Recommended
PPTX
PPTX
PPTX
PPTX
PPTX
PPTX
PPTX
PPTX
データサイエンス概論第一=2-1 データ間の距離と類似度
PDF
PDF
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
PDF
PDF
Domain Adaptation 発展と動向まとめ(サーベイ資料)
PDF
PDF
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
PPTX
PDF
PPTX
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
PDF
PDF
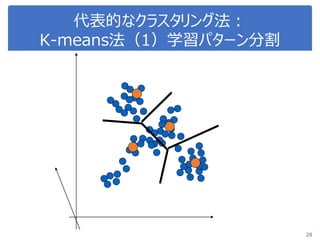
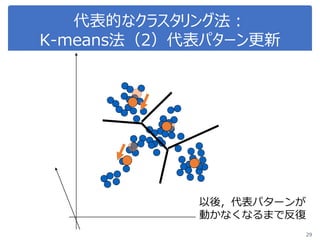
PPTX
PPTX
PDF
PPTX
PPTX
Curriculum Learning (関東CV勉強会)
PDF
PDF
PDF
More Related Content
PPTX
PPTX
PPTX
PPTX
PPTX
PPTX
PPTX
PPTX
データサイエンス概論第一=2-1 データ間の距離と類似度
What's hot
PDF
PDF
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
PDF
PDF
Domain Adaptation 発展と動向まとめ(サーベイ資料)
PDF
PDF
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
PPTX
PDF
PPTX
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
PDF
PDF
PPTX
PPTX
PDF
PPTX
PPTX
Curriculum Learning (関東CV勉強会)
PDF
Similar to 画像処理応用
PDF
PDF
PDF
PPTX
PDF
PPTX
PDF
PPTX
PDF
PDF
PPTX
Deep Learningで似た画像を見つける技術 | OHS勉強会#5
PPTX
PPTX
Developer IO 2024 Odyssey SAMを応用したコンピュータビジョンの話
PDF
Opencv object detection_takmin
PDF
PDF
PDF
【DLゼミ】XFeat: Accelerated Features for Lightweight Image Matching
PDF
PDF
PDF
Pythonで操るSAS Viyaの画像処理技術入門編
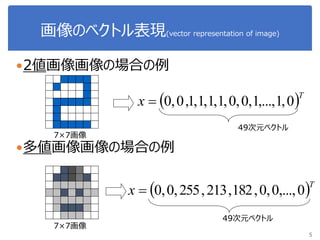
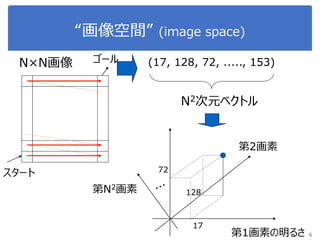
