Downloaded 193 times





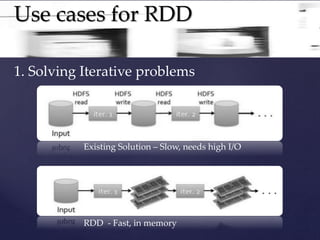



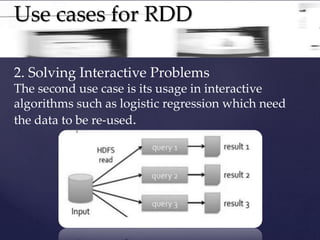







RDDs (Resilient Distributed Datasets) provide a fault-tolerant abstraction for data reuse across jobs in distributed applications. They allow data to be persisted in memory and manipulated using transformations like map and filter. This enables efficient processing of iterative algorithms. RDDs achieve fault tolerance by logging the transformations used to build a dataset rather than the actual data, enabling recovery of lost partitions through recomputation.











































































































