Download as PDF, PPTX



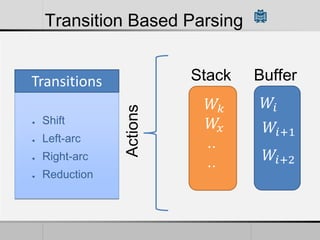




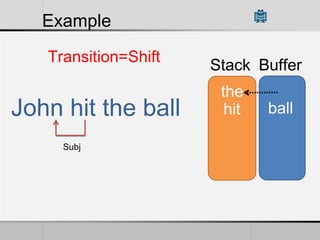
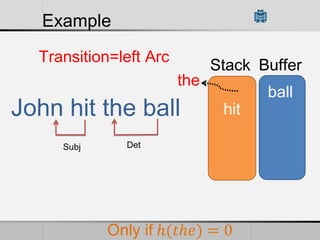
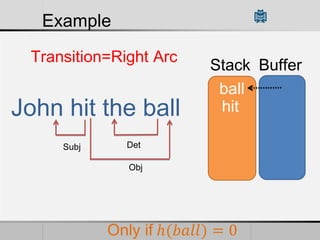
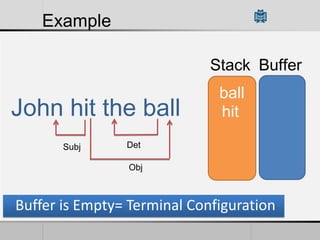
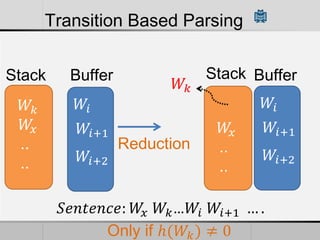




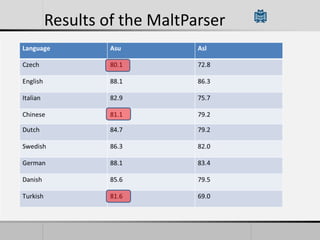


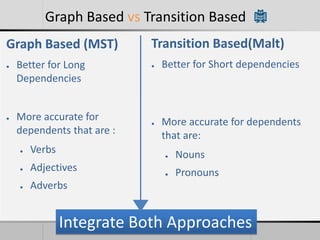
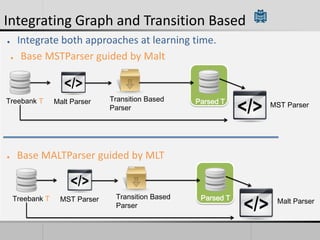

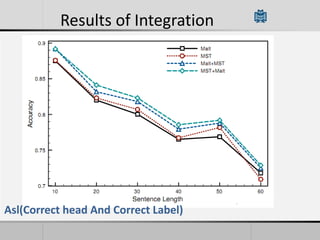
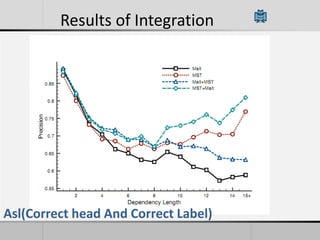
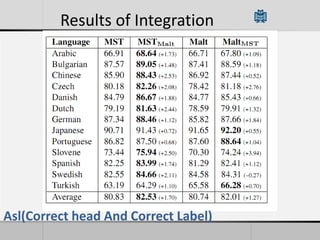


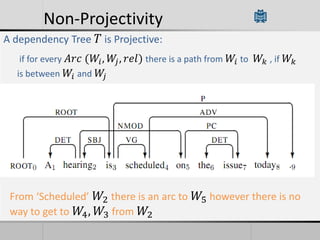
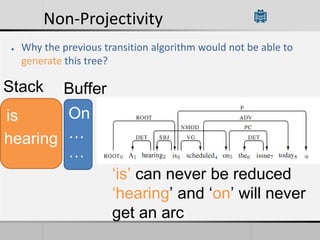
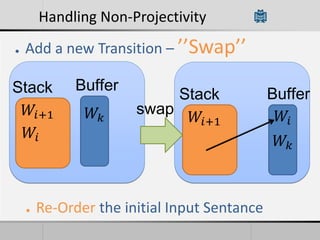
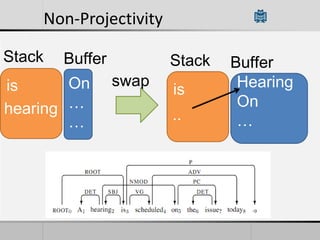

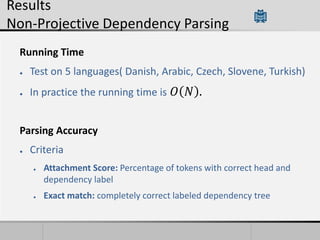
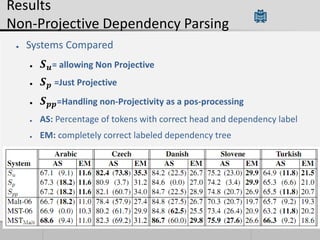



Transition-based dependency parsing uses a stack and buffer to incrementally build dependency trees for sentences. It handles both projective and non-projective structures by allowing swap transitions to reorder words. Integrating graph-based and transition-based parsing leads to improved accuracy by combining their strengths. While transition-based parsing runs in linear time on projective structures, non-projective parsing has a worst case quadratic time complexity but in practice remains linear time.















































![Reproducible datascience [with Terraform]](https://cdn.slidesharecdn.com/ss_thumbnails/reproduceabledatascience1-180630074643-thumbnail.jpg?width=640&height=640&fit=bounds)

























