Download as PDF, PPTX



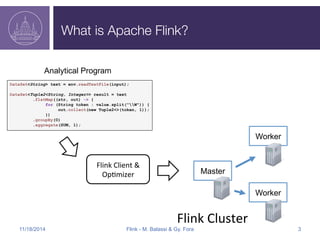


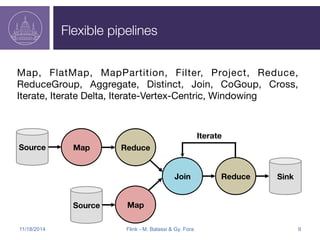








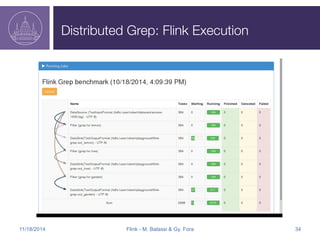
![Flink Streaming
//Build new model every minute
DataStream<Double[]> model= env
.addSource(new TrainingDataSource())
.window(60000)
.reduceGroup(new ModelBuilder());
//Predict new data using the most up-to-date model
DataStream<Integer> prediction = env
.addSource(new NewDataSource())
.connect(model)
.map(new Predictor());
M
N. Data Output
P
T. Data
11/18/2014 Flink - M. Balassi & Gy. Fora 19](https://image.slidesharecdn.com/flinkapacheconpurple-141123151828-conversion-gate02/85/Flink-Apachecon-Presentation-19-320.jpg)




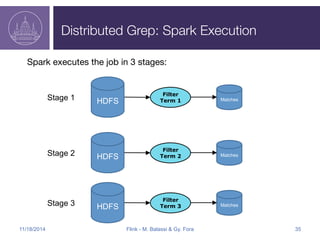
![Spark in-memory pinning
Filter
Term 1
Cache in-memory
to avoid reading the
data for each filter
HDFS
Filter
Term 2
Filter
Term 3
Matches
Matches
Matches
In-
Memory
RDD
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> file = sc.textFile(inFile).persist(StorageLevel.MEMORY_AND_DISK());
for(int p = 0; p < patterns.length; p++) {
final String pattern = patterns[p];
JavaRDD<String> res = file.filter(new Function<String, Boolean>() { … }); }
11/18/2014 Flink - M. Balassi & Gy. Fora 36](https://image.slidesharecdn.com/flinkapacheconpurple-141123151828-conversion-gate02/85/Flink-Apachecon-Presentation-36-320.jpg)

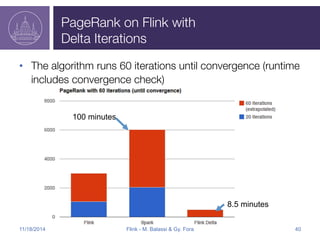
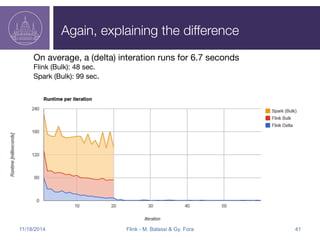
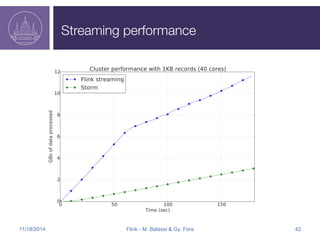




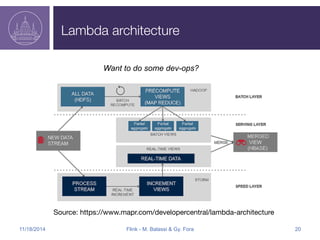
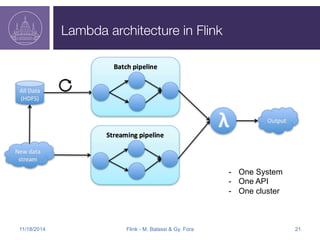
Apache Flink is an open-source big data analytics platform that started in 2009 and has evolved to support both batch and stream processing, making it significantly faster than Hadoop. It offers programming APIs for Java and Scala, supports flexible data processing models, and integrates well with various data sources like Kafka and HDFS. The Flink roadmap includes ongoing improvements in fault tolerance, API development, and enhancements for machine learning and graph processing.























































































