Download as PDF, PPTX
















![Example : Displaying files from a Hadoop filesystemon standard output
public class URLCat{
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws Exception {
InputStreamin = null;
try {
in = new URL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}](https://image.slidesharecdn.com/04-datamanagement-141206231345-conversion-gate01/85/Hadoop-data-management-20-320.jpg)

![Example : Displaying files with FileSystemAPI
public class FileSystemCat{
public static void main(String[] args) throws Exception {
String uri= args[0];
Configuration conf = new Configuration();
FileSystemfs= FileSystem.get(URI.create(uri), conf);
InputStreamin = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}](https://image.slidesharecdn.com/04-datamanagement-141206231345-conversion-gate01/85/Hadoop-data-management-22-320.jpg)
![FSDataInputStream
•The open() method on FileSystemactually returns a FSDataInputStreamrather than a standard java.io class.
•This class is a specialization of java.io.DataInputStreamwith support for random access, so you can read from any part of the stream.
package org.apache.hadoop.fs;
public class FSDataInputStreamextends DataInputStream
implements Seekable, PositionedReadable{
// implementation
}
public interface Seekable{
void seek(long pos) throws IOException;
long getPos() throws IOException;
}
public interface PositionedReadable{
public intread(long position, byte[] buffer, intoffset, intlength) throws IOException;
public void readFully(long position, byte[] buffer, intoffset, intlength) throws IOException;
public void readFully(long position, byte[] buffer) throws IOException;
}](https://image.slidesharecdn.com/04-datamanagement-141206231345-conversion-gate01/85/Hadoop-data-management-23-320.jpg)

![Example: Copying a local file to a Hadoop filesystem
public class FileCopyWithProgress{
public static void main(String[] args) throws Exception {
String localSrc= args[0];
String dst= args[1];
InputStreamin = new BufferedInputStream(new FileInputStream(localSrc));
Configuration conf = new Configuration();
FileSystemfs= FileSystem.get(URI.create(dst), conf);
OutputStreamout = fs.create(new Path(dst), new Progressable() {
public void progress() {
System.out.print(".");
}
});
IOUtils.copyBytes(in, out, 4096, true);
}
}](https://image.slidesharecdn.com/04-datamanagement-141206231345-conversion-gate01/85/Hadoop-data-management-25-320.jpg)



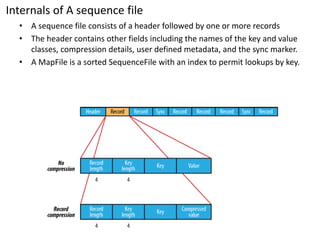








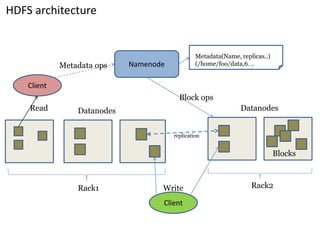
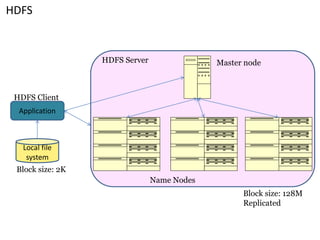
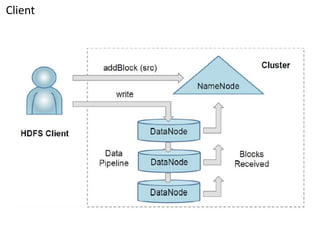
This document summarizes key aspects of the Hadoop Distributed File System (HDFS). HDFS is designed for storing very large files across commodity hardware. It uses a master/slave architecture with a single NameNode that manages file system metadata and multiple DataNodes that store application data. HDFS allows for streaming access to this distributed data and can provide higher throughput than a single high-end server by parallelizing reads across nodes.


































































































