Download as PDF, PPTX








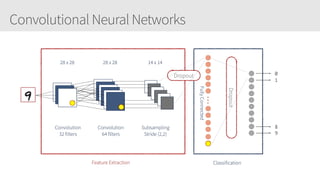









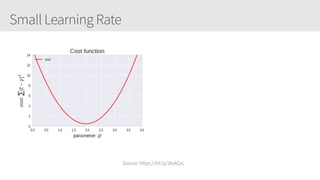
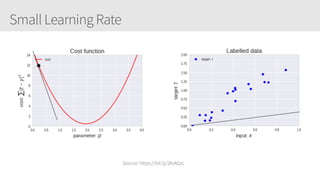
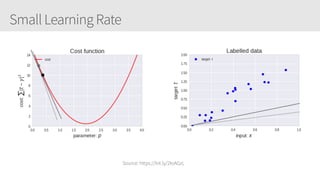
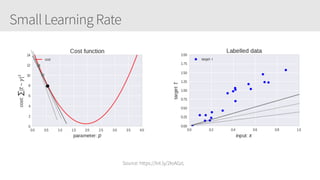
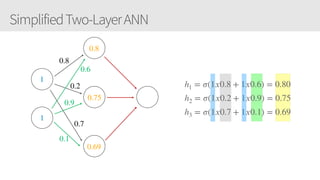
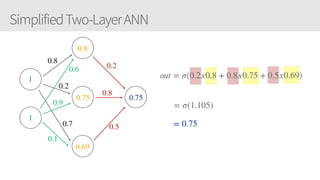
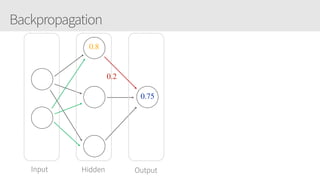
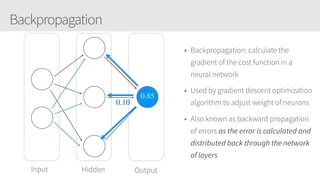
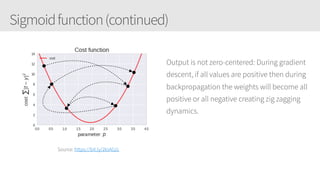






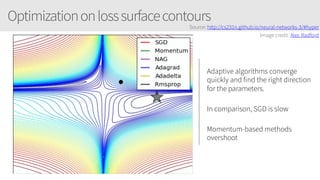
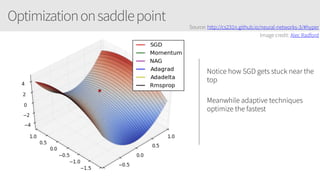




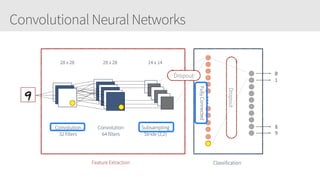
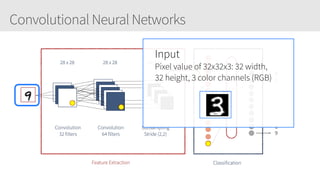
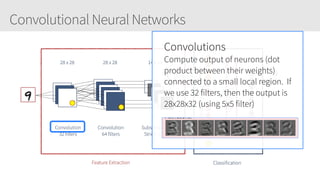
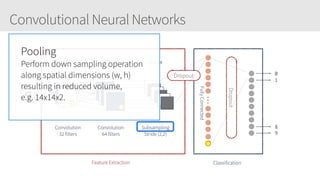
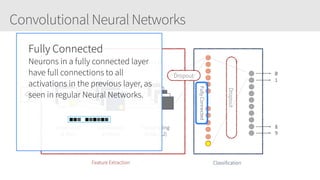








The document outlines a training series on neural networks focused on concepts and practical applications using Keras. It covers tuning, optimization, and training algorithms, alongside challenges such as overfitting and underfitting, and discusses the architecture and advantages of convolutional neural networks (CNNs). The content is designed for individuals interested in understanding deep learning fundamentals and applying them effectively.





































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)




![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)












