Downloaded 34 times


![Big Data
• We create 2.5x1018 bytes of data per day [IBM]
• Sloan Digital Sky Survey: 200GB/night
• Facebook: 240 billions of photos till Jan,2013
• 250 million photos uploaded daily
• Cloud storage
• Amazon: 2 trillion objects, peak1.1 million op/sec
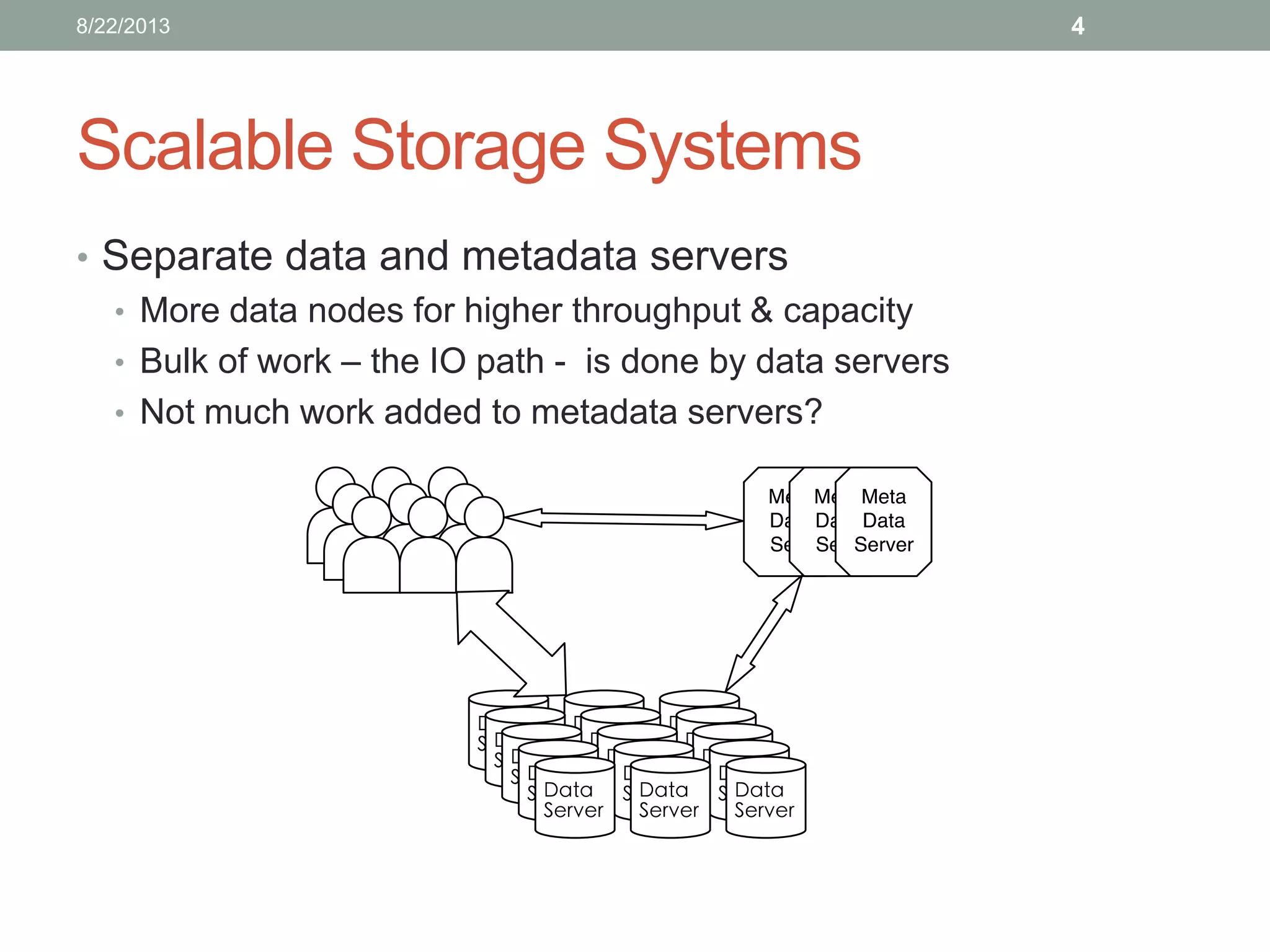
• Need scalable storage systems
• Scalable metadata <- focus of this presentation
• Scalable storage
• Scalable IO
38/22/2013](https://image.slidesharecdn.com/huglxiaoaug21updated-130822132258-phpapp01/75