Downloaded 23 times









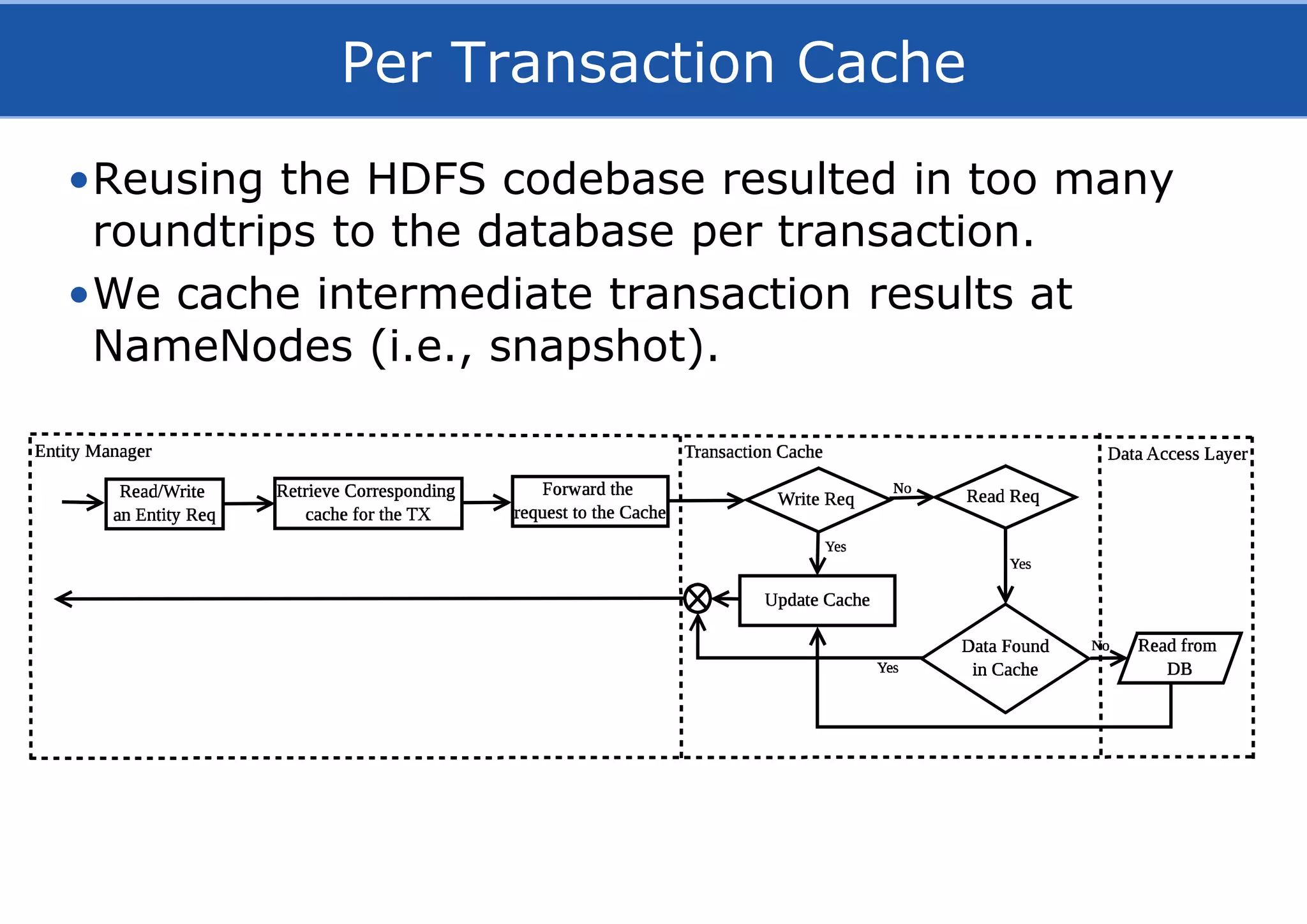
![Concurrency Model: Implicit Locking
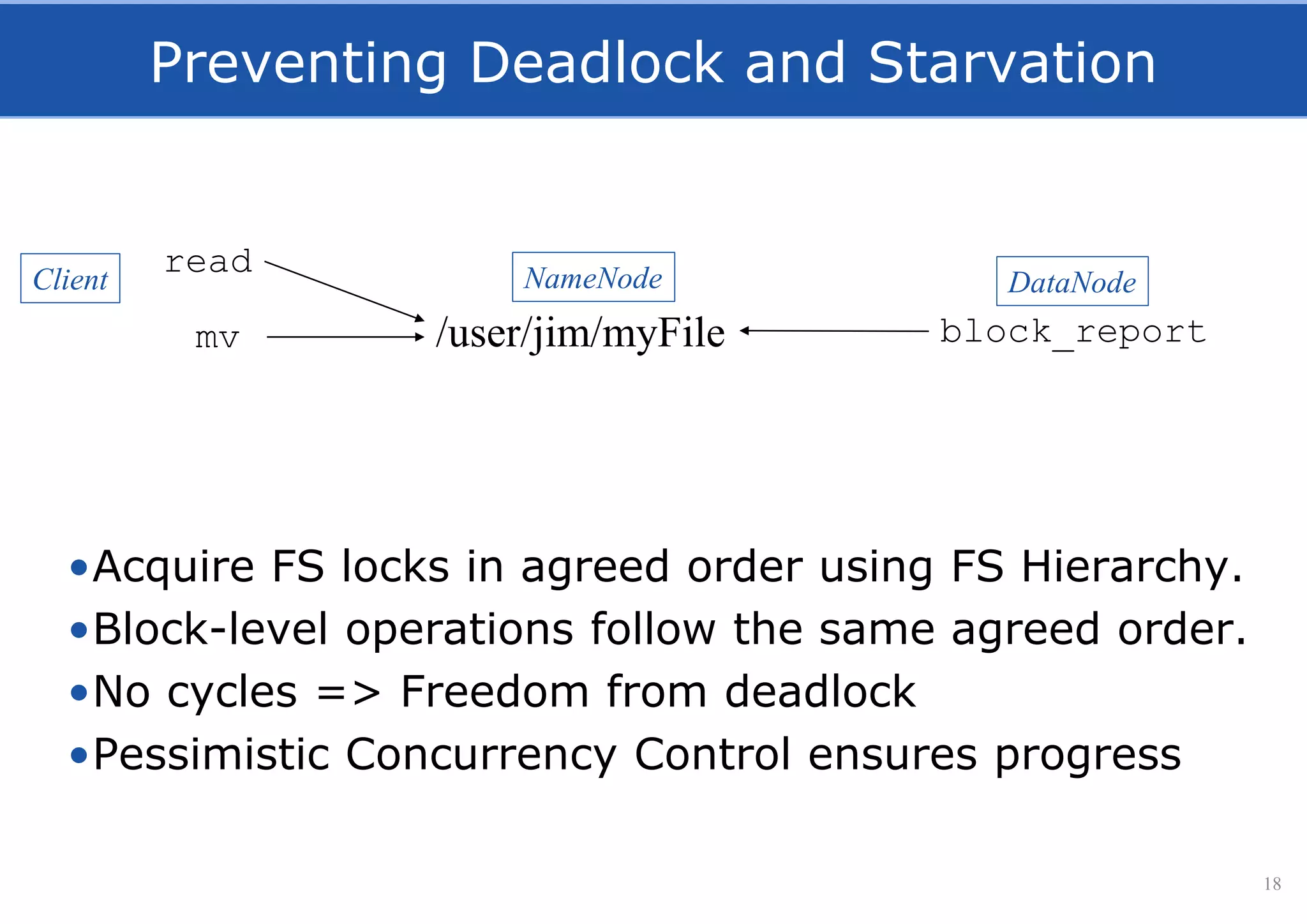
• Serializabile FS ops using implicit locking of subtrees.
17
[Hakimzadeh, Peiro, Dowling, ”Scaling HDFS with a Strongly Consistent Relational Model for Metadata”, DAIS 2014]](https://image.slidesharecdn.com/hopsfs-sep16-oracle-161128140933/75/Hopsfs-10x-HDFS-performance-17-2048.jpg)
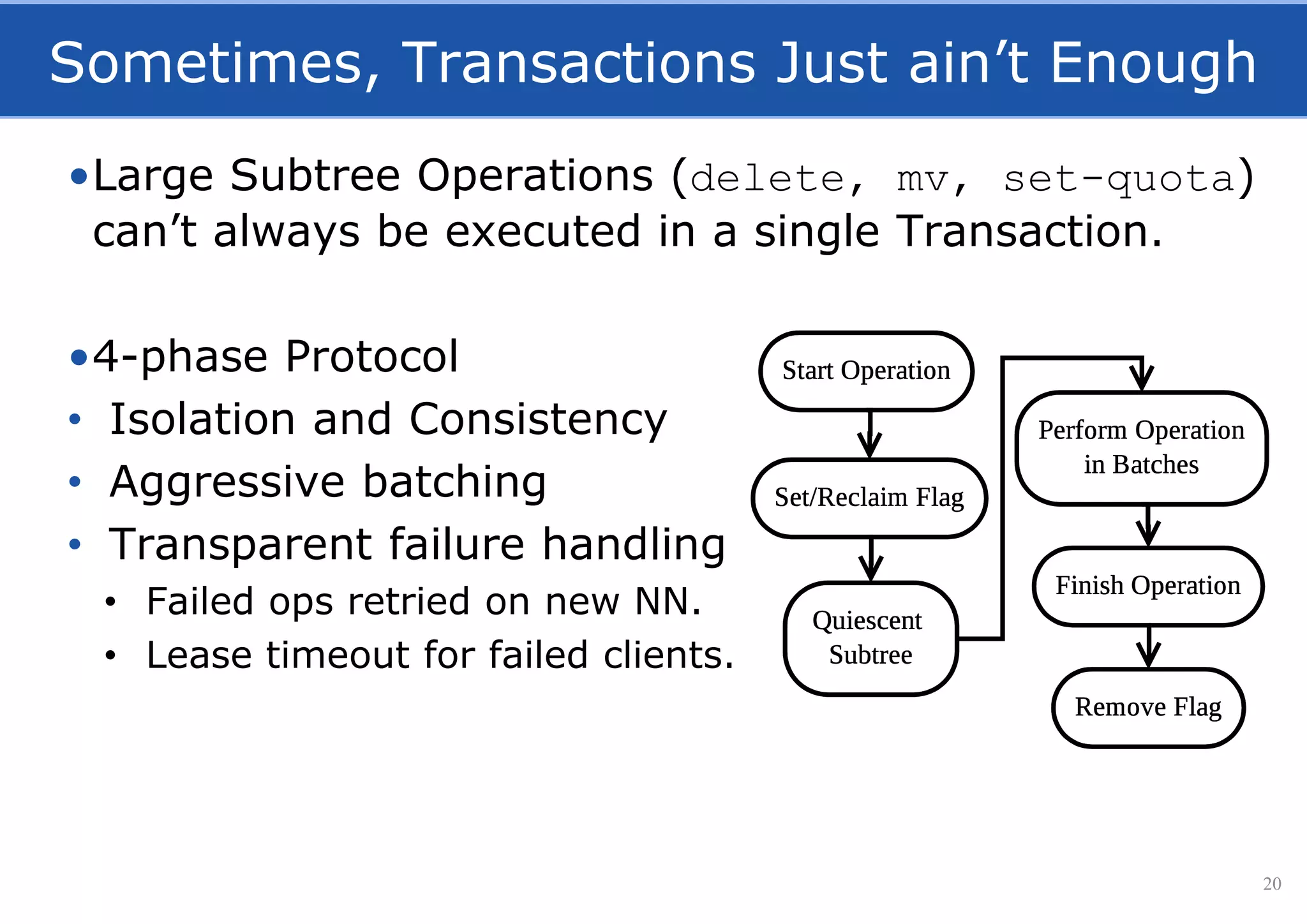
![Leader Election using NDB
•Leader to coordinate replication/lease management
•NDB as shared memory for Leader Election of NN.
