cvpaper.challenge の Meta Study Group 発表スライド cvpaper.challenge はコンピュータビジョン分野の今を映し、トレンドを創り出す挑戦です。論文サマリ・アイディア考案・議論・実装・論文投稿に取り組み、凡ゆる知識を共有します。2019の目標「トップ会議30+本投稿」「2回以上のトップ会議網羅的サーベイ」 http://xpaperchallenge.org/cv/



![画像識別の進化
• DNN構造の深化
– 2014年頃から「構造をより深くする」ための知⾒が整う
– 現在(主に画像識別で)主流なのはResidual Network
AlexNet [Krizhevsky+, ILSVRC2012]
VGGNet [Simonyan+, ILSVRC2014]
GoogLeNet [Szegedy+, ILSVRC2014/CVPR2015]
ResNet [He+, ILSVRC2015/CVPR2016]
ILSVRC2012 winner,DLの⽕付け役
16/19層ネット,deeperモデルの知識
ILSVRC2014 winner,22層モデル
ILSVRC2015 winner, 152層!(実験では103+層も)
4](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-4-320.jpg)
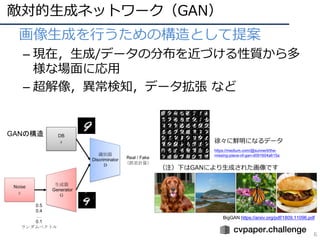
![他タスクへの適⽤
• 画像識別でうまくいくとタスク転⽤が起こる
– R-CNN: 物体検出
– FCN: セマンティックセグメンテーション
– CNN+LSTM(Seq2Seq): 画像説明⽂
– Two-Stream CNN: 動画認識
Person
Uma
Show and Tell [Vinyals+, CVPR15]
R-CNN [Girshick+, CVPR14]
FCN [Long+, CVPR15]
Two-Stream CNN [Simonyan+, NIPS14]
5](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-5-320.jpg)
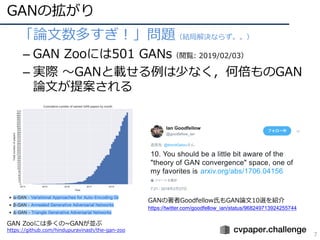




![GANの主要な流れ
12
• 論⽂リスト
1. GAN(オリジナルのGAN)
• [Goodfellow, NIPS2014] https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf
2. DCGAN(畳み込み層の使⽤)
• [Radford, ICLR2016] https://arxiv.org/abs/1511.06434
3. Pix2Pix(pixel同⼠が対応付くという意味でConditionalなGAN)
• [Isola, CVPR2017] https://arxiv.org/abs/1611.07004
4. CycleGAN(pix2pixの教師なし版)
• [Zhu, ICCV2017] https://arxiv.org/pdf/1703.10593.pdf
5. ACGAN(カテゴリ識別も同時に実施してコンディションとした)
• [Odera, ICML2017] https://arxiv.org/abs/1610.09585
6. WGAN/SNGAN(学習安定化)
• [Arjovsky, ICML2017] http://proceedings.mlr.press/v70/arjovsky17a.html
• [Miyato, ICLR2018] https://arxiv.org/abs/1802.05957
7. PGGAN(⾼精度化)
• [Karras, ICLR2018] https://arxiv.org/abs/1710.10196
8. Self-Attention GAN(アテンション機構を採⽤)
• [Zhang, arXiv 1805.08318] https://arxiv.org/abs/1805.08318
9. BigGAN(超⾼精細GAN)
• [Brock, ICLR2019] https://arxiv.org/abs/1809.11096
# 2018年10⽉時点での調査](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-12-320.jpg)
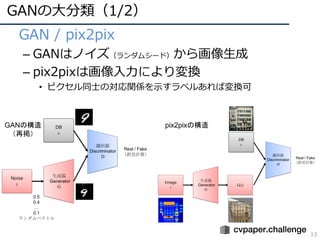

