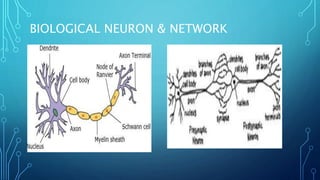
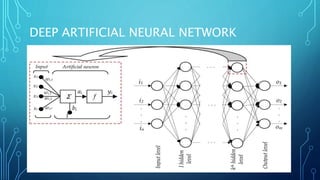
Deep learning uses multilayered neural networks to process information in a robust, generalizable, and scalable way. It has various applications including image recognition, sentiment analysis, machine translation, and more. Deep learning concepts include computational graphs, artificial neural networks, and optimization techniques like gradient descent. Prominent deep learning architectures include convolutional neural networks, recurrent neural networks, autoencoders, and generative adversarial networks.







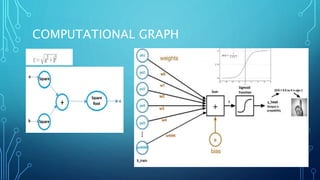
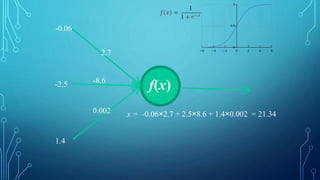
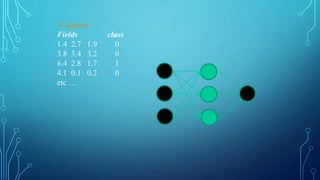
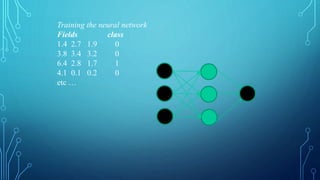

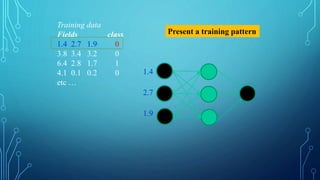
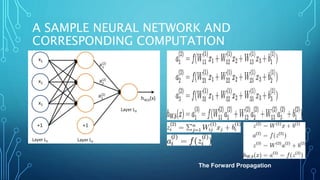

![THE PSEUDOCODE FOR CALCULATING
OUTPUT OF FORWARD-PROPAGATING
NEURAL NETWORK
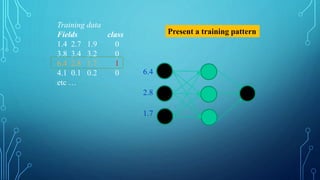
•# node[] := array of topologically sorted nodes,
An edge from a to b means a is to the left of b
•# If the Neural Network has R inputs and S
outputs, then first R nodes are input nodes and
last S nodes are output nodes.
•# incoming[x] := nodes connected to node x
•# weight[x] := weights of incoming edges to x](https://image.slidesharecdn.com/nimritadeeplearning-181231035438/85/Nimrita-deep-learning-29-320.jpg)
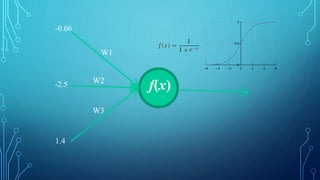
![• For each neuron x, from left to right −
• if x <= R: do nothing # its an input node
• inputs[x] = [output[i] for i in incoming[x]]
• weighted_sum = dot_product(weights[x], inputs[x])
• output[x] = Activation_function(weighted_sum)
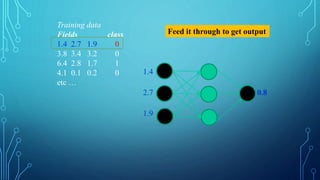
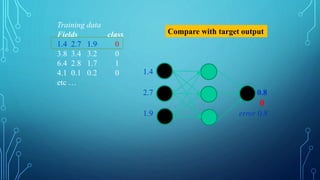
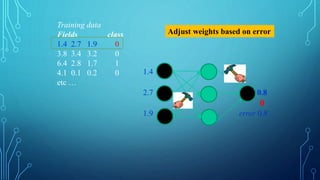
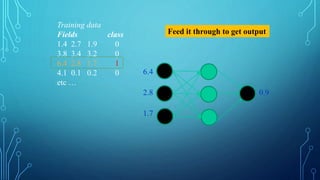
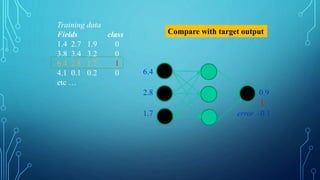
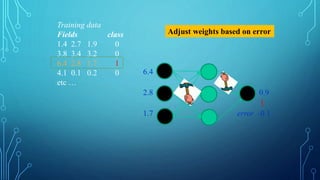
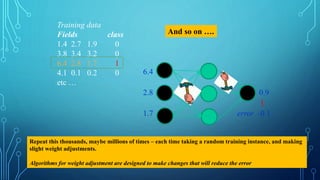
To train a neural network, use the iterative gradient descent method. After
random initialization, we make predictions on some subset of the data with
forward-propagation process, compute the corresponding cost function C,
and update each weight w by an amount proportional to dC/dw, i.e., the
derivative of the cost functions w.r.t. the weight. The proportionality
constant is known as the learning rate.
We calculate the gradients backwards, i.e., first calculate the gradients of
the output layer, then the top-most hidden layer, followed by the preceding
hidden layer, and so on, ending at the input layer.](https://image.slidesharecdn.com/nimritadeeplearning-181231035438/85/Nimrita-deep-learning-30-320.jpg)

















![FULLY CONNECTED LAYERS
• To compute class scores that we’ll use as output of
the network (e.g., the output layer at the end of the
network). The dimensions of the output volume is [ 1
× 1 × N ], where N is the number of output classes
we’re evaluating.
• Fully connected layers perform transformations on the
input data volume that are a function of the
activations in the input volume and the parameters](https://image.slidesharecdn.com/nimritadeeplearning-181231035438/85/Nimrita-deep-learning-50-320.jpg)