21
[Niazi, Berthou, Ismail, Dowling, ”Leader Election in a NewSQL Database”, DAIS 2015]](https://image.slidesharecdn.com/hopsfs-sep16-oracle-161128140933/75/Hopsfs-10x-HDFS-performance-21-2048.jpg)

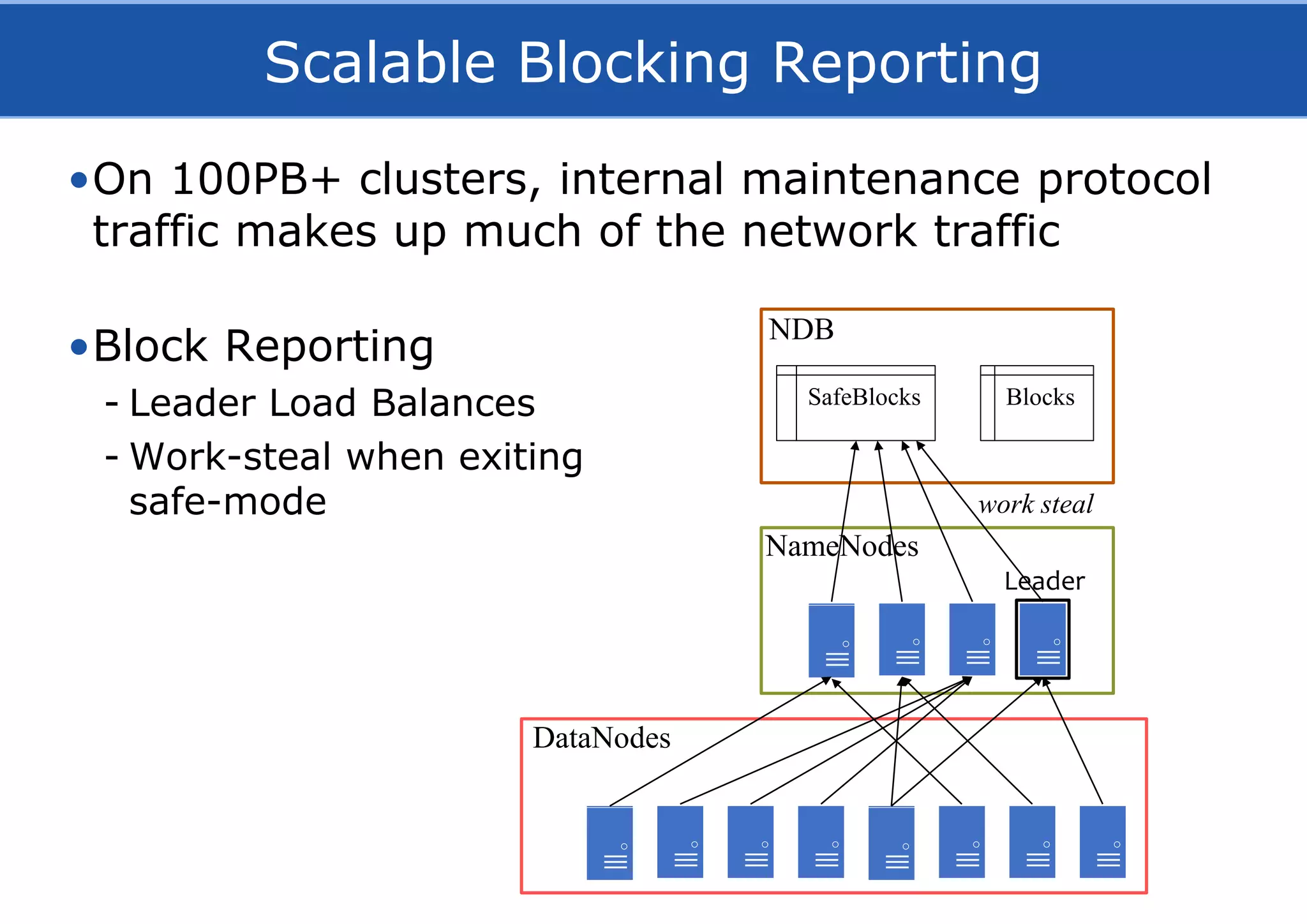
![Path Component Caching
•Resolving a path of length N gives O(N) round-trips
•With our cache, O(1) round-trip for a cache hit
