Download as PDF, PPTX







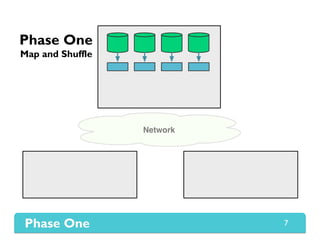
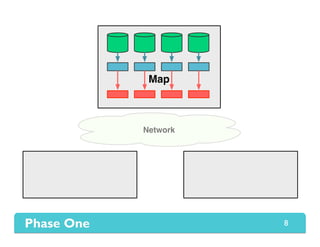
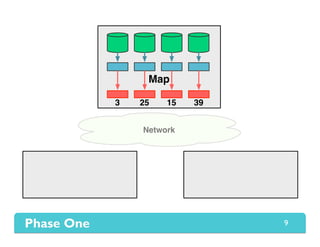
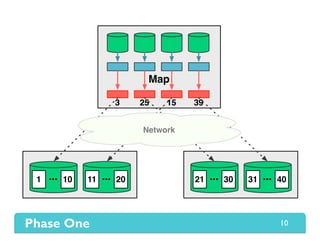
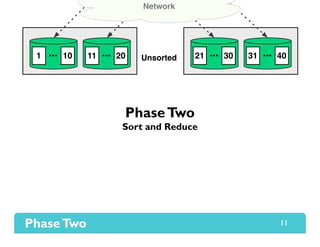
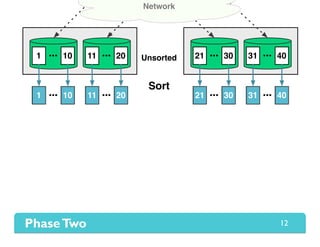
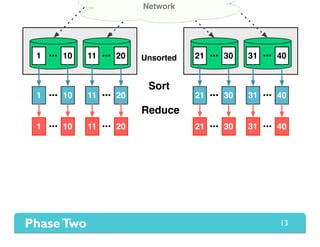
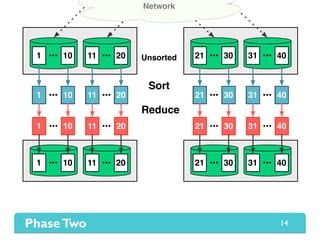
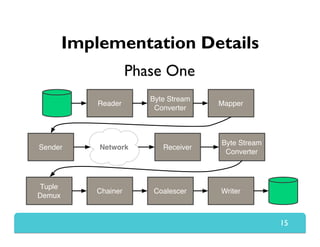
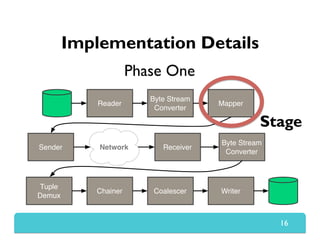



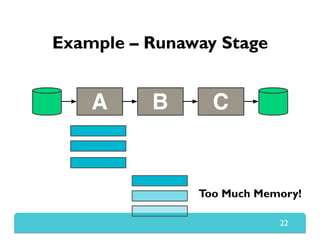
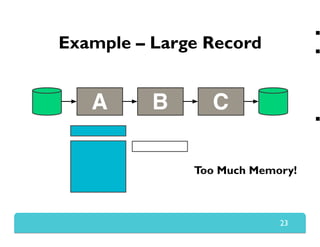

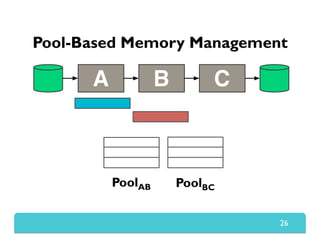
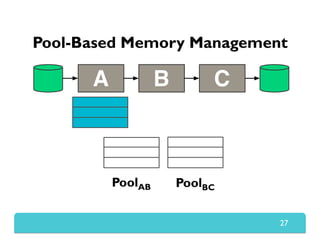

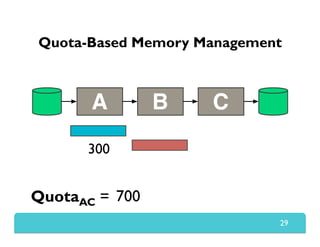








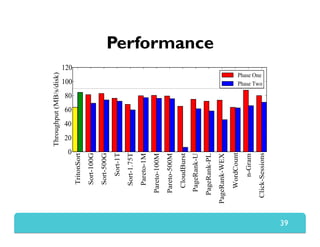
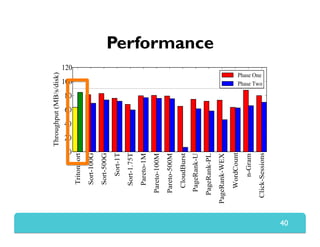
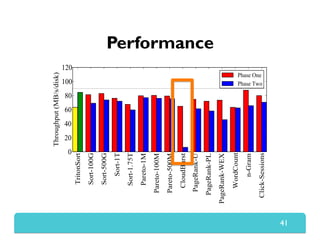




The document presents Themis, an I/O-efficient MapReduce implementation designed to achieve the '2-I/O property', minimizing disk reads and writes during data processing. It aims to overcome the inefficiencies of existing systems like Hadoop by efficiently managing memory and avoiding swapping or spilling under pressure. Themis demonstrates significant performance improvements across various workloads, in some cases achieving over 16 times faster execution than Hadoop.



































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





