Downloaded 175 times








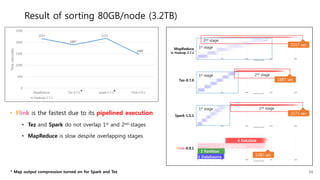

![MapReduce is slow despite overlapping stages
• mapreduce.job.reduce.slowstart.completedMaps : [0.0, 1.0]
• Wang’s attempt to overlap spark stages
0.05
(overlapping, default)
0.95
(no overlapping)
2157 sec
10%
improvement
20
Wang proposes to overlap stages
to achieve better utilization
10%???
Why Spark & MapReduce
improve just 10%?
2385 sec
2nd stage
1st stage](https://image.slidesharecdn.com/flink-forword-presentation-151019151023-lva1-app6891/85/Dongwon-Kim-A-Comparative-Performance-Evaluation-of-Flink-20-320.jpg)
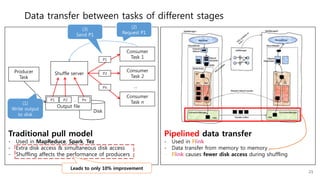
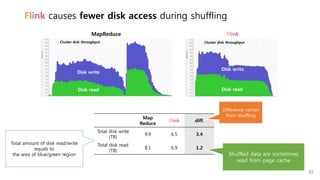


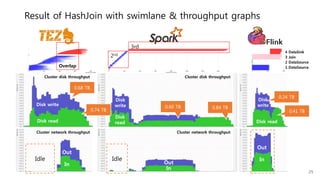




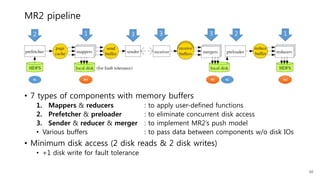
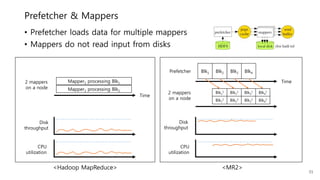
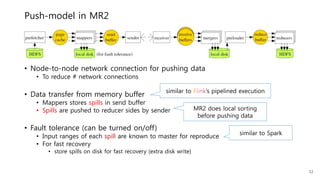
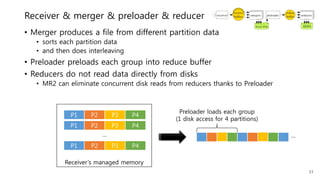
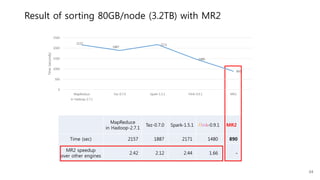
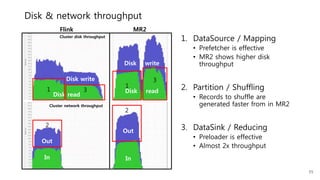
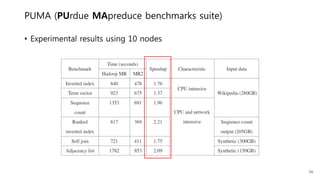



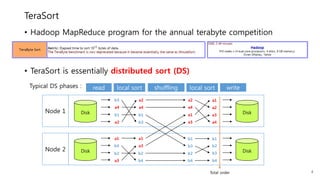
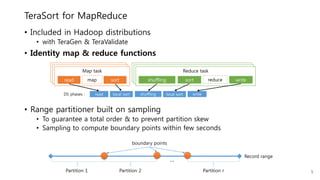
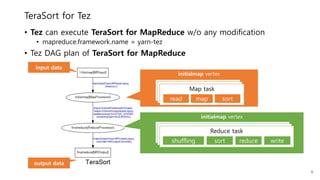
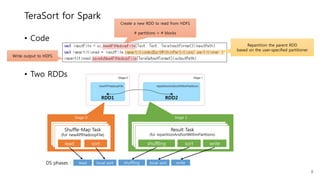
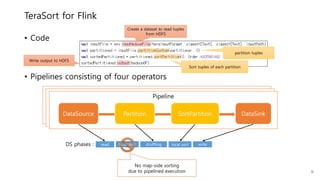
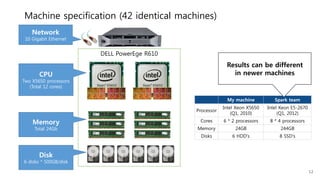
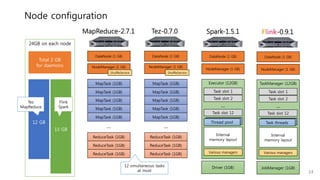
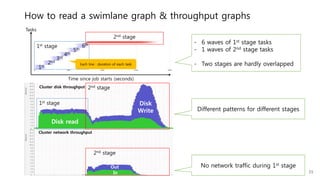
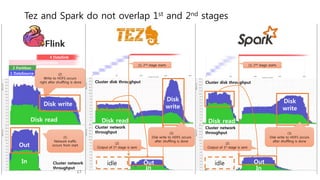
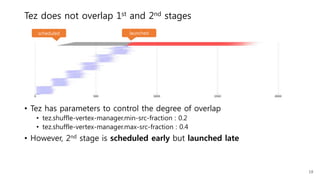
This document provides a summary and analysis of a performance evaluation comparing the big data processing engine Flink to other engines like Spark, Tez, and MapReduce. The key points are: - Flink completes a 3.2TB TeraSort benchmark faster than Spark, Tez, and MapReduce due to its pipelined execution model which allows more overlap between stages compared to the other engines. - While Tez and Spark attempt to overlap stages, in practice they do not due to the way tasks are scheduled and launched. MapReduce shows some overlap but is still slower. - Flink causes fewer disk accesses during shuffling by transferring data directly from memory to memory instead of writing to disk like
































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










