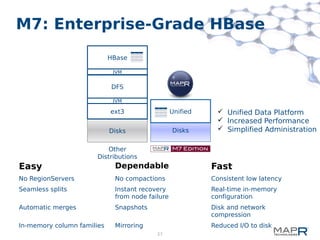
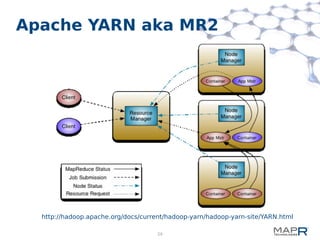
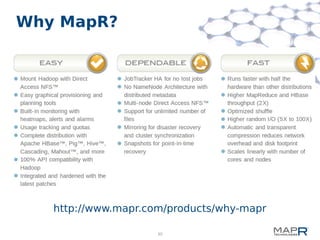
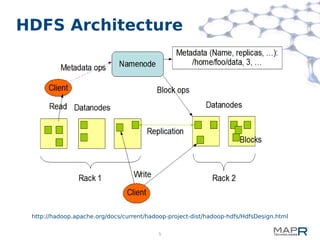
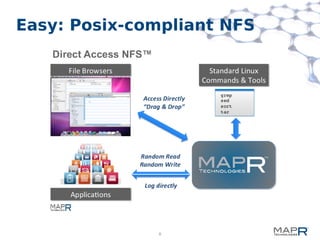
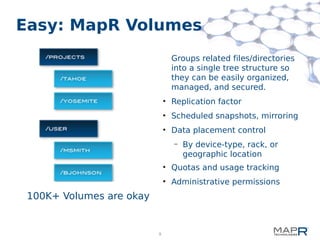
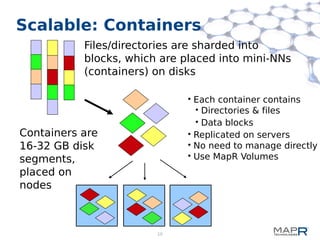
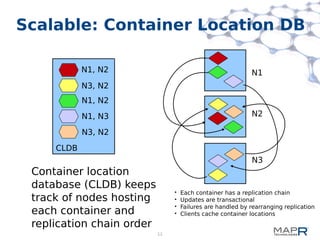
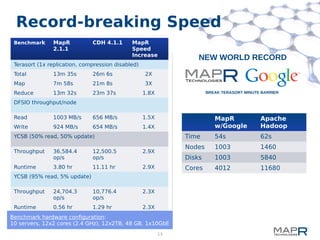
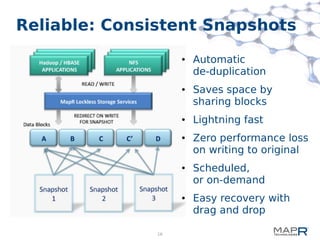
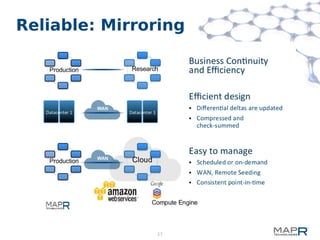
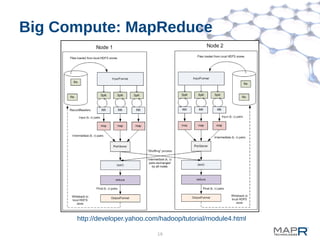
This document provides a summary of MapReduce improvements in the MapR Hadoop distribution. It discusses how MapR addresses architectural flaws in HDFS through its scalable container-based filesystem. It also describes how MapR improves MapReduce performance through techniques like direct shuffle and express lanes. The document notes how MapR provides high availability for systems like the container location database and JobTracker. It concludes by discussing MapR's support for other frameworks like HBase and Apache Drill beyond traditional MapReduce.













![23
Easy: Label-based Scheduling
● Assign labels to nodes or regex/glob expressions for nodes
– perfnode1* → “production”
– /.*ssd[0-9]*/ → “fast_ssd”
● Create label expressions for jobs/queues
– Queue “fast_prod” → “production && fast_ss”
● Tasks from these jobs/queues will only be assigned to nodes whose
labels match the expression.
● Combine with Data Placement policies for data and compute locality
● No static partitioning necessary
– Frequent labels file refresh
– New nodes automatically fall into appropriate regex/glob labels
– New jobs can specify label expression or use queue's or both
● http://www.mapr.com/doc/display/MapR/Placing+Jobs+on+Specified+Nodes](https://image.slidesharecdn.com/mapreduce-130930205214-phpapp02/85/MapReduce-Improvements-in-MapR-Hadoop-23-320.jpg)