Download as PDF, PPTX


![What is Machine Learning?
http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram
"Field of study that gives computers the
ability to learn without being explicitly
programmed.”
(Arthur Samuel, 1959)
By Phillip Taylor [CC BY 2.0]](https://image.slidesharecdn.com/nextgentalk022015-150211154330-conversion-gate02/85/An-Introduction-to-Supervised-Machine-Learning-and-Pattern-Classification-The-Big-Picture-3-320.jpg)
![http://commons.wikimedia.org/wiki/
File:American_book_company_1916._letter_envelope-2.JPG#filelinks
[public domain]
https://flic.kr/p/5BLW6G [CC BY 2.0]
Text Recognition
Spam Filtering
Biology
Examples of Machine Learning](https://image.slidesharecdn.com/nextgentalk022015-150211154330-conversion-gate02/85/An-Introduction-to-Supervised-Machine-Learning-and-Pattern-Classification-The-Big-Picture-4-320.jpg)
![Examples of Machine Learning
http://googleresearch.blogspot.com/2014/11/a-picture-is-worth-thousand-coherent.html
By Steve Jurvetson [CC BY 2.0]
Self-driving cars
Photo search
and many, many
more ...
Recommendation systems
http://commons.wikimedia.org/wiki/File:Netflix_logo.svg [public domain]](https://image.slidesharecdn.com/nextgentalk022015-150211154330-conversion-gate02/85/An-Introduction-to-Supervised-Machine-Learning-and-Pattern-Classification-The-Big-Picture-5-320.jpg)


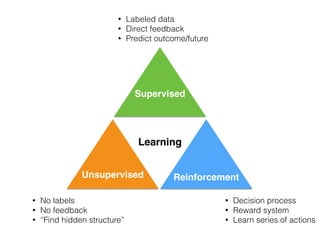
![Unsupervised
learning
Supervised
learning
Clustering:
[DBSCAN on a toy dataset]
Classification:
[SVM on 2 classes of the Wine dataset]
Regression:
[Soccer Fantasy Score prediction]
Today’s topic
Supervised LearningUnsupervised Learning](https://image.slidesharecdn.com/nextgentalk022015-150211154330-conversion-gate02/85/An-Introduction-to-Supervised-Machine-Learning-and-Pattern-Classification-The-Big-Picture-9-320.jpg)






![Generative Classifiers:
Naive Bayes
Bayes Theorem: P(ωj | xi) =
P(xi | ωj) P(ωj)
P(xi)
Posterior probability =
Likelihood x Prior probability
Evidence
Iris example: P(“Setosa"| xi), xi = [4.5 cm, 7.4 cm]](https://image.slidesharecdn.com/nextgentalk022015-150211154330-conversion-gate02/85/An-Introduction-to-Supervised-Machine-Learning-and-Pattern-Classification-The-Big-Picture-18-320.jpg)




![Decision Tree
Entropy =
depth = 4
petal length <= 2.45?
petal length <= 4.75?
Setosa
Virginica Versicolor
Yes No
e.g., 2 (- 0.5 log2(0.5)) = 1
∑−pi logk pi
i
Information Gain =
entropy(parent) – [avg entropy(children)]
NoYes
depth = 2](https://image.slidesharecdn.com/nextgentalk022015-150211154330-conversion-gate02/85/An-Introduction-to-Supervised-Machine-Learning-and-Pattern-Classification-The-Big-Picture-24-320.jpg)





![Error Metrics: Confusion Matrix
TP
[Linear SVM on sepal/petal lengths]
TN
FN
FP
here: “setosa” = “positive”](https://image.slidesharecdn.com/nextgentalk022015-150211154330-conversion-gate02/85/An-Introduction-to-Supervised-Machine-Learning-and-Pattern-Classification-The-Big-Picture-33-320.jpg)
![Error Metrics
TP
[Linear SVM on sepal/petal lengths]
TN
FN
FP
here: “setosa” = “positive”
TP + TN
FP +FN +TP +TN
Accuracy =
= 1 - Error
FP
N
TP
P
False Positive Rate =
TP
TP + FP
Precision =
True Positive Rate =
(Recall)
“micro” and “macro”
averaging for multi-class](https://image.slidesharecdn.com/nextgentalk022015-150211154330-conversion-gate02/85/An-Introduction-to-Supervised-Machine-Learning-and-Pattern-Classification-The-Big-Picture-34-320.jpg)



![Feature Selection
- Domain knowledge
- Variance threshold
- Exhaustive search
- Decision trees
- …
IMPORTANT!
(Noise, overfitting, curse of dimensionality, efficiency)
X = [x1, x2, x3, x4]start:
stop:
(if d = k)
X = [x1, x3, x4]
X = [x1, x3]
Simplest example:
Greedy Backward Selection](https://image.slidesharecdn.com/nextgentalk022015-150211154330-conversion-gate02/85/An-Introduction-to-Supervised-Machine-Learning-and-Pattern-Classification-The-Big-Picture-38-320.jpg)