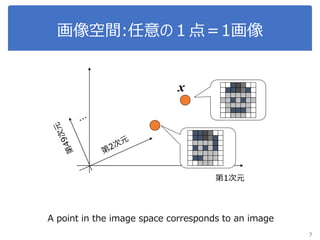
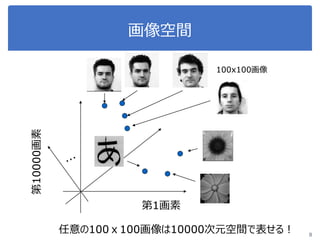
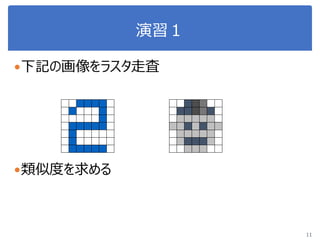
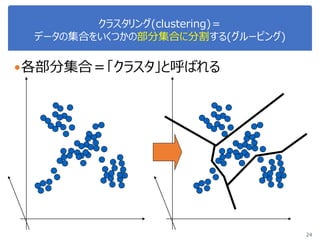
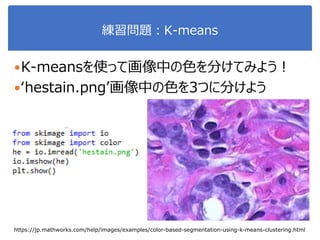
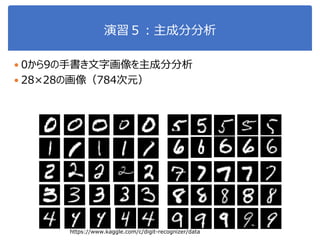
画像処理応用 1. 2. 3. 4. 5. 画像のベクトル表現(vector representation of image)
2値画像画像の場合の例
多値画像画像の場合の例
5
T
x 0,1,...,1,0,0,1,1,1,1,0,0
T
x 0,...,0,0,182,213,255,0,0
49次元ベクトル
49次元ベクトル
7×7画像
7×7画像
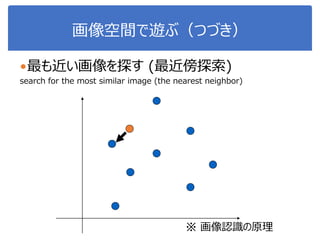
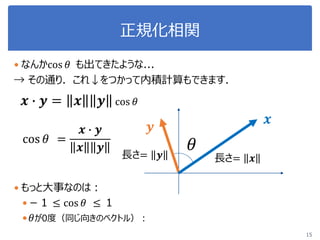
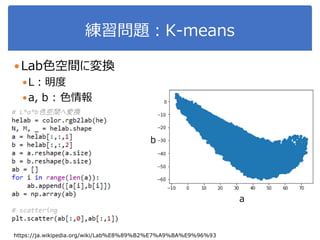
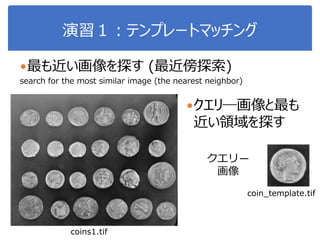
6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 正規化相関
なんかcos 𝜃 も出てきたような...
→ その通り.これ↓をつかって内積計算もできます.
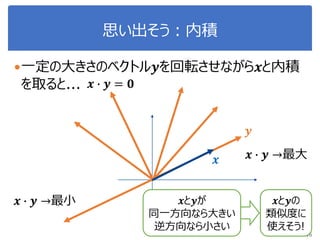
もっと大事なのは:
-1 ≤ cos 𝜃 ≤ 1
𝜃が0度(同じ向きのベクトル):
15
𝒙 ∙ 𝒚 = 𝒙 𝒚 cos 𝜃
𝒚
𝒙
長さ= 𝒙長さ= 𝒚
𝜃cos 𝜃 =
𝒙 ∙ 𝒚
𝒙 𝒚
16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 演習3
45
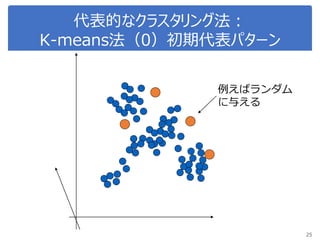
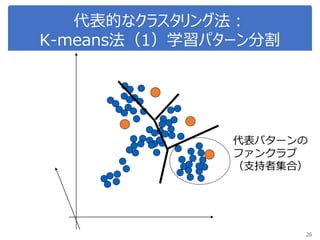
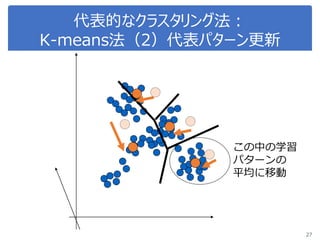
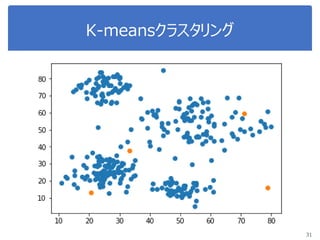
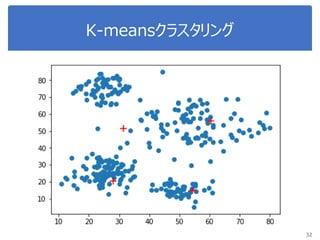
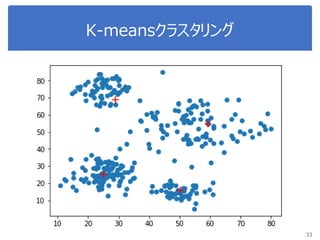
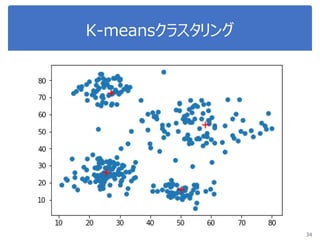
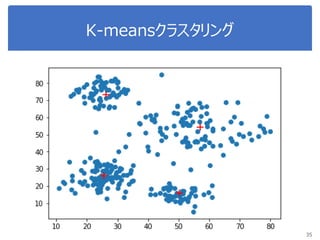
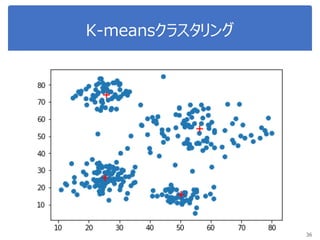
K-meansで画像圧縮
