














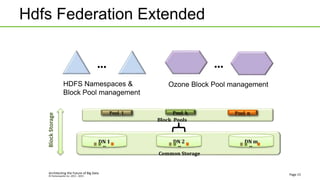





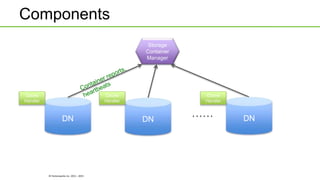

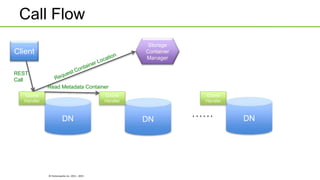
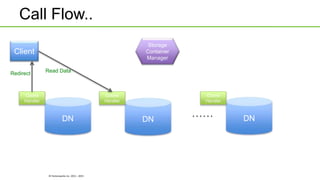

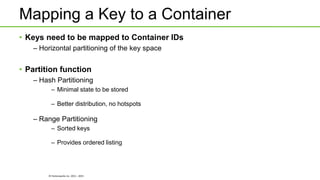

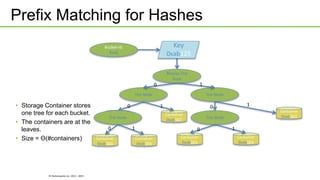

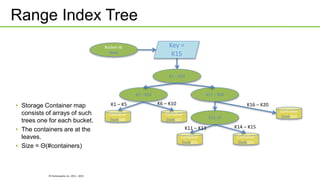











Ozone is an object store that can be built into HDFS to provide highly scalable object storage capabilities. It uses a hashing algorithm to map object keys to storage containers, which are then distributed across data nodes similarly to HDFS blocks. The storage containers are managed by a storage container manager that maintains metadata about container locations and performs functions like replication. This allows Ozone to provide secure, reliable storage of trillions of objects with a wide range of sizes.






















































