/user/jim/myFile
NDB
getInode
(0, “user”) getInode
(1, “jim”) getInode
(2, “myFile”)
NameNode
/user/jim/myFile
NDB
validateInodes
([(0, “user”),
(1,”jim”),
(2,”myFile”)])
NameNode
Cache
getInodes(“/user/jim/myFile”)](https://image.slidesharecdn.com/hopsfs-sep16-oracle-161128140933/75/Hopsfs-10x-HDFS-performance-23-2048.jpg)








![Hops
[Hadoop For Humans]
Join us!
http://github.com/hopshadoop](https://image.slidesharecdn.com/hopsfs-sep16-oracle-161128140933/75/Hopsfs-10x-HDFS-performance-48-2048.jpg)

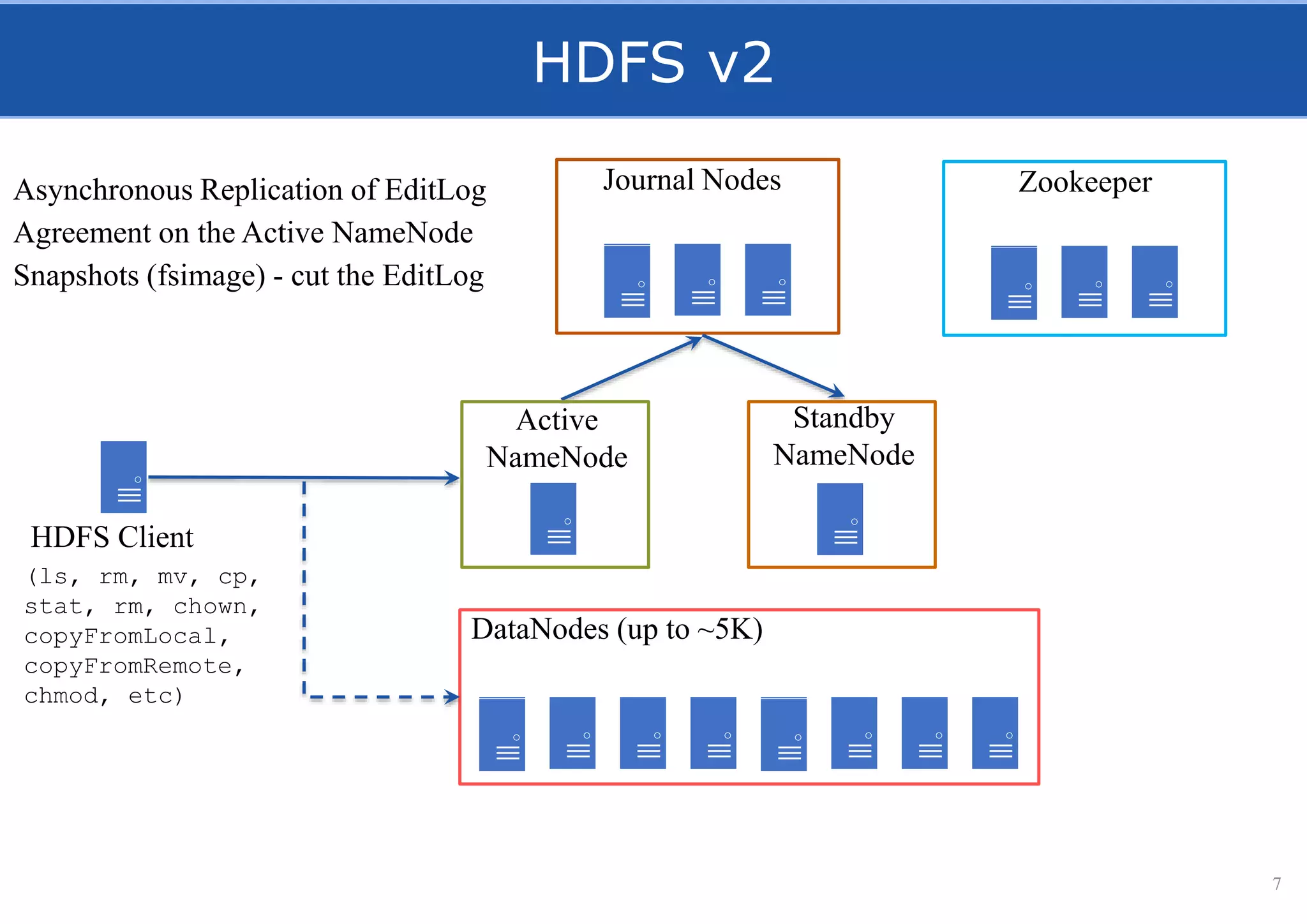
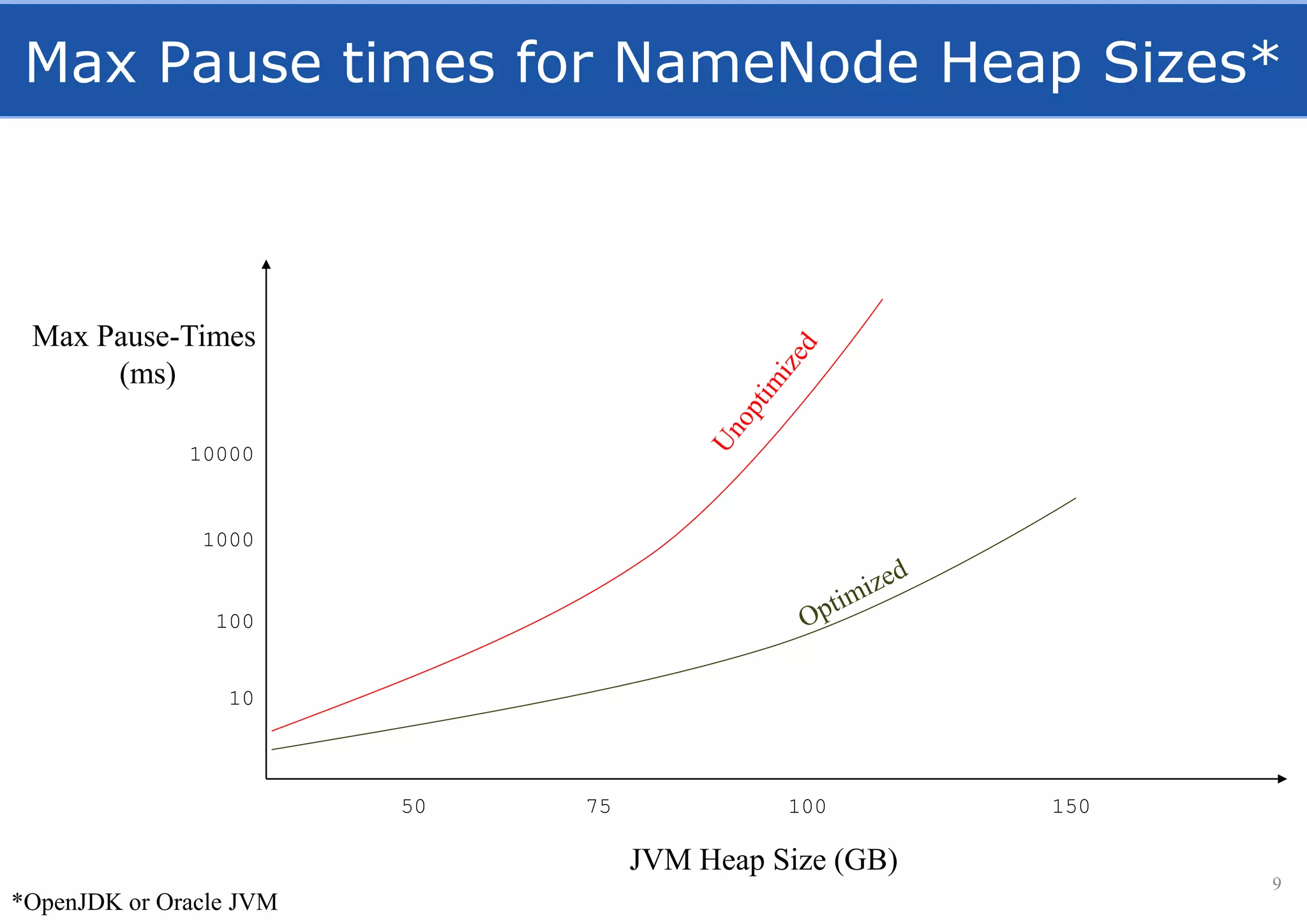
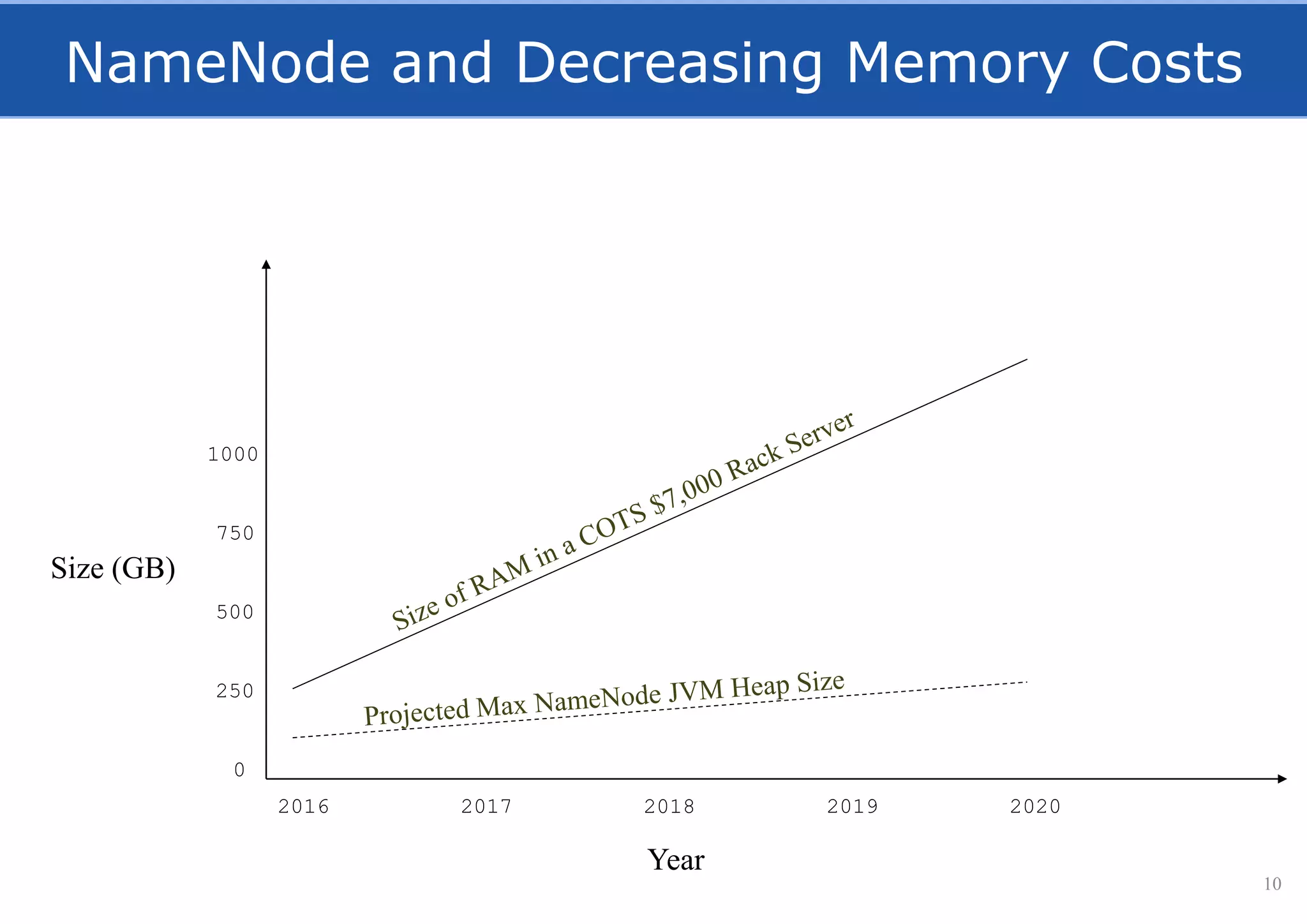
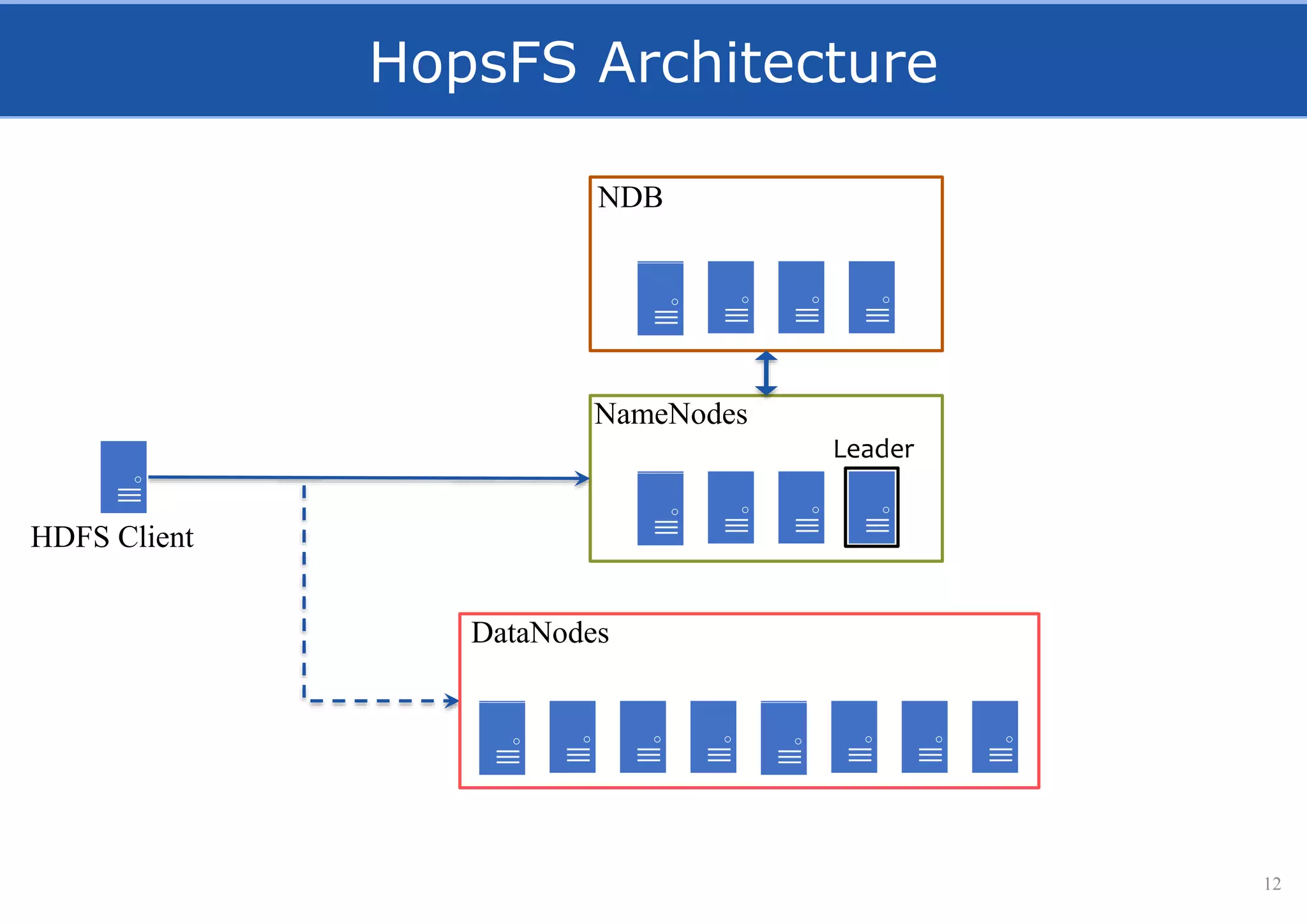