15
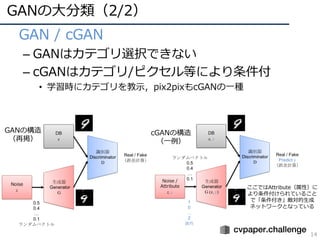
• オリジナルのGAN
– Generator(G):DB(x)の分布を再現,画像を⽣成
– Discriminator(D):DBから⼊⼒されたものかGにより⽣成された
画像かを判断
– Min-Maxを解くことでデータ分布を再現,出⼒空間を調整
GANの構造
(再掲)
Dを最⼤化(GはDを”⼤きく”騙したい)
Gを最⼩化(GはDBの分布にフィットさせたい)
• Gはノイズzを⼊⼒として画像⽣成
• Pz(z)は⽣成された出⼒分布
• Pdata(x)はDBの分布](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-15-320.jpg)
![DCGAN(Deep Convolutional GAN)[Radford, ICLR2016] (2/9)
16
• GANの構造を深層畳み込みネットに置き換え
– Conv layerの使⽤(構造は下図)
• Linear/Pooling layerをConv layerに置き換え
• 学習安定化のため,Batch Norm.もD/Gに追加
• 活性化関数は,G: ReLU, D: LeakyReLU
– 教師なし特徴表現
• 学習済みのDを使⽤したら,82.8%@CIFAR-10
• SVHNについても同様に良好な精度
4層の畳み込み構造により
構成されている](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-16-320.jpg)
![DCGAN(Deep Convolutional GAN)[Radford, ICLR2016] (2ʼ/9)
17
• GANの構造を深層畳み込みネットに置き換え
– 算術的画像⽣成(右下図)
• Word2Vecのように加算/減算による画像⽣成が可能
• 顔の回転もinterpolationで表現可能
⾜し算,引き算など直感的な表現
で画像⽣成を実現した?](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-17-320.jpg)
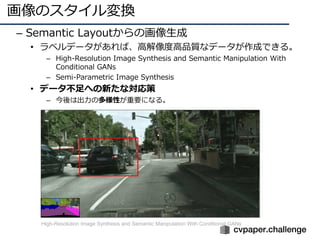
![Pix2Pix[Isola, CVPR2017] (3/9)
18
• ピクセル同⼠が対応した画像変換
– ピクセル間で条件付けを⾏なったGANと捉えることができる
• 従来は別々に議論されてきた画像変換の学習を単⼀の枠組みで実施
• Enc-Dec構造のものだけでなく,U-NetをGとして採⽤
• ラベルは画像と変換した画像(下図のように⼊⼒)
単⼀の枠組み(単⼀モデル
でない)で複数のピクセル
同⼠の相互画像変換に対応.
ラベルóRGB画像,グレー
スケール画像óカラー画像,
線画ó物体画像など.
Twitterでは#edges2cats
が有名.](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-18-320.jpg)
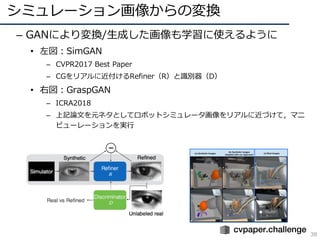
![CycleGAN[Zhu, ICCV2017] (4/9)
19
• 画像間の教師がない場合のpix2pix
– 2つのドメイン変換に関する関数を実装(G: X->Y, F: Y->X)
• X->Y->Xʻ/Y->X->YʼにおいてXとXʻ, YとYʼの誤差を取る(Cycle
Consistency Loss)
• Discriminator Dx, Dyも含む実画像なのか,変換画像なのかを評価
• ⽬的関数はX/Yに対するAdversarial LossとCycle Consistency Lossを
同時最適化
– 実験
• AMTによりチューリングテストを実施
• 実験ではBiGAN, CoGAN, feature loss + GAN, SimGANと⽐較
pix2pixのような,多様なドメインの
変換という特性を引き継いでいる.こ
の画像変換を教師なしで⾏うところが
新規性である.SNS上ではウマをシマ
ウマにするという謎技術(?)を駆使
して論⽂を宣伝していた.](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-19-320.jpg)
![ACGAN(Auxiliary Classifier GAN)[Odera, ICML2017] (5/9)
20
• 条件付きGANを広めた技術?
– GANのタスクのみでなく,カテゴリ識別もタスクとして追加
– ⽣成画像の解像度を向上(64 [pixel] >> 128 [pixel])
• 初めてデータベースとしてImageNetを利⽤
– Dに対してクラスラベルの確率分布を返却させて誤差を計算
cGANの構造
(再掲) • 実装上の⼊⼒はカテゴリとノイズを
連結したベクトル
• Gはカテゴリも加味して画像を⽣成
• Dの出⼒はカテゴリとReal/Fake](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-20-320.jpg)
![WGAN(Wasserstein GAN)[Arjovsky, ICML2017]
SNGAN(Spectral Normalization GAN)[Miyato, ICLR2018]
21
• GANの学習安定化
– WGAN
• 分布間距離の⽐較⼿法であるEMD(Earth Mover Distance)を導⼊して
学習安定化
• 5回Criticを学習、1回Gを学習の繰り返し
• リプシッツ連続性(関数の傾きが有界に収まる; sigmoid, reluはリプ
シッツ連続)を⽤いてパラメータの範囲を決定すると学習が安定化する
• BN不要
• 従来はDに合わせてGが学習していたが、WGANはGを基準にしてDを学
習する
– SNGAN
• リプシッツ制約(すみません,あまり理解できていないデス)が重要でDの正則化として効果アリ
– Dに対して各層にSpectral Normalizationを導⼊すると学習がうまく進⾏
• BNなど従来の学習安定化⼿法を⽤いずに安定化
• 恐らく初めて1モデルでImageNetの1,000カテゴリを⽣成できたと評価
(6/9)](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-21-320.jpg)

