Download as PDF, PPTX




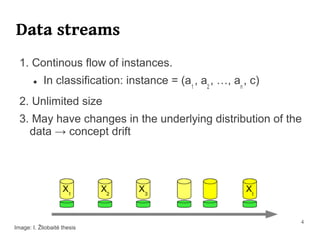

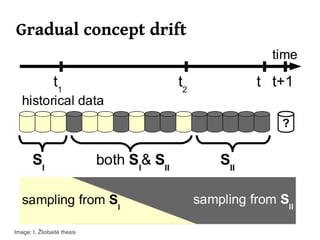
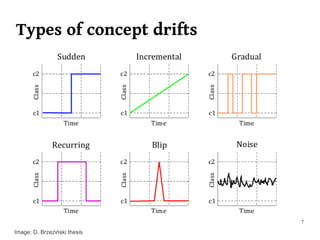
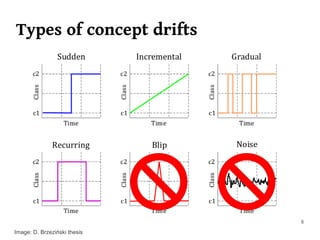
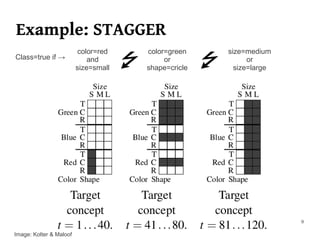





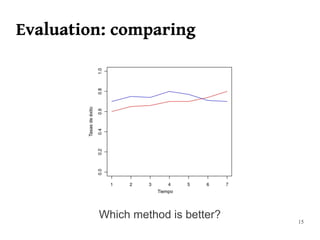
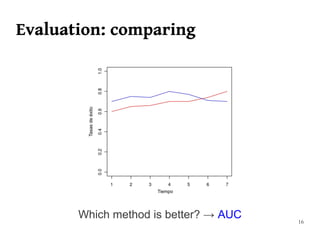



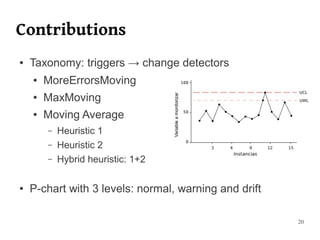

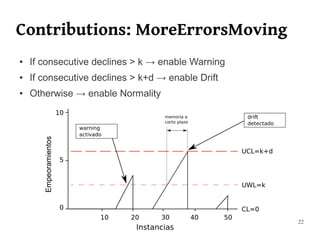
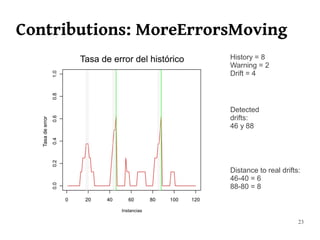

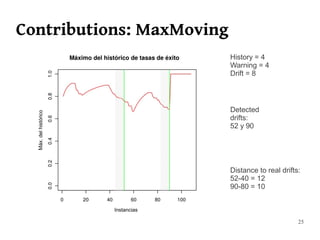
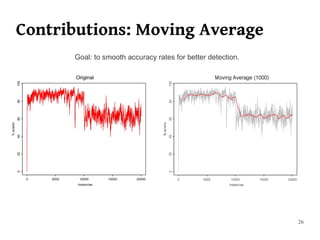
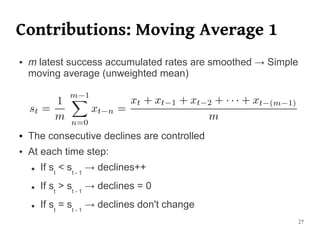
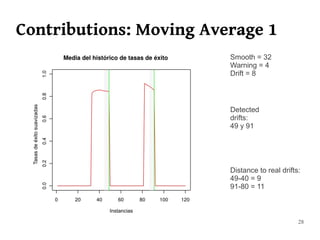

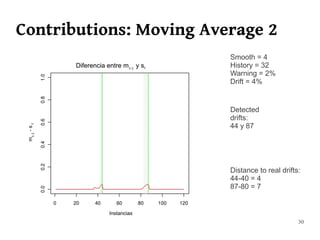









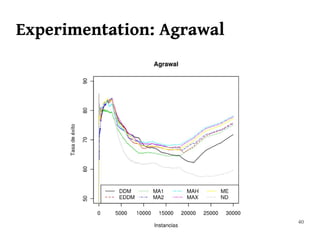





The document summarizes Manuel Martín Salvador's master's thesis on handling concept drift in data streams. It discusses concept drift, online learning approaches, evaluation methods, and taxonomy of concept drift handling methods. The contributions include developing new change detection heuristics called MoreErrorsMoving, MaxMoving, and Moving Average (with two variants), as well as a hybrid approach combining the heuristics.























































