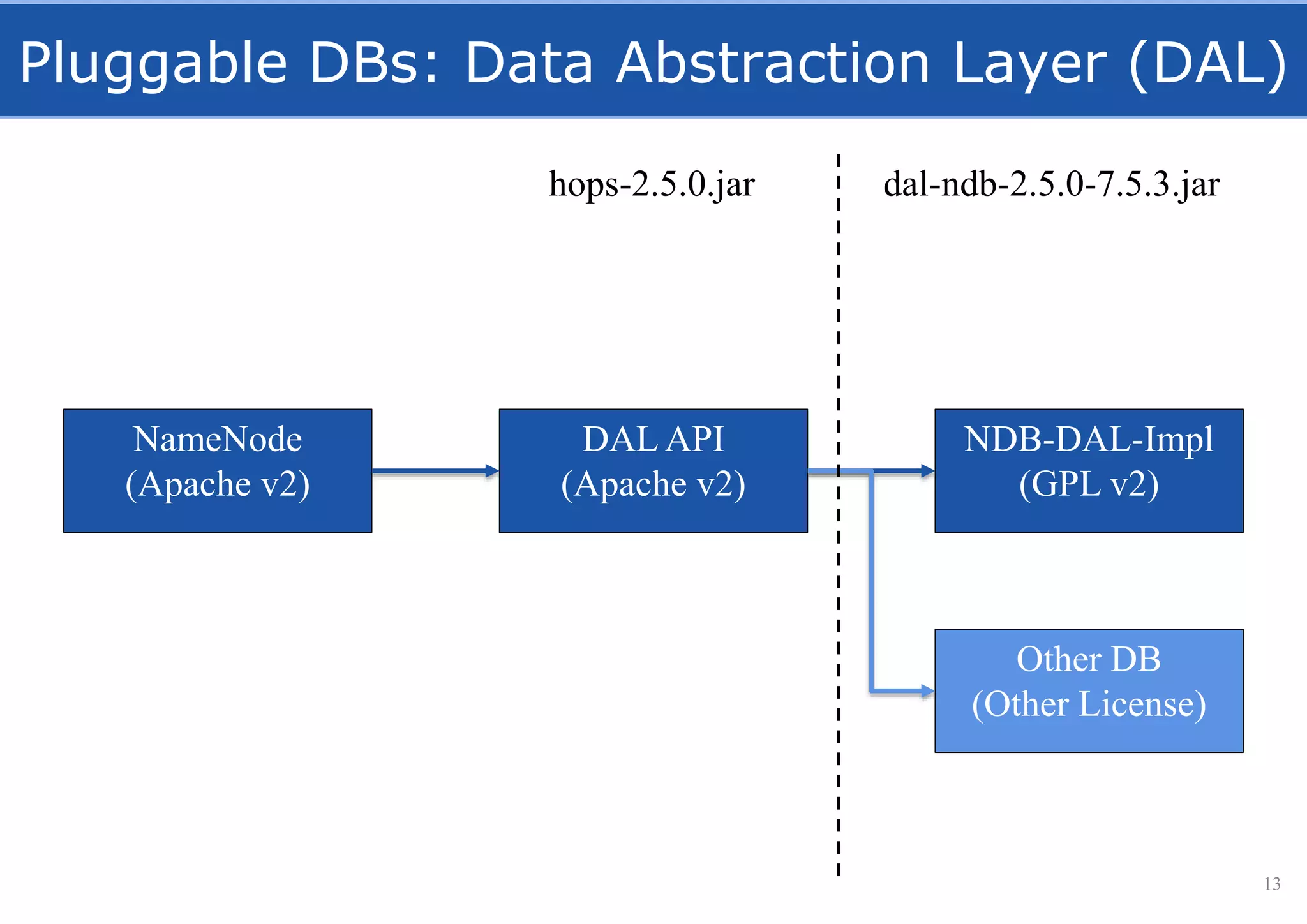
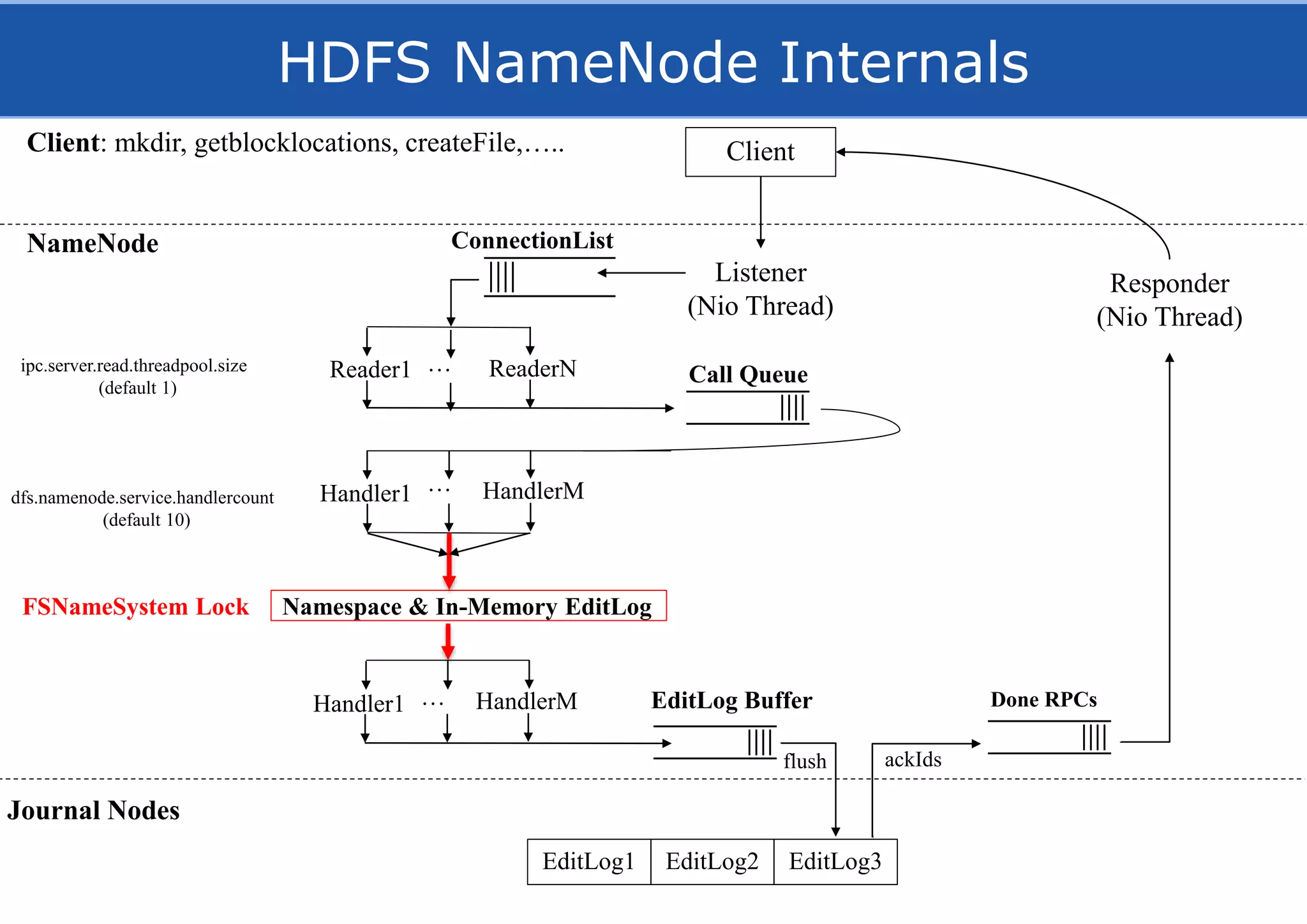
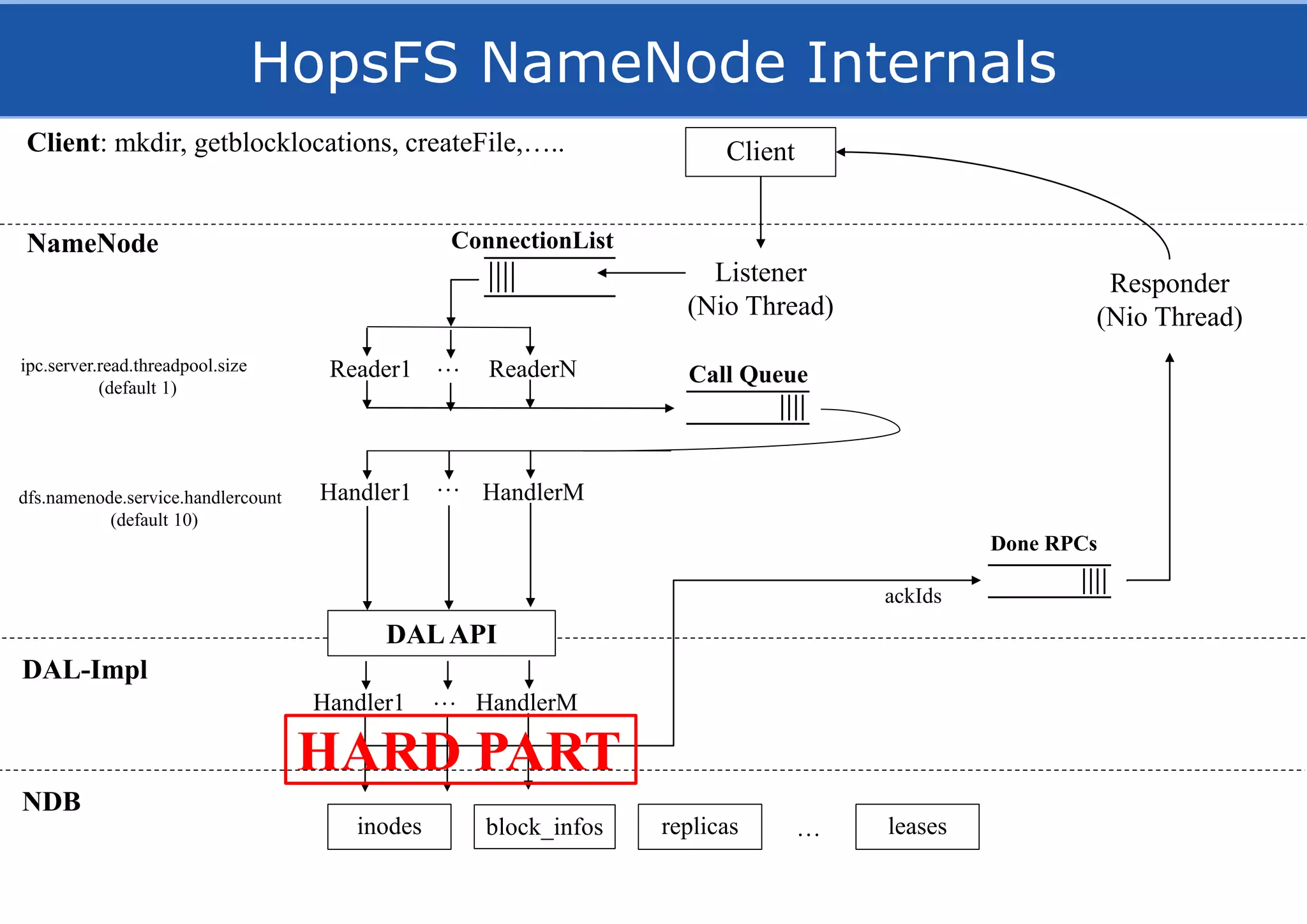
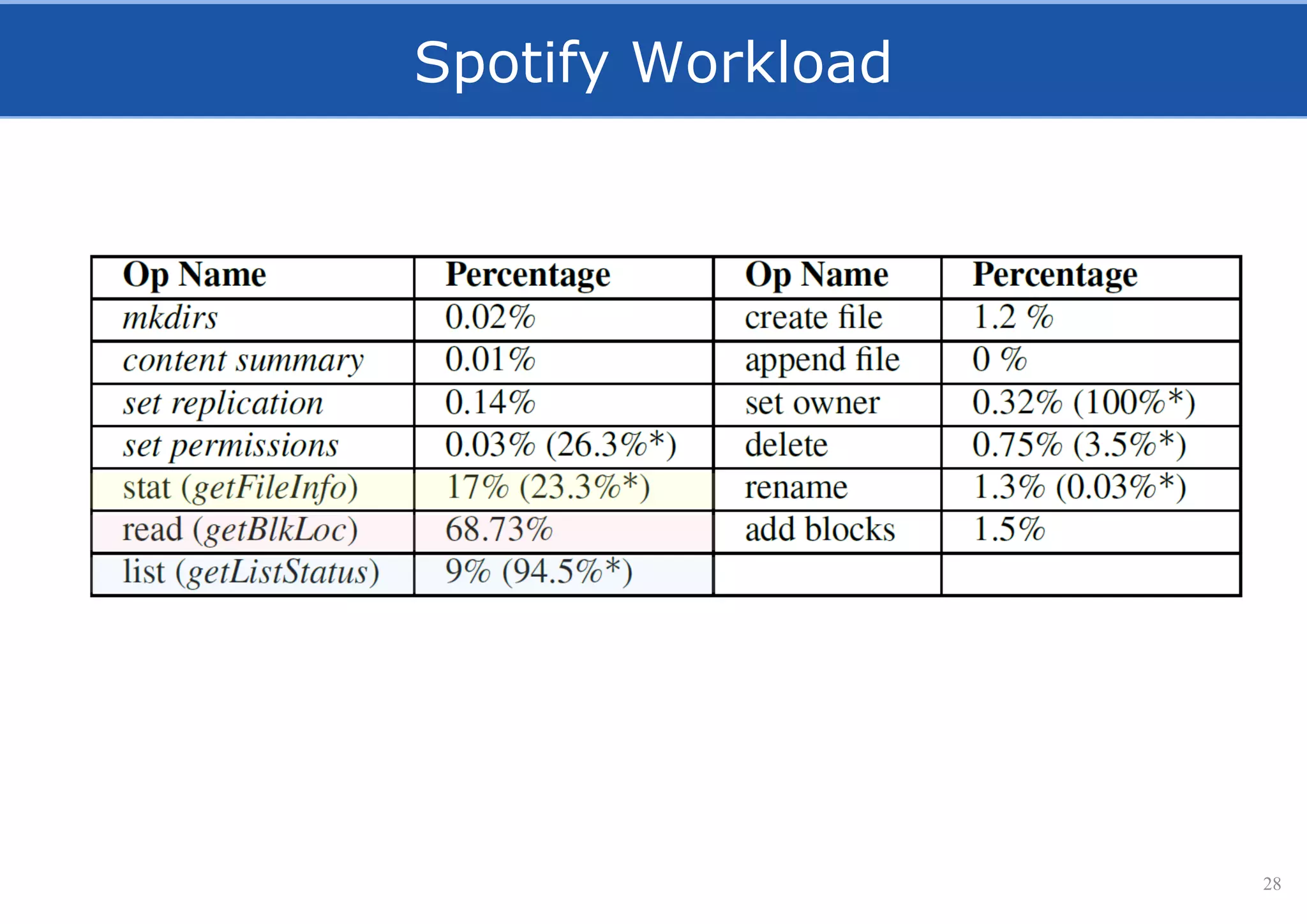
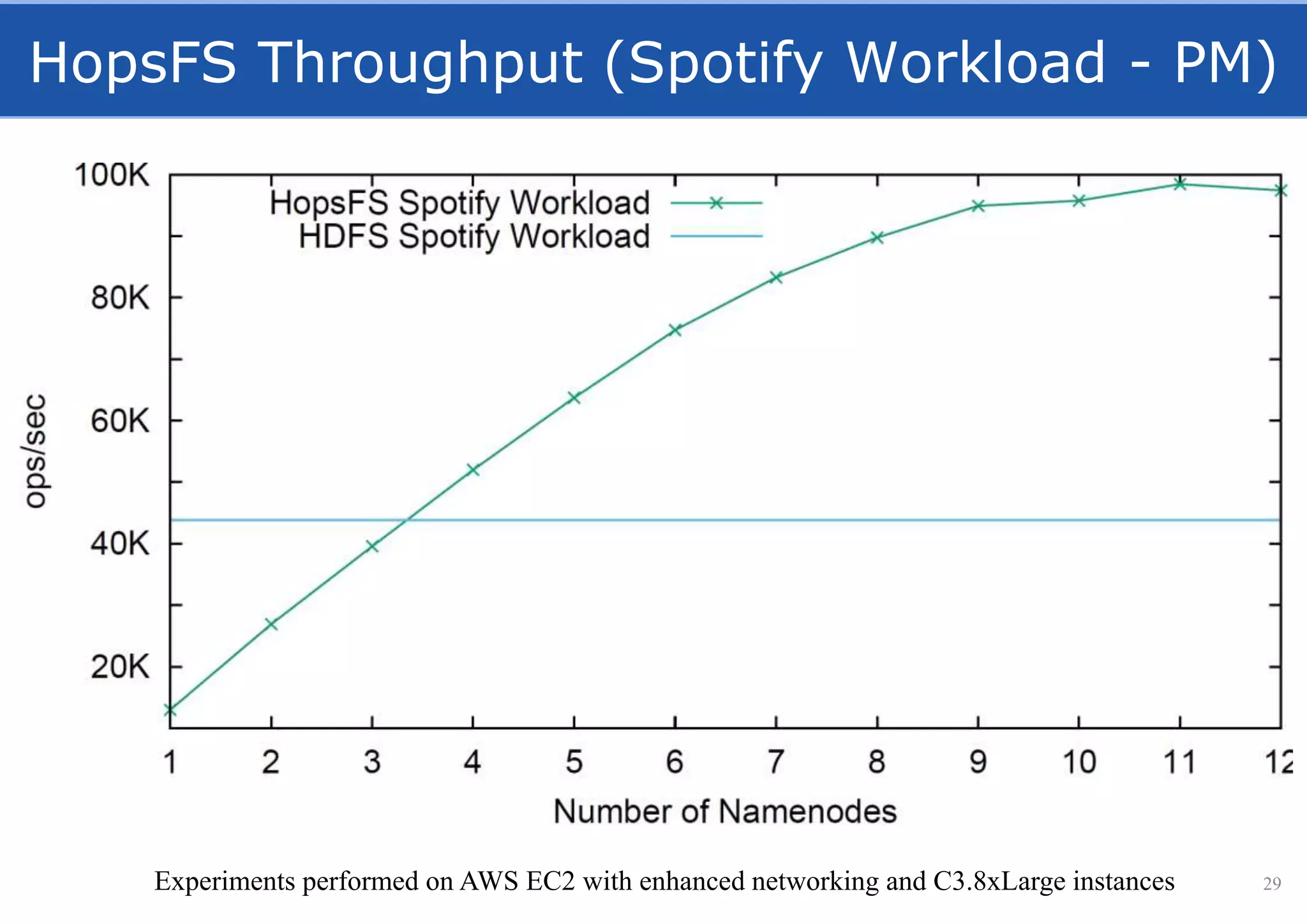
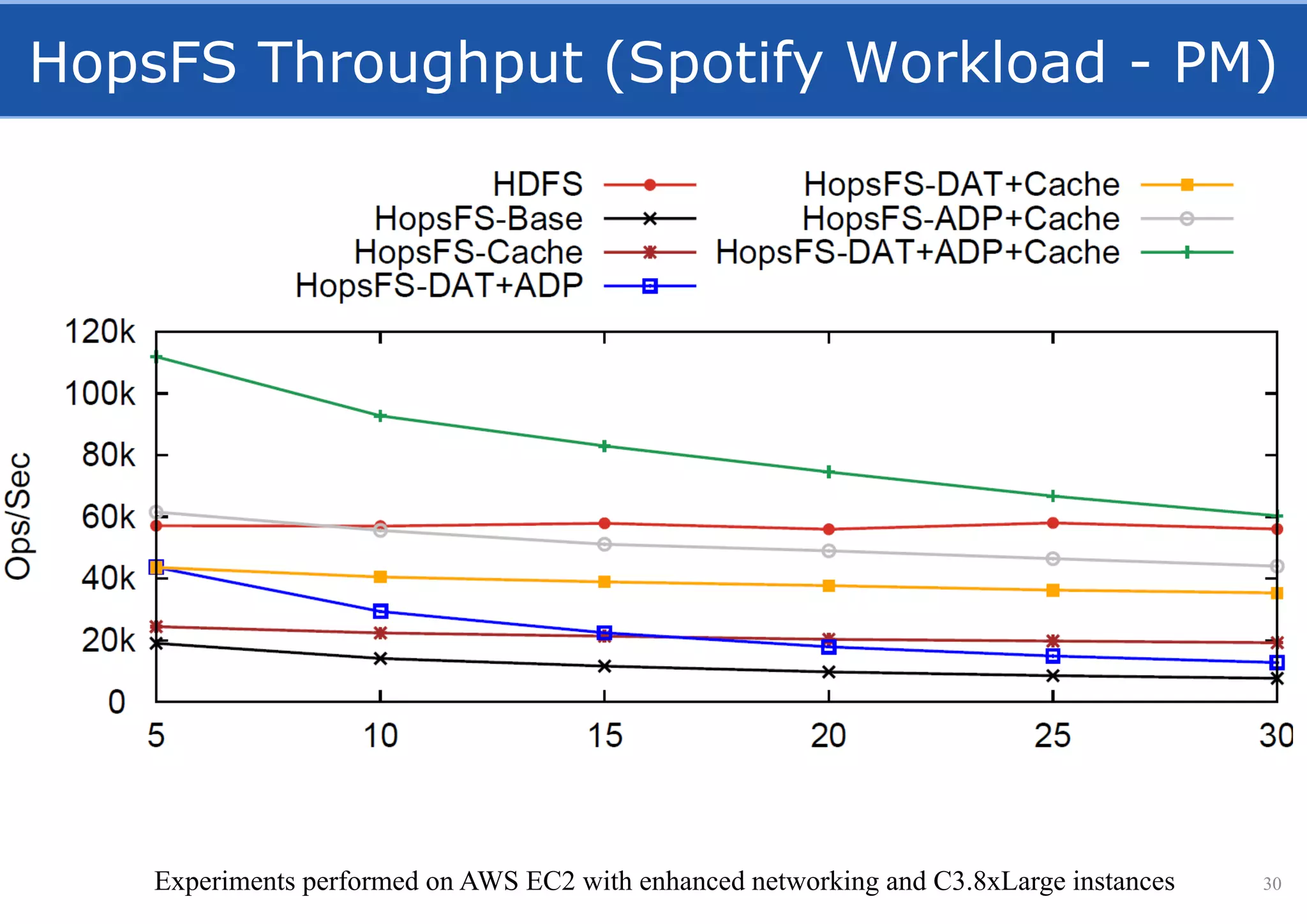
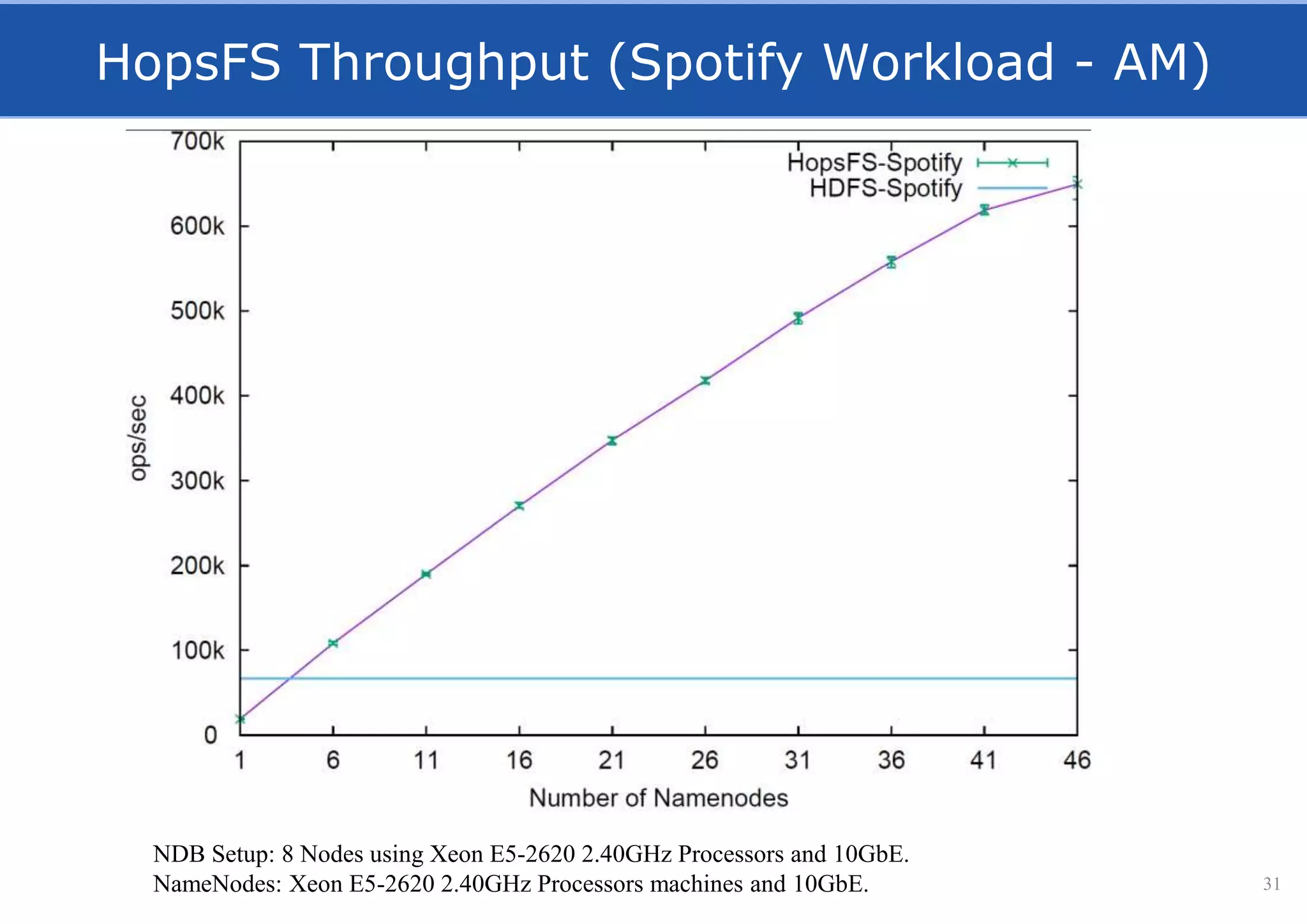
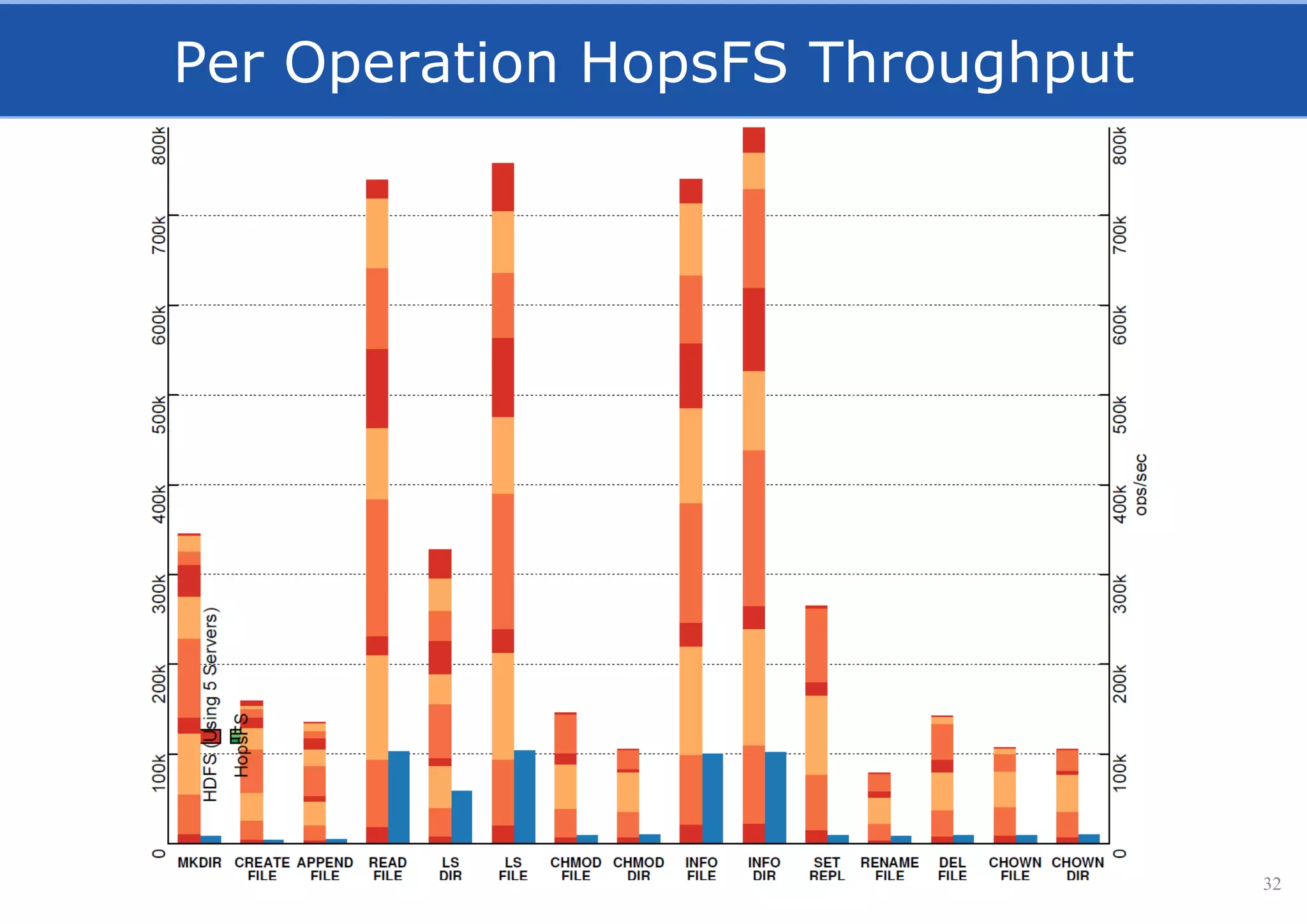
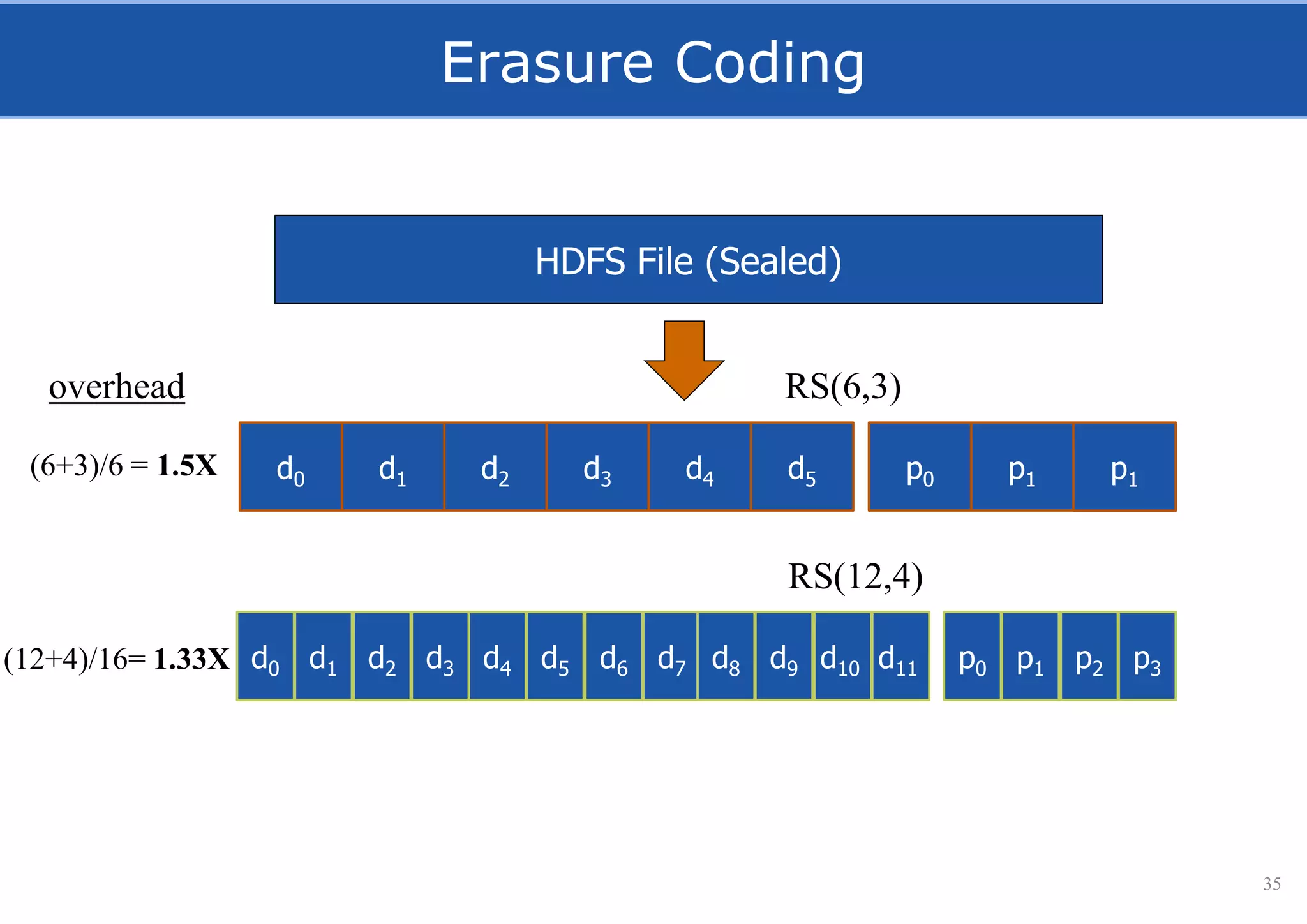
