Downloaded 120 times




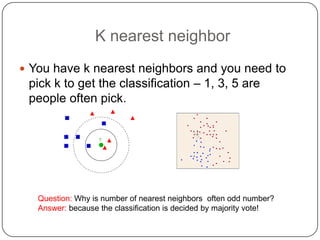

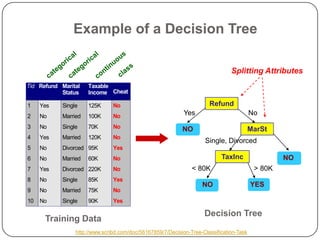
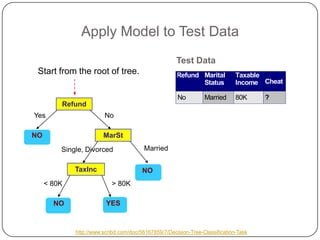





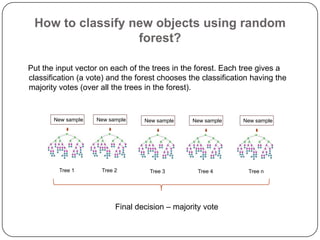



K-nearest neighbors (KNN) is a machine learning algorithm that classifies data points based on their closest neighbors. Random forest is an ensemble learning method that constructs multiple decision trees during training and outputs the class that is the mode of the classes of the individual trees. It works by constructing many decision trees during training and outputting the class that is the mode of the individual trees' classes. Random forest introduces randomness when building trees by using bootstrap samples of the data and randomly selecting a subset of features to consider when looking for the best split. This helps to decrease variance and helps prevent overfitting.























































































