Downloaded 92 times
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
“Scaling Laws for Neural Language Models” (2020)
Itsuki Okimura, PSI B3](https://image.slidesharecdn.com/dl210219okimura-210219023458/85/DL-Scaling-Laws-for-Neural-Language-Models-1-320.jpg)




















![DEEP LEARNING JP
[DL Papers]
“Scaling Laws for Neural Language Models” (2020)
Itsuki Okimura, PSI B3
http://deeplearning.jp/](https://image.slidesharecdn.com/dl210219okimura-210219023458/85/DL-Scaling-Laws-for-Neural-Language-Models-27-320.jpg)

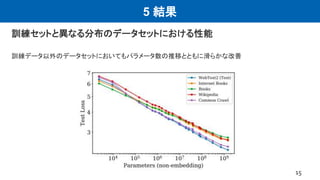
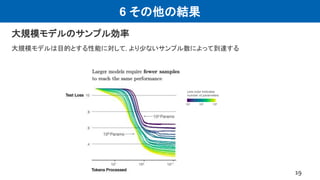
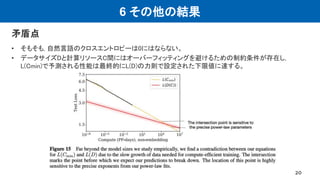
This document summarizes a research paper on scaling laws for neural language models. Some key findings of the paper include: - Language model performance depends strongly on model scale and weakly on model shape. With enough compute and data, performance scales as a power law of parameters, compute, and data. - Overfitting is universal, with penalties depending on the ratio of parameters to data. - Large models have higher sample efficiency and can reach the same performance levels with less optimization steps and data points. - The paper motivated subsequent work by OpenAI on applying scaling laws to other domains like computer vision and developing increasingly large language models like GPT-3.


![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)








![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)








































