Download as PDF, PPTX





![-- Data [Analysts | Engineers | Scientists] everywhere
Just one more ask:
SQL as a first-class citizen on
Databricks](https://image.slidesharecdn.com/465behmrahn-210610232740/85/Radical-Speed-for-SQL-Queries-on-Databricks-Photon-Under-the-Hood-5-320.jpg)







![Example: Spilling Hash Join [1 of 4]
Partitioned Hash Table
• Hash join has two phases
• build and probe
• Build phase: insert records
from one join input into the
hash table
• Hash table has a fixed
number of partitions](https://image.slidesharecdn.com/465behmrahn-210610232740/85/Radical-Speed-for-SQL-Queries-on-Databricks-Photon-Under-the-Hood-15-320.jpg)
![Example: Spilling Hash Join [2 of 4]
• When memory runs out spill
one partition to disk
• New records go to
in-memory partitions or
straight to disk
• Repeat until build is done
Partitioned Hash Table](https://image.slidesharecdn.com/465behmrahn-210610232740/85/Radical-Speed-for-SQL-Queries-on-Databricks-Photon-Under-the-Hood-16-320.jpg)
![Example: Spilling Hash Join [3 of 4]
• Probe phase: process
rows from other join input
• Emit results for probe
rows matching in-memory
build partitions
• Spill probe rows matching
a spilled build partition
Partitioned Hash Table
Build
Probe](https://image.slidesharecdn.com/465behmrahn-210610232740/85/Radical-Speed-for-SQL-Queries-on-Databricks-Photon-Under-the-Hood-17-320.jpg)
![Example: Spilling Hash Join [4 of 4]
• For each spilled partition,
repeat the same
build/probe process
• Might spill again! Apply
same algorithm recursively
Build
Probe
⨝](https://image.slidesharecdn.com/465behmrahn-210610232740/85/Radical-Speed-for-SQL-Queries-on-Databricks-Photon-Under-the-Hood-18-320.jpg)







![DML Support [DELETE / UPDATE / MERGE]
• Bulk of work like joins/aggregations run in Photon
• Benefits from Photon Delta/Parquet writing capability
• Typical speedups: 2-3x
ANSI SQL Support
• Development in tandem with open-source Spark
• Fail queries on overflow or similar errors](https://image.slidesharecdn.com/465behmrahn-210610232740/85/Radical-Speed-for-SQL-Queries-on-Databricks-Photon-Under-the-Hood-28-320.jpg)




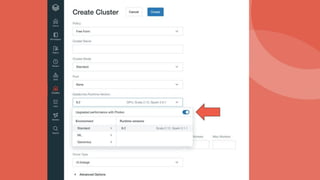

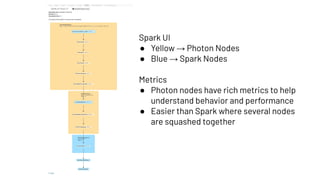
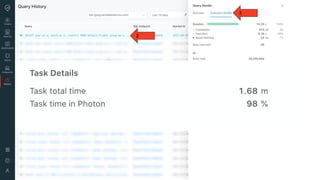

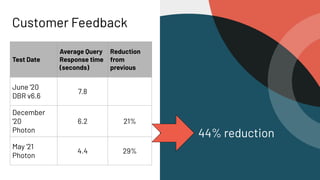
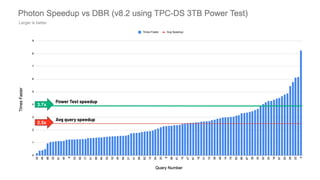







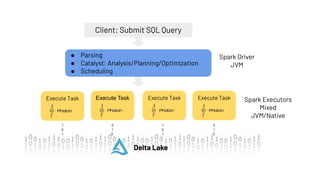

Photon is a new query engine developed by Databricks designed to enhance SQL query performance on modern cloud infrastructure. It is 100% compatible with Apache Spark and offers features such as native C++ execution, efficient memory management, and support for various data use cases, with upcoming support for nested types and ANSI SQL. Photon aims to balance speed and resilience while addressing common SQL operations and enhancing query execution efficiency in Databricks environments.























































































