Downloaded 74 times




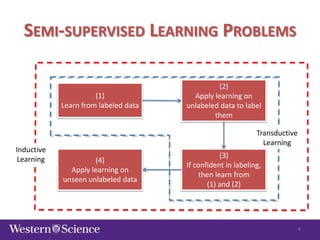


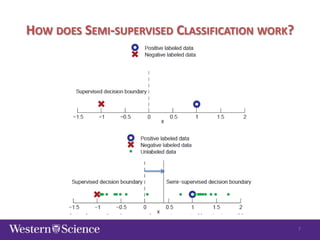









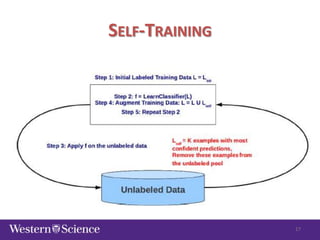





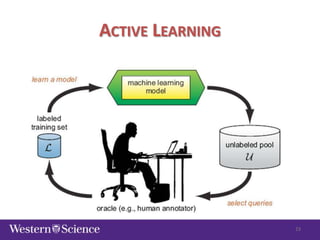















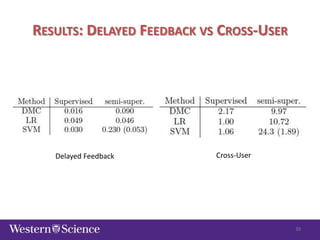





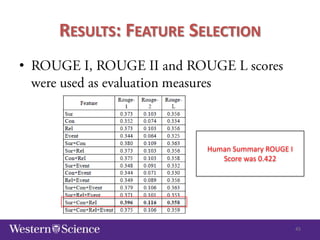
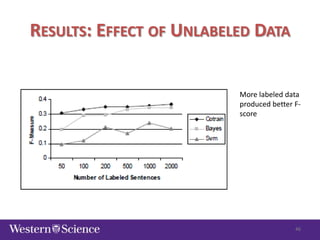
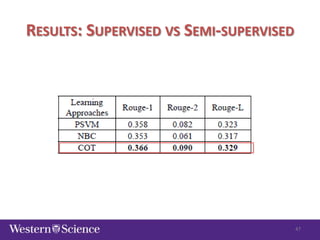
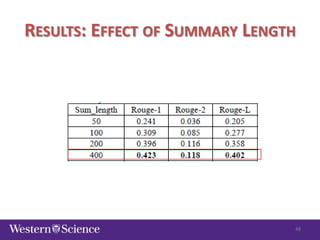





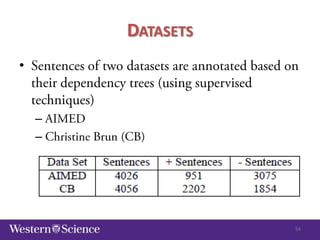
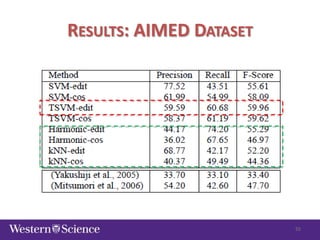
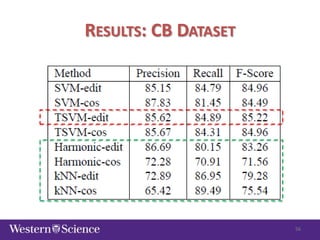
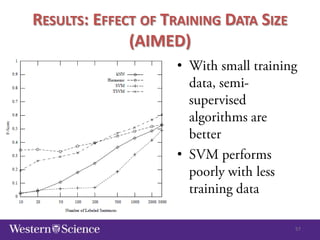
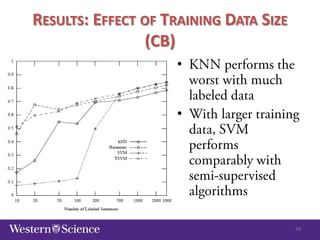

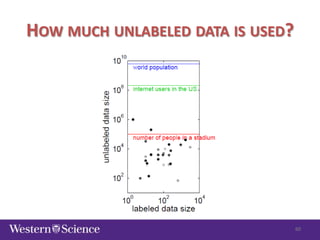




The document discusses semi-supervised classification in natural language processing, presenting problems, methods, and comparisons between generative and discriminative models. It covers various techniques like self-training and co-training, along with specific applications for tasks like spam filtering and extracting protein interaction sentences. The results highlight the effectiveness and limitations of semi-supervised methods using different datasets.
















































