22
– 「徐々に成⻑する」要素(右図)により,
• 画像⽣成に対する学習の安定性を⾼め学習の収束を速くした
• 結果的に,画像⽣成の解像度を⾼めることに貢献
– 結果
• CIFAR-10についてはSoTA(IS: 8.80)
• 収束が早くなる(2 – 6 times faster)
その他,⼯夫点
• 層を追加する際に重み(α)を増加
• Minibatch discriminationを単純化した
Minibatch standard deviation:ミニ
バッチ内で標準偏差を計算/平均してD
の最終層に統合
• 層ごとの正則化を⾏うパラメータによ
り学習率を調整](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-22-320.jpg)
![SAGAN(Self-Attention GAN)[Zhang, arXiv2018] (8/9)
23
• アテンション機構を⽤いたGANの⾼精細化
– 主に対象物に着⽬して詳細を描画
• 画像内のパターンにおける依存関係の抽出,計算の効率性の⾯で
有利
– IS: 52.52 (higher is better), FID: 18.65 (lower is better)
• 前述のSNGANは36.80@IS, 27.62@FID
SAGANにおけるアテンションモジュール
アテンションによる着⽬点](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-23-320.jpg)

24
• 最も⾼精細な画像を⽣成するGAN(2019年2⽉現在)
– Bigと呼ばれる理由
• 512グラフィックボード(実際はGoogle社のTensor Processing Unit)使⽤
• 画像DBには3億枚画像含むJFT-300Mを採⽤
• バッチサイズ2,048,画像サイズ 512 [pixel]四⽅
– Truncated Trick
• モード崩壊を防ぐための技術
• 切断正規分布の範囲調整により,多様性と画質を確保
BigGANの出⼒; ⼈間が⾒ても実
際の写真か⽣成結果なのか判別困
難
左図はGoogle Collaboratoryにて出⼒
https://colab.research.google.com/github/te
nsorflow/hub/blob/master/examples/colab/b
iggan_generation_with_tf_hub.ipynb](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-24-320.jpg)












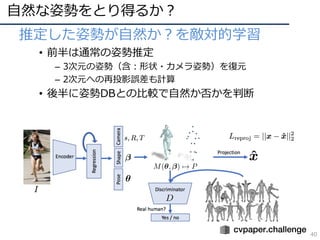
![教師あり学習 vs. 無教師/弱教師
39
• 少量/無 ラベルで教師有りに勝つ!(というモチベーション)
• Cut/Paste学習:既存のセグメントラベルを切り貼り
してGANにより⾃然か否かを判断
– ⾃然:スケールやコンテキストのズレがないか?
• 教師なし学習で90%の精度まで来た
[Remez+, ECCV18]Oral
Cut/Pasteで既存セグメントラベルを増加,GANによりスケールやコンテキストが⾃然かどうか
を判断することで効果的に学習サンプルを⽣成](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-39-320.jpg)









![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第2回3D勉強会 研究紹介] Neural 3D Mesh Renderer (CVPR 2018)](https://cdn.slidesharecdn.com/ss_thumbnails/201807263dv-180728060959-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]HoloGAN: Unsupervised learning of 3D representations from natural images](https://cdn.slidesharecdn.com/ss_thumbnails/hologanslideshare-190906010228-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL Hacks]Self-Attention Generative Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/self-attentiongenerativeadversarialnetworks-180730075733-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Toward Multimodal Image-to-Image Translation (NIPS'17)](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180514071433-thumbnail.jpg?width=640&height=640&fit=bounds)