/August-2013-HUG-Removing-the-NameNode-s-memory-limitation-3-2048.jpg)
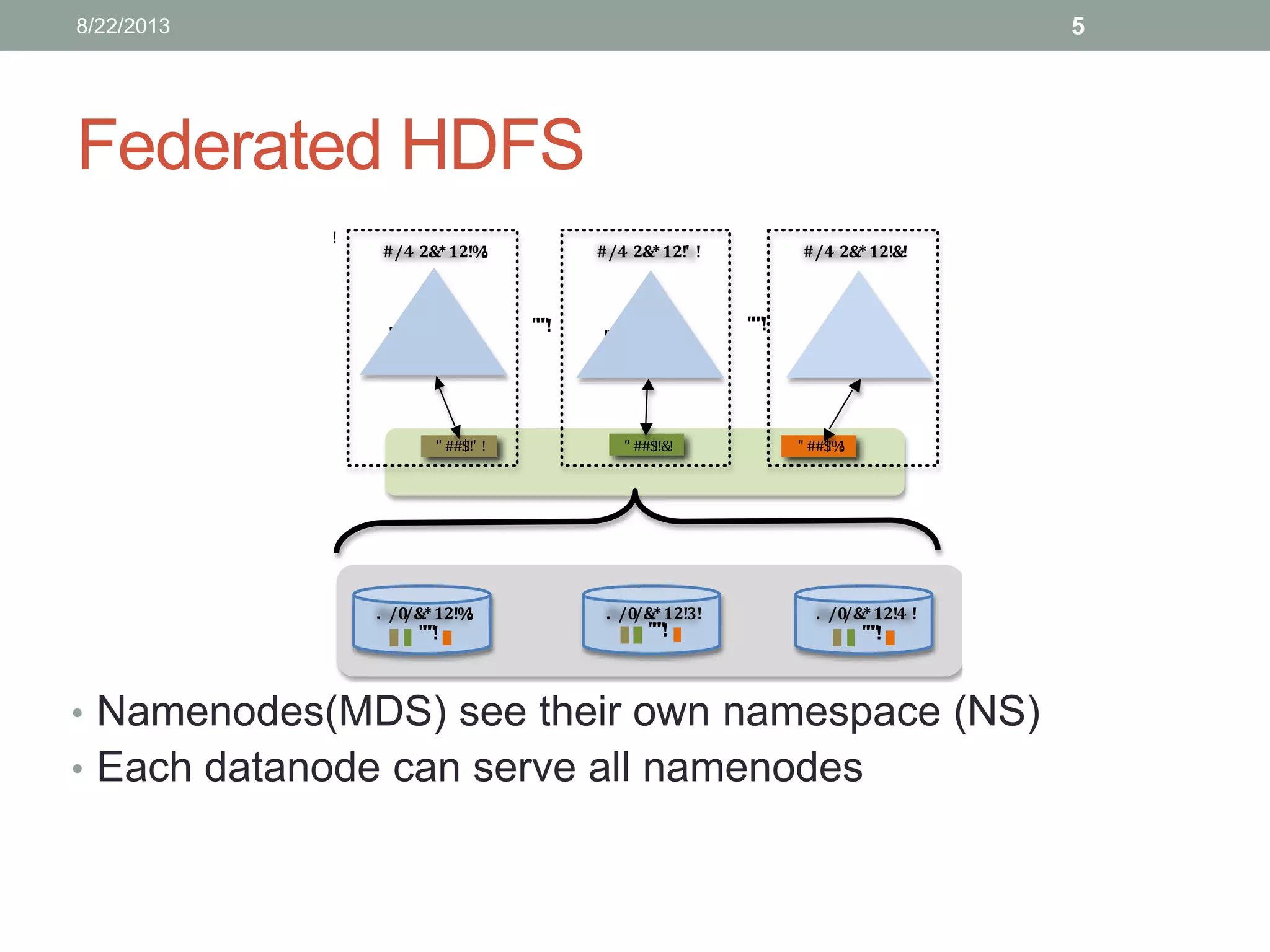



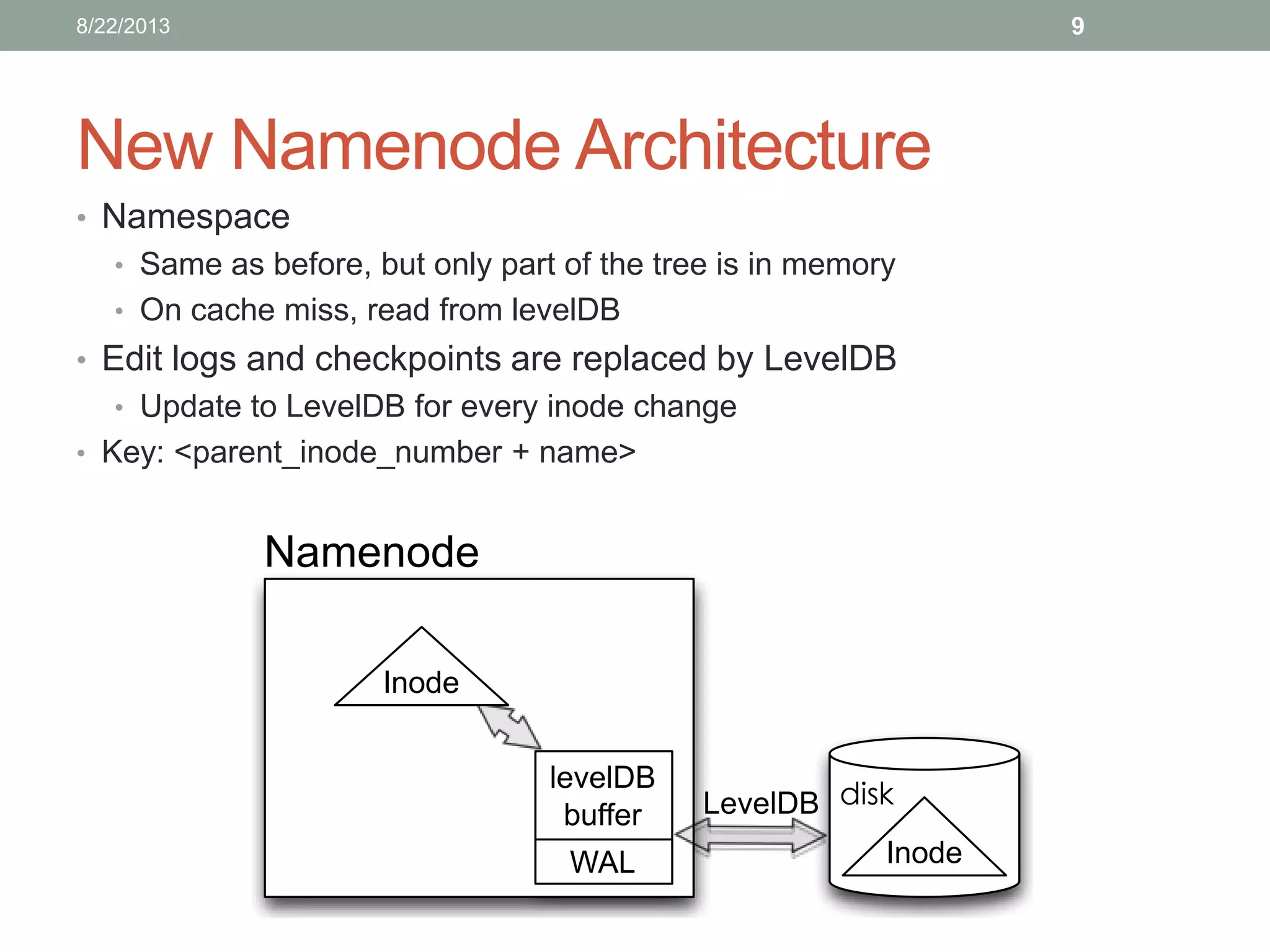






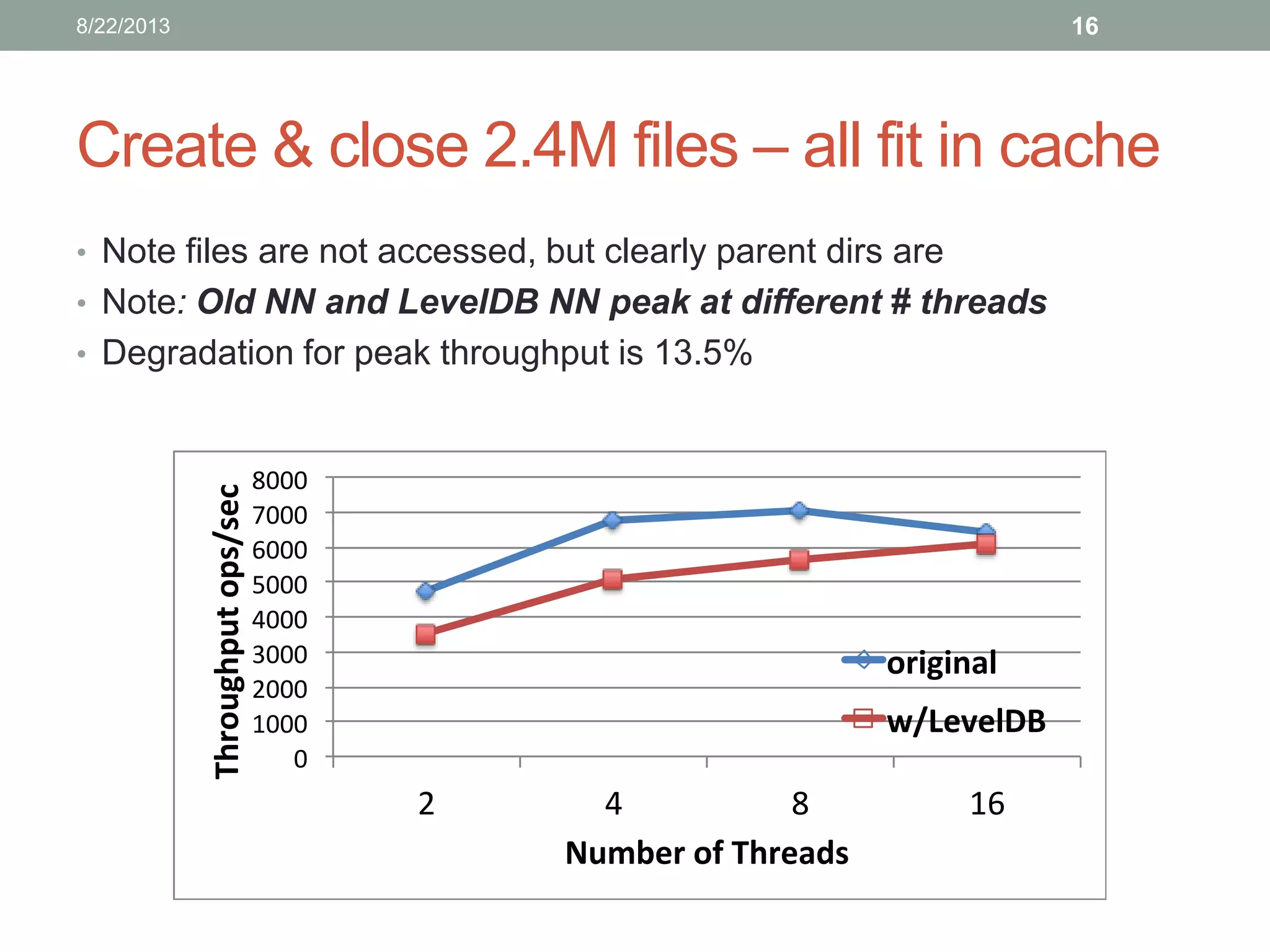
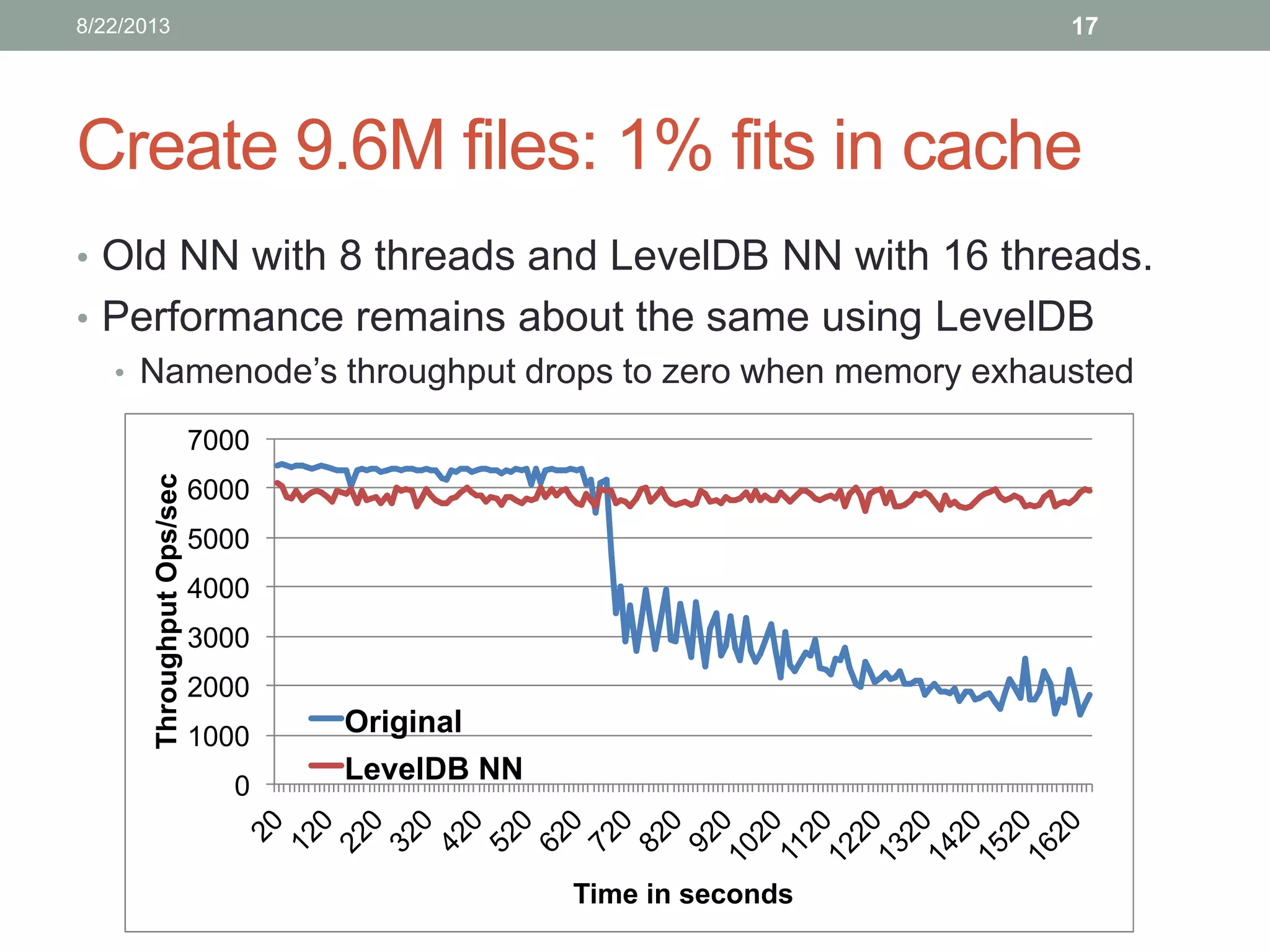




Lin Xiao's internship project at Hortonworks focuses on removing the memory limitation of the namenode in scalable distributed file systems. The proposed solution involves using LevelDB for persistent storage, which helps maintain performance while managing a larger namespace. Initial benchmarks indicate promising results, and further testing is planned to evaluate caching effectiveness across various workloads.























































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)





