Download as PDF, PPTX



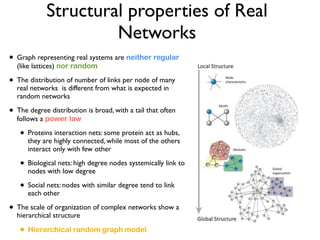
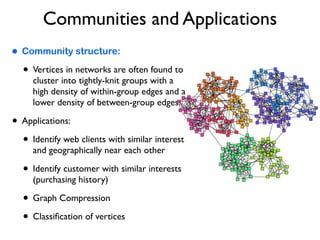
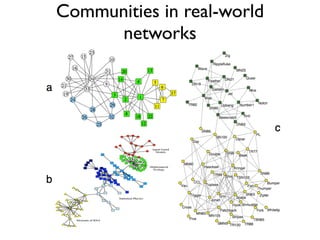








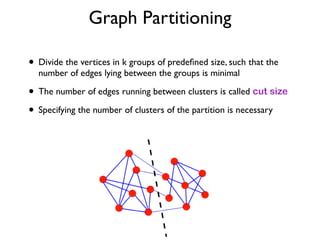


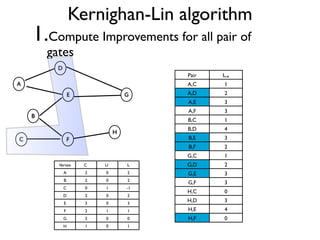
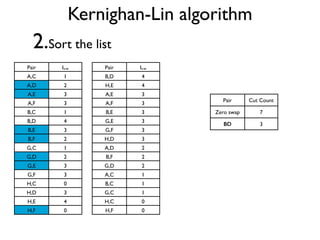
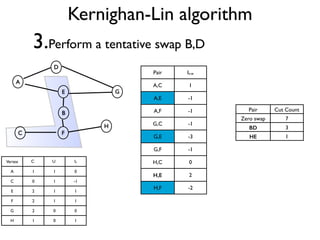
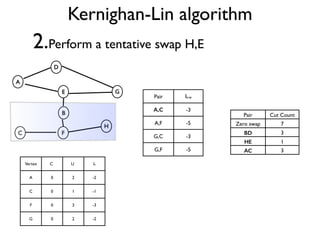
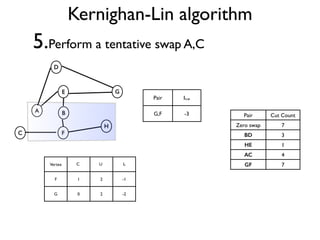
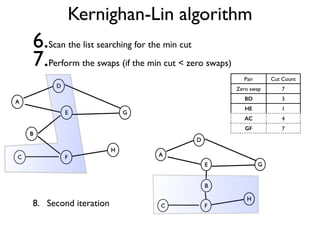

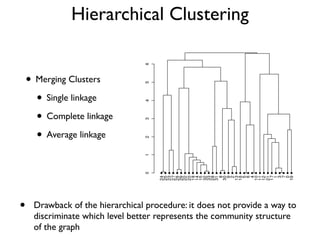


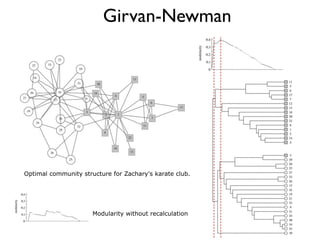

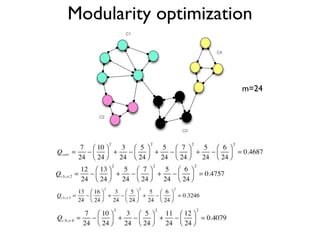
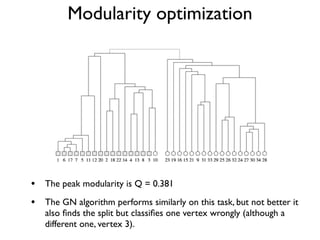
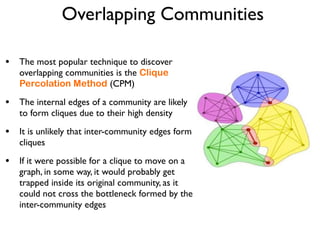
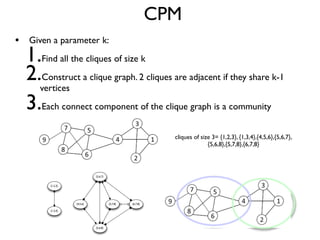






The document discusses community detection in graphs, highlighting how vertices in networks tend to cluster into groups with a high internal edge density. It covers various methods for detecting communities, such as the Kernighan-Lin algorithm, hierarchical clustering, and the Girvan-Newman method, while also addressing complexities like overlapping communities and the evaluation of detection algorithms. Additionally, it emphasizes the importance of modularity in assessing community structures and presents examples illustrating these concepts.



































































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)