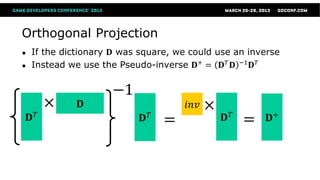
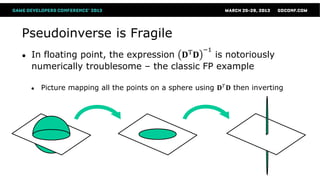
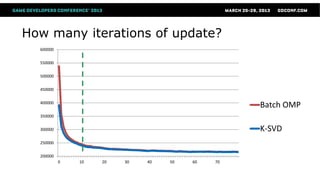
This document summarizes orthogonal matching pursuit (OMP) and K-SVD, which are algorithms for sparse encoding of signals using dictionaries. OMP is a greedy algorithm that selects atoms from an overcomplete dictionary to sparsely represent a signal. It uses an orthogonal projection to the residual to ensure selected atoms are not reselected. K-SVD learns an optimized dictionary for sparse encoding by iteratively sparse encoding training data and updating dictionary atoms to minimize representation error.










































![Block compression of Voxel grids
● “A Compression Domain output-sensitive volume rendering architecture
based on sparse representation of voxel blocks” Gobbetti, Guitian and
Marton [2012]
● COVRA sparsely represents each voxel block as a dictionary of 8x8x8
blocks and three coefficients
● The voxel patch is reconstructed only inside the GPU shader so voxels are
decompressed just-in-time
● Huge bandwidth improvements, larger models and faster rendering](https://image.slidesharecdn.com/gdc2013-omp-and-k-svd-130406223252-phpapp02/85/omp-and-k-svd-Gdc2013-46-320.jpg)























































