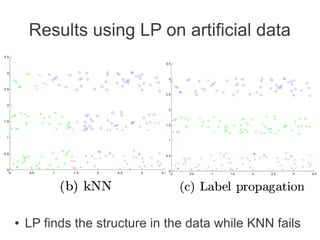
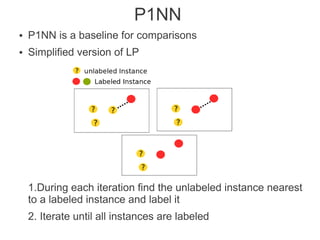
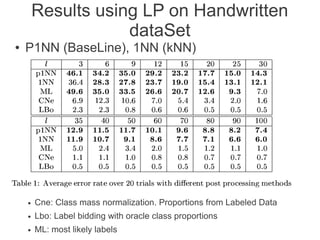
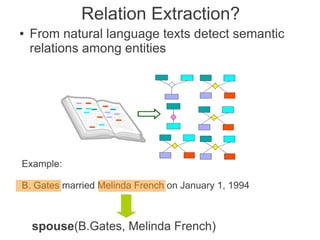





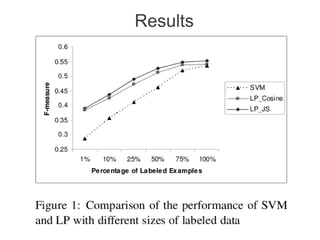
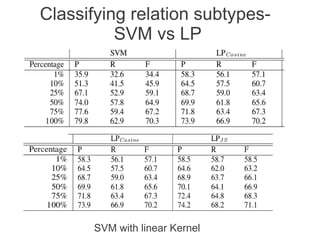
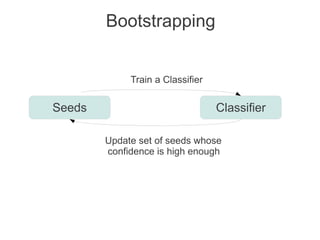
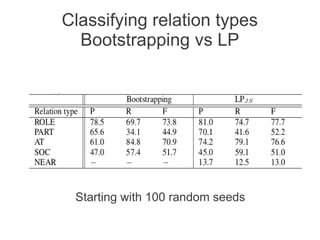



Label propagation is a semi-supervised learning algorithm that propagates labels from a small set of labeled data points to unlabeled data points. The algorithm constructs a graph with nodes for each data point and weighted edges representing similarity between points. It then iteratively propagates the labels across the graph from labeled to unlabeled points until convergence, resulting in "soft" probabilistic labels for all points. The algorithm aims to minimize an energy function that encourages points connected by strong edges to receive similar labels. It performs well with limited labeled data by leveraging the graph structure to make predictions for unlabeled points.


![[DL輪読会]Conditional Neural Processes](https://cdn.slidesharecdn.com/ss_thumbnails/conditionalneuralprocesses-180727001730-thumbnail.jpg?width=640&height=640&fit=bounds)







































![[Dl輪読会]semi supervised learning with context-conditional generative adversari...](https://cdn.slidesharecdn.com/ss_thumbnails/dlsemi-supervisedlearningwithcontext-conditionalgenerativeadversarialnetworks-161111054049-thumbnail.jpg?width=640&height=640&fit=bounds)

























![Reproducible datascience [with Terraform]](https://cdn.slidesharecdn.com/ss_thumbnails/reproduceabledatascience1-180630074643-thumbnail.jpg?width=640&height=640&fit=bounds)

