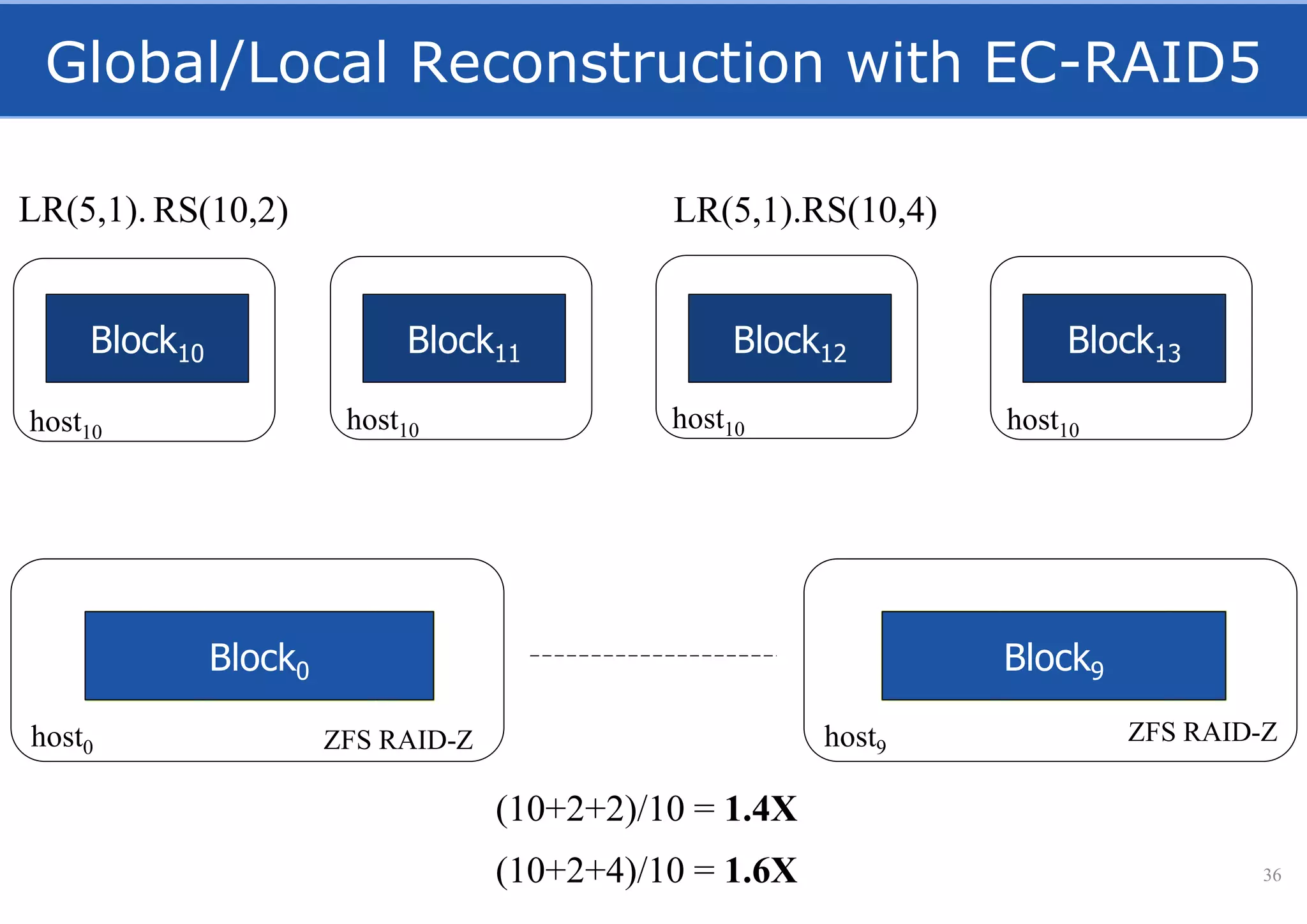
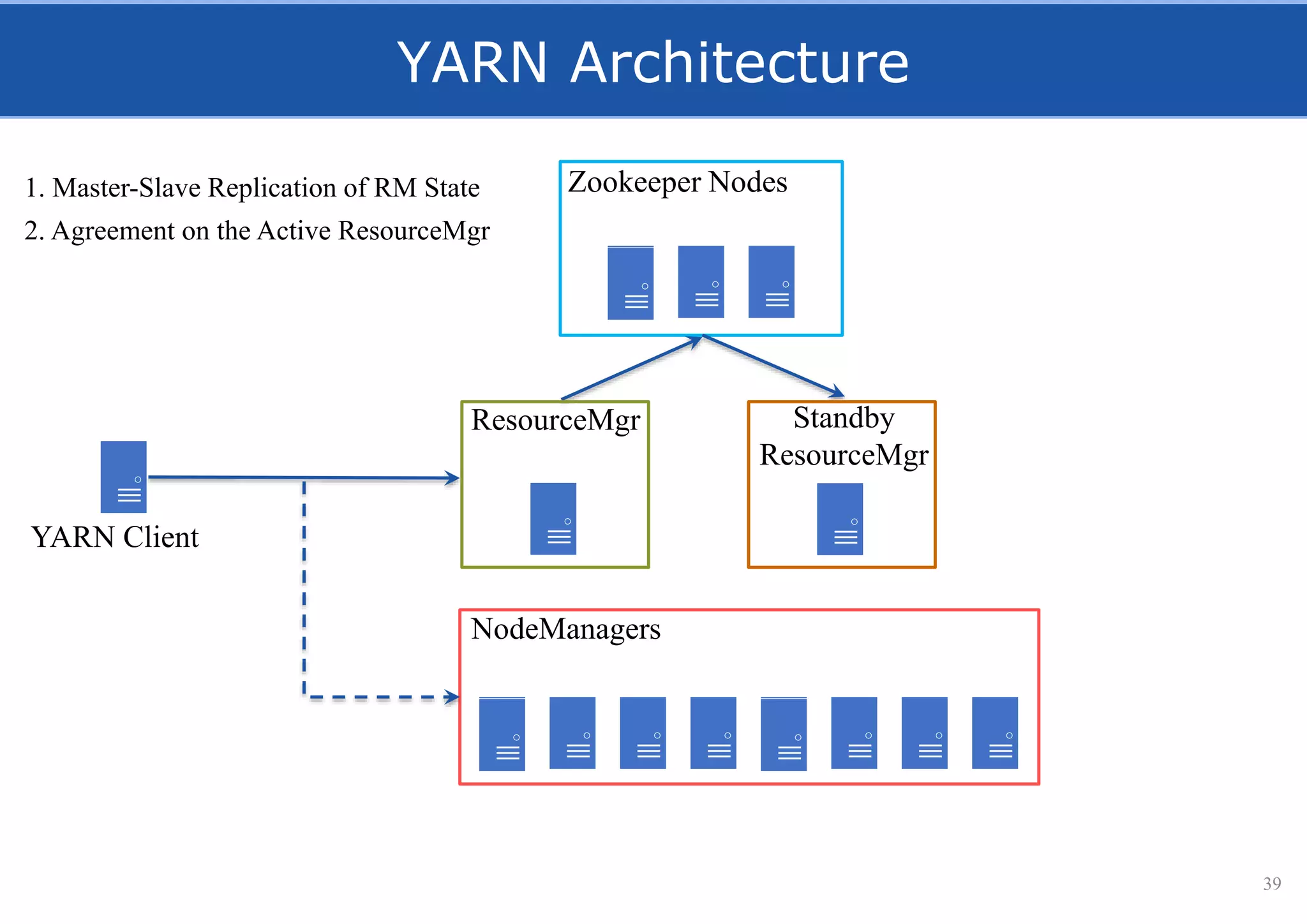
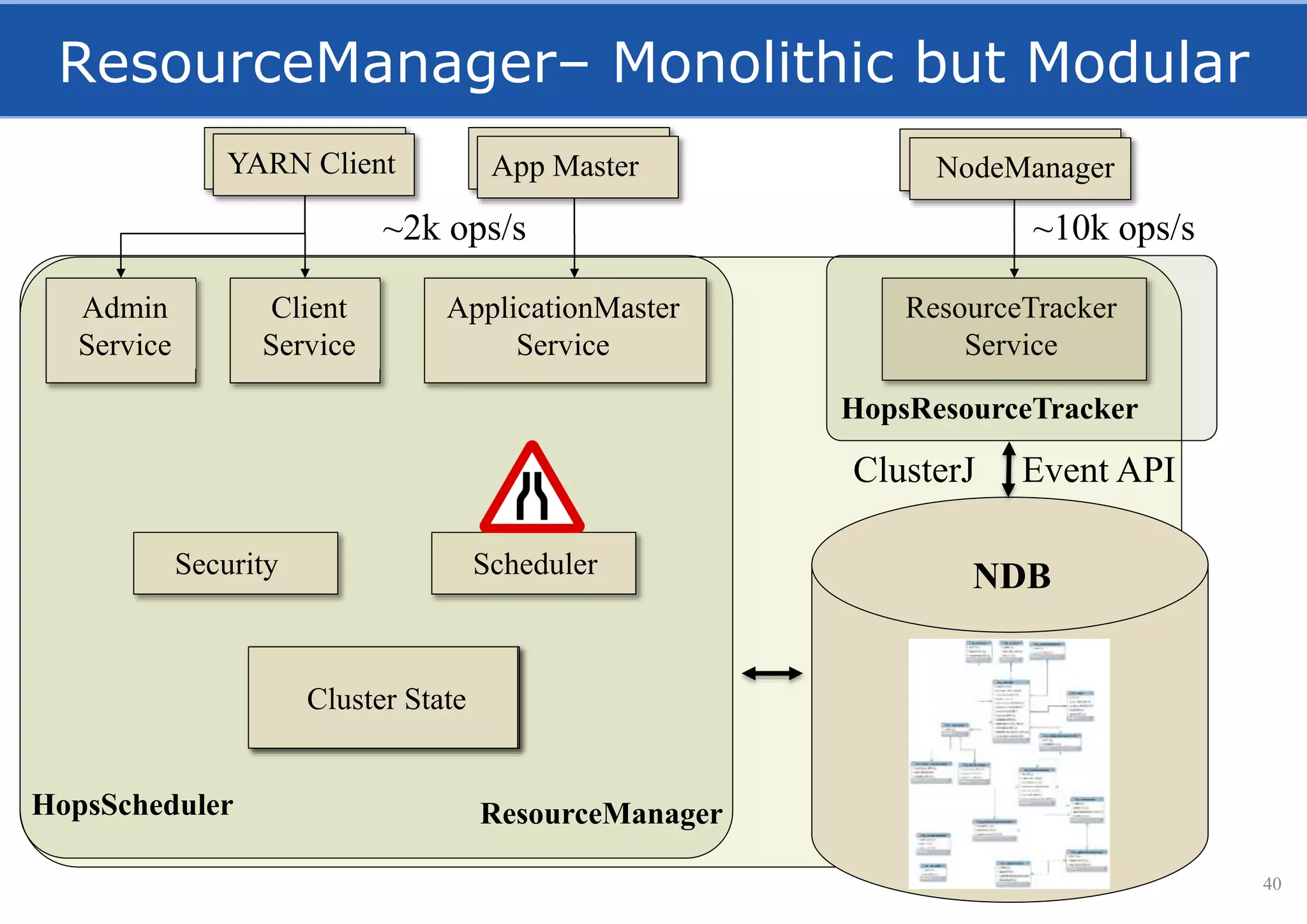
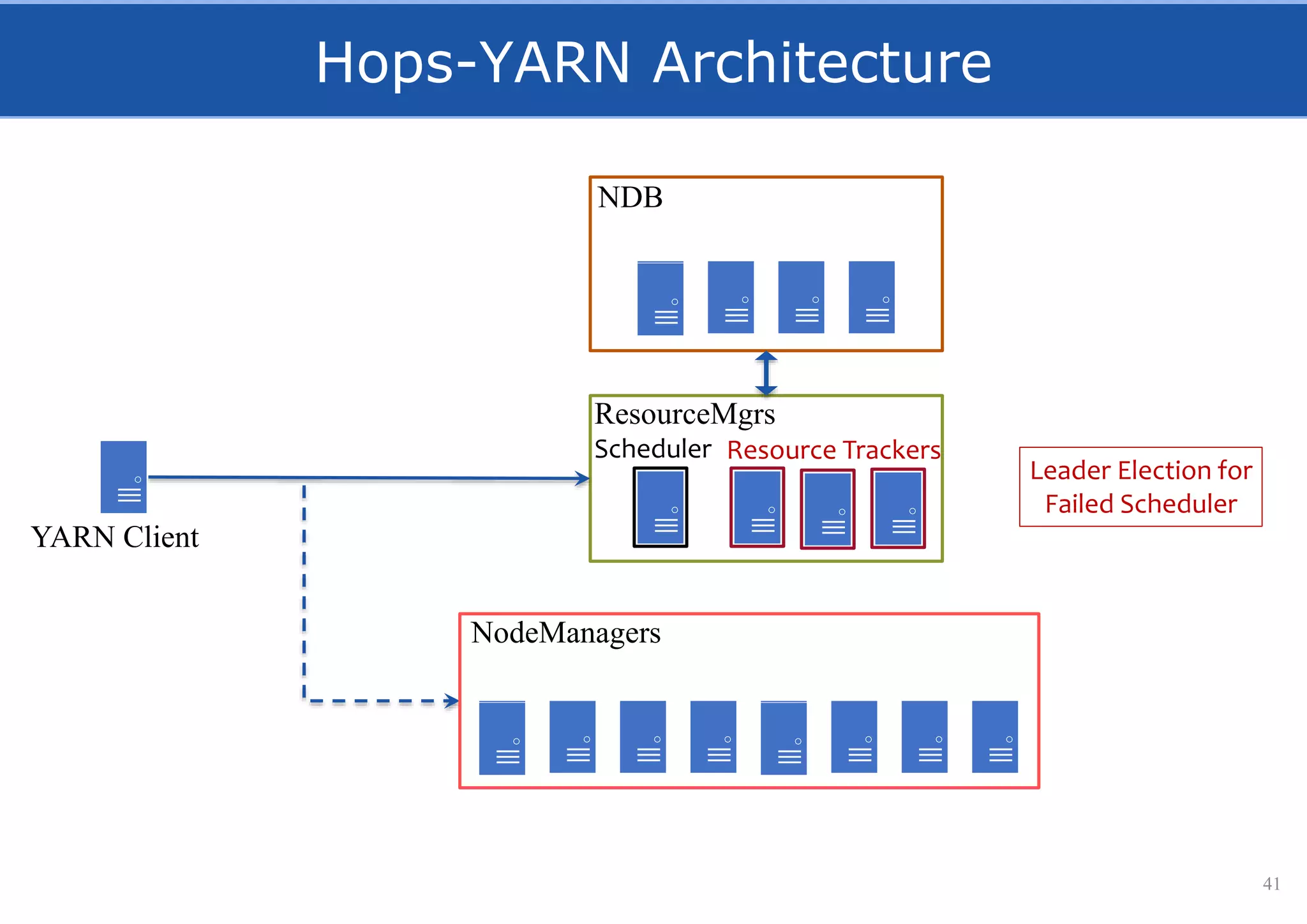
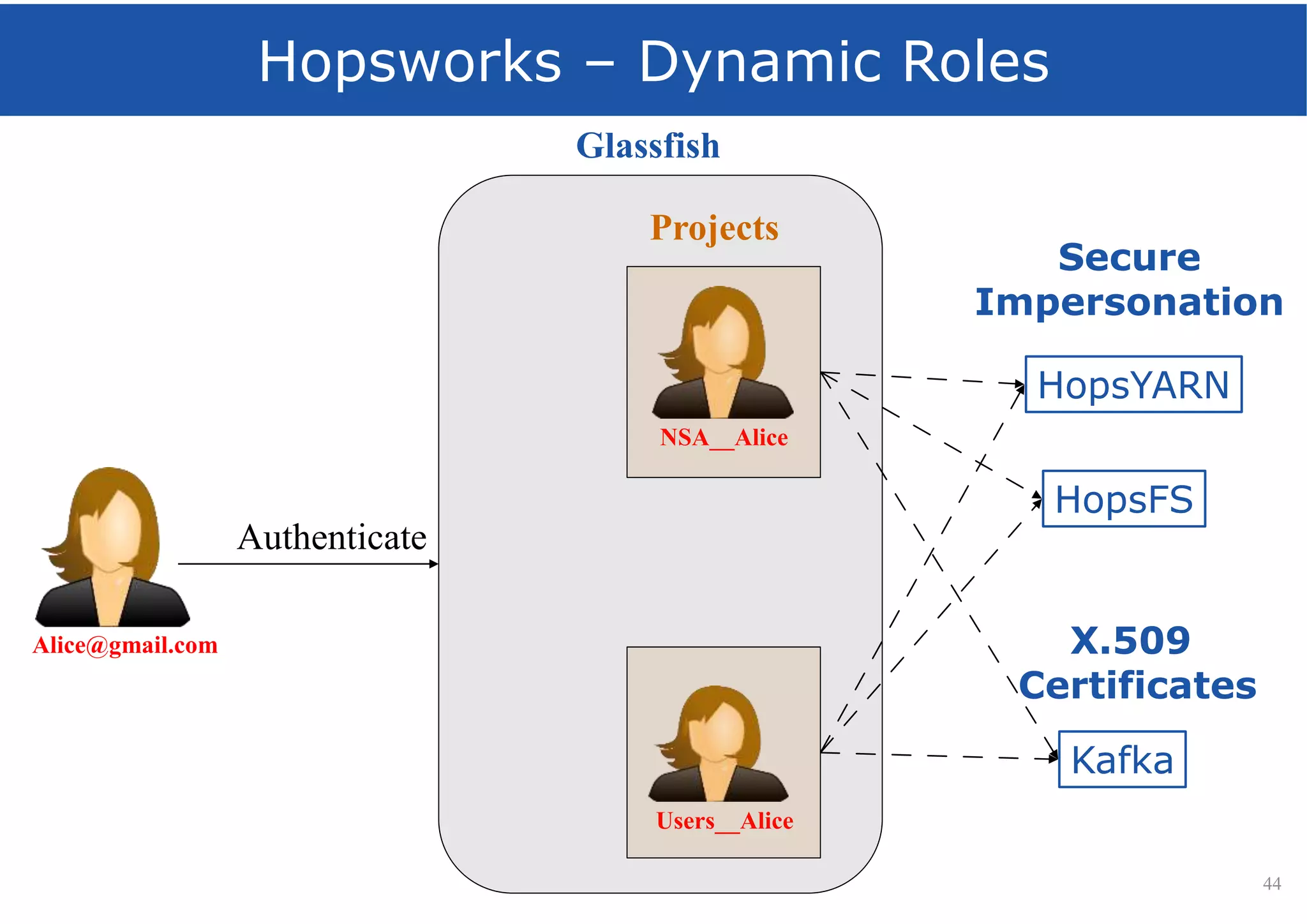
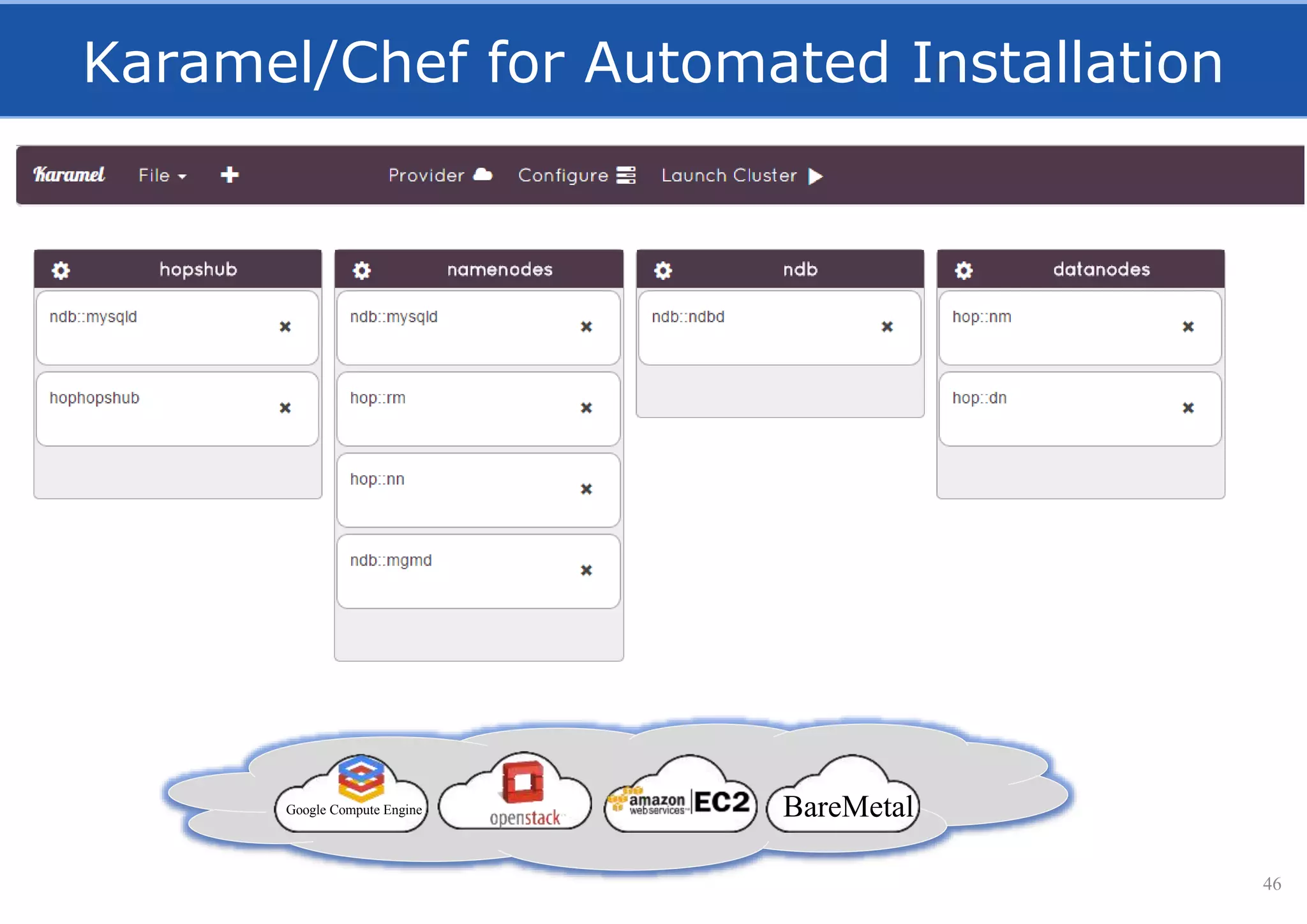
HopsFS provides a 10x performance increase over HDFS by externalizing the HDFS NameNode metadata state to NDB, a NewSQL in-memory database. This allows the NameNode to scale beyond a single server by distributing the metadata across the NDB cluster. HopsFS also leverages implicit locking, path component caching, and heterogeneous storage including erasure coding to further optimize performance. Hops-YARN similarly improves YARN scalability by storing the ResourceManager state in NDB.




































































![ARVC and flecainide case report[EI] Jim.docx.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/finalarvcandflecainidecasereporteijim-230918192356-cebc27e5-thumbnail.jpg?width=640&height=640&fit=bounds)






































