Downloaded 48 times

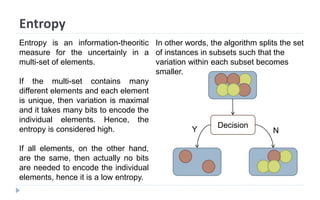
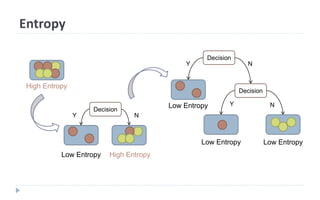
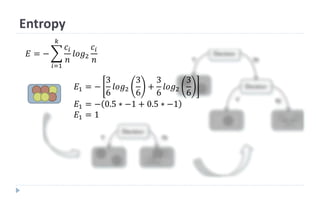
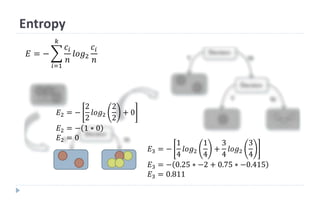
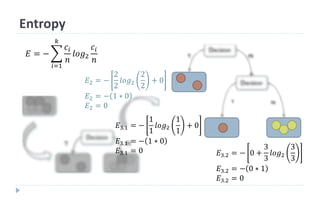

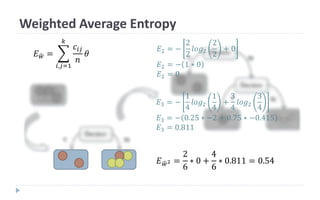

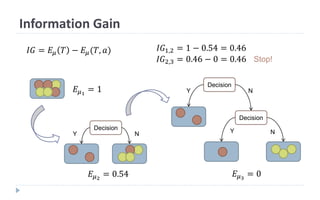


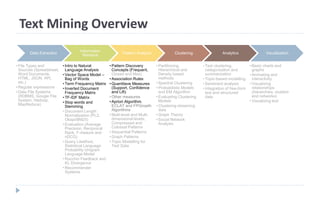















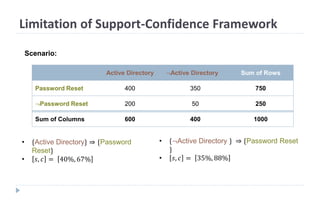

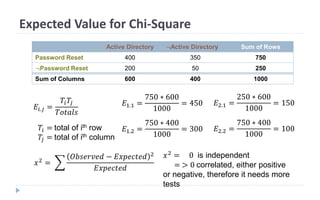



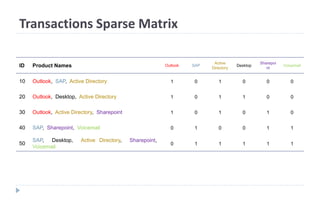

This document discusses decision tree learning, which is a supervised machine learning technique used for classification and regression. It begins by explaining the differences between supervised and unsupervised learning. It then covers concepts like information gain, entropy, and weighted average entropy which are used to build decision trees by splitting nodes. Finally, it discusses variations of decision tree algorithms and suggested topics to further read about evaluating classification models.


![Fraction ([www.onlinebcs.com]](https://cdn.slidesharecdn.com/ss_thumbnails/fractionwww-201020034237-thumbnail.jpg?width=640&height=640&fit=bounds)












































