Downloaded 508 times








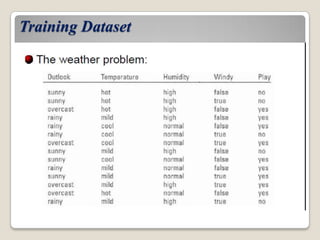
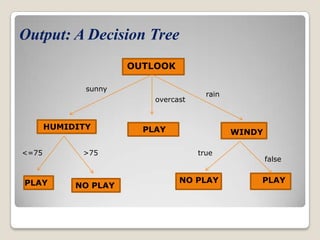













This document discusses decision trees, a classification technique in data mining. It defines classification as assigning class labels to unlabeled data based on a training set. Decision trees generate a tree structure to classify data, with internal nodes representing attributes, branches representing attribute values, and leaf nodes holding class labels. An algorithm is used to recursively split the data set into purer subsets based on attribute tests until each subset belongs to a single class. The tree can then classify new examples by traversing it from root to leaf.





























































