“bird.mat” のデータを読み込んで
データをノーマライズ
Reshape the array
Sklearn.clusterからKmeansをインポート, run Kmean with
16 clusters
Use kmeans.cluster_centers_ and kmeans_labels to
map each pixel to the centroid value.
Reshape the result and plot
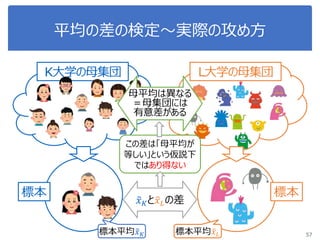
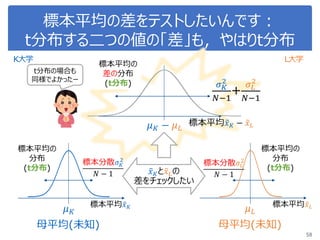
46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. Python で t 検定
Python で実行するのはとても簡単!
1. 差があるか確認したいデータを2つ用意
2. 有意水準を決定:5%
3. 2つのデータを関数に放り込む
4. t, p値が出る
5. p値が0.05(5%)以下なら、有意に差がある
59
0
t分布
赤い区間に入る確率:p値
t値
95%
p値
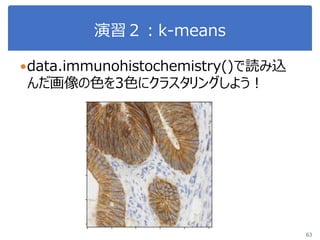
60. 61. 62. 63. 64. 演習3:k-means
64
0 ~ 9の数字画像に対して、k-meansでクラスタリングしてみよう
Numbersフォルダの下に数字ごとにフォルダが分かれて入っている
クラスタリングした結果をファイルとして出力して内容を確認してみよ
う。
data.immunohistochemistry()
65. 66.








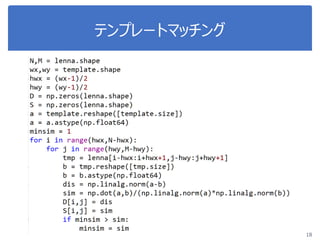




![K-means:プログラミング
30
アルゴリズム
ステップ0
繰り返し
•代表点の選択
•代表点の更新
•終了チェック
def clustering(vList,K)
Clist = np.c_[np.random.rand(K,N*M)]
Err = 0.1;
While dd > err
preClist = Clist;
CIList = selectCluster(vList,Clist)
Clist = updateCenter(CIList,vList)
dd = np.linalg.norm(preClist-Clist)
return Clist](https://image.slidesharecdn.com/imageprocessing2-190124085926/85/slide-30-320.jpg)































![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)






