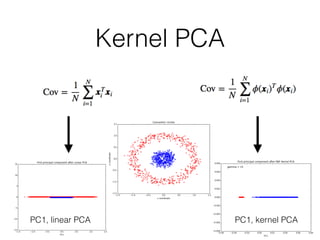
![2. Eigendecomposition and sorting eigenvalues
PCA in 3 Steps
X v = λ v
Eigenvectors
[[ 0.52237162 -0.37231836 -0.72101681 0.26199559]
[-0.26335492 -0.92555649 0.24203288 -0.12413481]
[ 0.58125401 -0.02109478 0.14089226 -0.80115427]
[ 0.56561105 -0.06541577 0.6338014 0.52354627]]
Eigenvalues
[ 2.93035378 0.92740362 0.14834223 0.02074601]
(from high to low)](https://image.slidesharecdn.com/nextgentalk022015-150211154330-conversion-gate02/85/An-Introduction-to-Supervised-Machine-Learning-and-Pattern-Classification-The-Big-Picture-41-320.jpg)
![3. Select top k eigenvectors and transform data
PCA in 3 Steps
Eigenvectors
[[ 0.52237162 -0.37231836 -0.72101681 0.26199559]
[-0.26335492 -0.92555649 0.24203288 -0.12413481]
[ 0.58125401 -0.02109478 0.14089226 -0.80115427]
[ 0.56561105 -0.06541577 0.6338014 0.52354627]]
Eigenvalues
[ 2.93035378 0.92740362 0.14834223 0.02074601]
[First 2 PCs of Iris]](https://image.slidesharecdn.com/nextgentalk022015-150211154330-conversion-gate02/85/An-Introduction-to-Supervised-Machine-Learning-and-Pattern-Classification-The-Big-Picture-42-320.jpg)
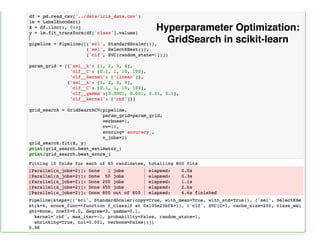
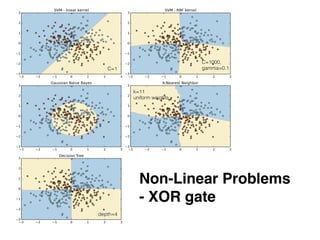








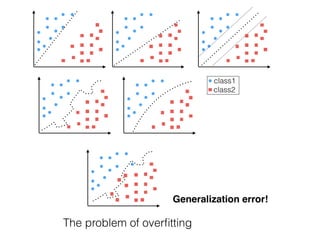

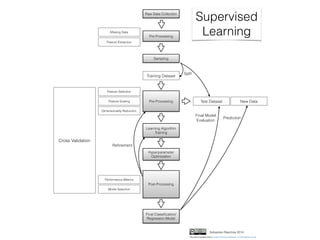
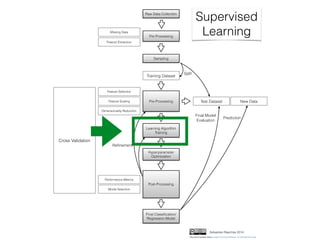
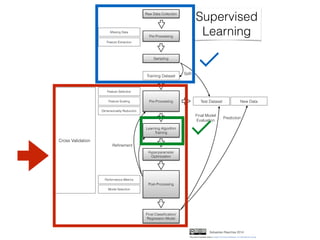
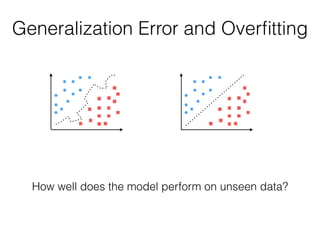
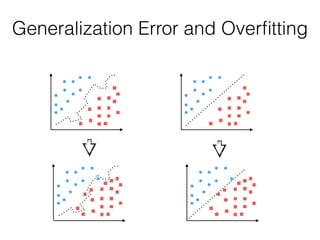
The document provides an introduction to supervised machine learning and pattern classification. It begins with an overview of the speaker's background and research interests. Key concepts covered include definitions of machine learning, examples of machine learning applications, and the differences between supervised, unsupervised, and reinforcement learning. The rest of the document outlines the typical workflow for a supervised learning problem, including data collection and preprocessing, model training and evaluation, and model selection. Common classification algorithms like decision trees, naive Bayes, and support vector machines are briefly explained. The presentation concludes with discussions around choosing the right algorithm and avoiding overfitting.





































![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)

